论文解读( FGSM)《Adversarial training methods for semi-supervised text classification》
论文信息
论文标题:Adversarial training methods for semi-supervised text classification
论文作者:Taekyung Kim
论文来源:ICLR 2017
论文地址:download
论文代码:download
视屏讲解:click
1 背景
1.1 对抗性实例(Adversarial examples)
- 通过对输入进行小扰动创建的实例,可显著增加机器学习模型所引起的损失
- 对抗性实例的存在暴露了机器学习模型的脆弱性和局限性,也对安全敏感的应用场景带来了潜在的威胁;

1.2 对抗性训练
训练模型正确分类未修改示例和对抗性示例的过程,使分类器对扰动具有鲁棒性
目的:
- 正则化手段,提升模型的性能(分类准确率),防止过拟合
- 产生对抗样本,攻击深度学习模型,产生错误结果(错误分类)
- 让上述的对抗样本参与的训练过程中,提升对对抗样本的防御能力,具有更好的泛化能力
- 利用 GAN 来进行自然语言生成 有监督问题中通过标签将对抗性扰动设置为最大化
1.3 虚拟对抗性训练
将对抗性训练扩展到半监督/无标记情况
使模型在某实例和其对抗性扰动上产生相同的输出分布
2 方法
2.1 整体框架

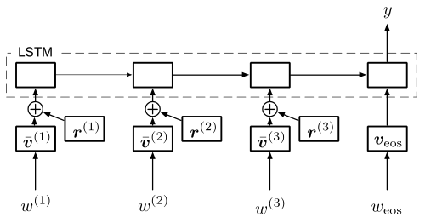
基本思想:扩展对抗性训练/虚拟对抗性训练至文本分类任务和序列模型
基本思路:
- 对于文本分类任务,由于输入是离散的,且常表示为高维one-hot向量,不允许无穷小的扰动,因此将扰动施加于词嵌入中;由于受干扰的嵌入不能映射至某个单词,本文中训练策略仅作为通过稳定分类函数来正则化文本分类器的方法,不能防御恶意扰动;
- 施加扰动于规范化的词嵌入中,设置对抗性损失/虚拟对抗性损失,增强模型分类的鲁棒性;
2.2 方法介绍
将离散单词输入转化为连续向量,定义单词嵌入矩阵:
$\mathbb{R}^{(K+1) \times D}$
其中 $K$ 指代单词数量,第 $K+1$ 个单词嵌入作为序列 结束($eos$)令牌
设置对应时间步长的离散单词为 $w^{(t)}$ ,单词嵌入为 $v^{(t)}$
针对文本分类问题使用 LSTM 模型或双向 LSTM 模型 由于扰动为有界范数,模型在对抗性训练过程中可能 通过 “学习具有较大范数的嵌入使扰动变得不重要” 的病态解决方案,因此需将嵌入进行规范化:
$\overline{\boldsymbol{v}}_{k}=\frac{\boldsymbol{v}_{k}-\mathrm{E}(\boldsymbol{v})}{\sqrt{\operatorname{Var}(\boldsymbol{v})}} \text { where } \mathrm{E}(\boldsymbol{v})=\sum_{j=1}^{K} f_{j} \boldsymbol{v}_{j}, \operatorname{Var}(\boldsymbol{v})=\sum_{j=1}^{K} f_{j}\left(\boldsymbol{v}_{j}-\mathrm{E}(\boldsymbol{v})\right)^{2}$
其中 $f_{i}$ 表示第 $i$ 个单词的频率,在所有训练示例中进行计算。
2.2.1 对抗性训练
对抗性训练尝试提高分类器对小的、近似最坏情况扰动的鲁棒性——使分类器预测误差最大
代价函数:
$-\log p\left(y \mid \boldsymbol{x}+\boldsymbol{r}_{\mathrm{zd} v} ; \boldsymbol{\theta}\right) \text { where } \boldsymbol{r}_{\mathrm{ud} v}-\underset{\boldsymbol{r}, \mid \boldsymbol{r} \| \leq \epsilon}{\arg \min } \log p(y \mid \boldsymbol{x}+\boldsymbol{r} ; \hat{\boldsymbol{\theta}})$
其中 $r$ 为扰动, $\widehat{\theta}$ 为分类器当前参数的常数集,即表明构造对抗性实例的过程中不应该进行反向传播修改参数
对抗性扰动 $r$ 的生成:通过线性逼近得到
$\boldsymbol{r}_{\mathrm{adv}}=-\epsilon \boldsymbol{g} /\|\boldsymbol{g}\|_{2} \text { where } \boldsymbol{g}=\nabla_{\boldsymbol{x}} \log p(y \mid \boldsymbol{x} ; \hat{\boldsymbol{\theta}})$
2.2.2 虚拟对抗性训练
将对抗性训练应用于半监督学习——使分类器预测的输出分布差距最大
额外代价:
$\begin{array}{l}\operatorname{KL}\left[p(\cdot \mid \boldsymbol{x} ; \hat{\boldsymbol{\theta}}) \mid p\left(\cdot \mid \boldsymbol{x}+\boldsymbol{r}_{\mathrm{v} \text {-adv }} ; \boldsymbol{\theta}\right)\right] \\\text { where } \boldsymbol{r}_{\mathrm{v} \text {-adv }}=\underset{\boldsymbol{r},\|\boldsymbol{r}\| \leq \ell}{\arg \max } \mathrm{KL}[p(\cdot \mid \boldsymbol{x} ; \hat{\boldsymbol{\theta}}) \| p(\cdot \mid \boldsymbol{x}+\boldsymbol{r} ; \hat{\boldsymbol{\theta}})]\end{array}$
对抗性扰动设置:
$\boldsymbol{r}_{\mathrm{adv}}=-\epsilon \boldsymbol{g} /\|\boldsymbol{g}\|_{2} \text { where } \boldsymbol{g}=\nabla_{\boldsymbol{s}} \log p(y \mid \boldsymbol{s} ; \hat{\boldsymbol{\theta}})$
对抗性损失:
$L_{\mathrm{adv}}(\boldsymbol{\theta})=-\frac{1}{N} \sum_{n=1}^{N} \log p\left(y_{n} \mid \boldsymbol{s}_{n}+\boldsymbol{r}_{\mathrm{adv}, n} ; \boldsymbol{\theta}\right)$
其中 $N$ 为标记样本的数量
虚拟对抗性扰动设置:
$\boldsymbol{r}_{\mathrm{v} \text {-adv }}=\epsilon \boldsymbol{g} /\|\boldsymbol{g}\|_{2} \text { where } \boldsymbol{g}=\nabla_{\boldsymbol{s}+\boldsymbol{d}} \mathrm{KL}[p(\cdot \mid \boldsymbol{s} ; \hat{\boldsymbol{\theta}}) \mid p(\cdot \mid \boldsymbol{s}+\boldsymbol{d} ; \hat{\boldsymbol{\theta}})]$
其中 $d$ 为小随机向量,实际通过有限差分法和幂迭代计算虚拟对抗性扰动
虚拟对抗性训练损失:
$L_{\mathrm{V} \text {-adv }}(\boldsymbol{\theta})=\frac{1}{N^{\prime}} \sum_{n^{\prime}=1}^{N^{\prime}} \mathrm{KL}\left[p\left(\cdot \mid \boldsymbol{s}_{n^{\prime}} ; \hat{\boldsymbol{\theta}}\right) \mid p\left(\cdot \mid \boldsymbol{s}_{n^{\prime}}+\boldsymbol{r}_{\mathrm{v}-\mathrm{ndv}, n^{\prime}} ; \boldsymbol{\theta}\right)\right]$
其中 $N$ 为标记/未标记样本的数量之和
3 总结
略
4 其他
- 基于梯度的攻击: FGSM(Fast Gradient Sign Method) PGD(Project Gradient Descent) MIM(Momentum Iterative Method)
- 基于优化的攻击: CW(Carlini-Wagner Attack)
- 基于决策面的攻击: DEEPFOOL
论文解读( FGSM)《Adversarial training methods for semi-supervised text classification》的更多相关文章
- 论文解读(ARVGA)《Learning Graph Embedding with Adversarial Training Methods》
论文信息 论文标题:Learning Graph Embedding with Adversarial Training Methods论文作者:Shirui Pan, Ruiqi Hu, Sai-f ...
- 论文阅读:《Bag of Tricks for Efficient Text Classification》
论文阅读:<Bag of Tricks for Efficient Text Classification> 2018-04-25 11:22:29 卓寿杰_SoulJoy 阅读数 954 ...
- 论文解读(ClusterSCL)《ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs》
论文信息 论文标题:ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs论文作者:Yanling Wang, Jing ...
- 论文笔记 - Noisy Channel Language Model Prompting for Few-Shot Text Classification
Direct && Noise Channel 进一步把语言模型推理的模式分为了: 直推模式(Direct): 噪声通道模式(Noise channel). 直观来看: Direct ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- 《C-RNN-GAN: Continuous recurrent neural networks with adversarial training》论文笔记
出处:arXiv: Artificial Intelligence, 2016(一年了还没中吗?) Motivation 使用GAN+RNN来处理continuous sequential data, ...
- CVPR2020论文解读:CNN合成的图片鉴别
CVPR2020论文解读:CNN合成的图片鉴别 <CNN-generated images are surprisingly easy to spot... for now> 论文链接:h ...
- 论文解读(BYOL)《Bootstrap Your Own Latent A New Approach to Self-Supervised Learning》
论文标题:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning 论文方向:图像领域 论文来源:NIPS2020 论文 ...
- 论文解读第三代GCN《 Deep Embedding for CUnsupervisedlustering Analysis》
Paper Information Titlel:<Semi-Supervised Classification with Graph Convolutional Networks>Aut ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
随机推荐
- Linux_Shell脚本
Shell脚本 shell基础 shell变量 shell扩展 shell基础 shell简介 1.什么是shell? shell是一种命令解释器 shell也是一种编程语言 shell,python ...
- dos的使用
打开cmd的方式 开始+系统+命令提示符 win+r,输入cmd 在任意的文件夹下面,按住shift键+鼠标右键点击,在此处打开命令运行窗口 打开我的电脑 在资源管理器的地址栏前面加上cmd路径 常用 ...
- applicationContext使用注解代替
创建一个类SpringConfig @Configuration//证明这个类是spring的配置文件类 @ComponentScan("com.itheima")//扫描的哪些包 ...
- springmvc拦截器的简单创建
找到前端控制器配置文件: 配置拦截器: 实现接口,定义自己的规则:
- Android 自定义SeekBar (一)
一.前言 巩固自定义view基础用,本次尝试构建一个拖动条组件.代码参考于 https://github.com/woxingxiao/BubbleSeekBar ,精简其中高度可重用的部分,仅保留基 ...
- Flink学习系列——简介
Flink起源 德国柏林 Flink的目标 低延迟 高吞吐 较高的准确性(乱序数据的处理) 良好的容错性(容错性差的表现:一个节点挂了,全部回滚重新做计算,这对实时性要求高的场景非常致命)
- StatefulSet 模板,更新,扩缩容,删除
概念: StatefulSet是用来管理有状态应用的工作负载API对象,kubectl 中可以简写sts ,sts每一个pod生成一个唯一的标识符,sts_name-number,number从0开始 ...
- Ubuntu 22.04 安装 VMWare 16.2.3 后无法启动
异常日志: 2022-06-13T03:49:56.019Z In(05) host-29676 In file included from /tmp/modconfig-XR2GVI/vmmon-o ...
- (转载)一篇文章详解python的字符编码问题
一篇文章详解python的字符编码问题 一:什么是编码 将明文转换为计算机可以识别的编码文本称为"编码".反之从计算机可识别的编码文本转回为明文为"解码". ...
- Hadoop-HA节点介绍
设计思想 hadoop2.x启用了主备节点切换模式(1主1备) 当主节点出现异常的时候,集群直接将备用节点切换成主节点 要求备用节点马上就要工作 主备节点内存几乎同步 有独立的线程对主备节点进行监控健 ...