09 Hive安装与操作
一.安装Hive
- 下载解压重命名权限
- 配置环境变量

- 修改Hive配置文件
修改
/usr/local/hive/conf下的hive-site.xml123456789101112131415161718192021222324<?xmlversion="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheettype="text/xsl" href="configuration.xsl"?><configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value><description>username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>hive</value><description>password to use against metastore database</description></property></configuration> - 配置mysql驱动
- 下载合适版本的mysql jar包,拷贝到/usr/local/hive/lib目录下
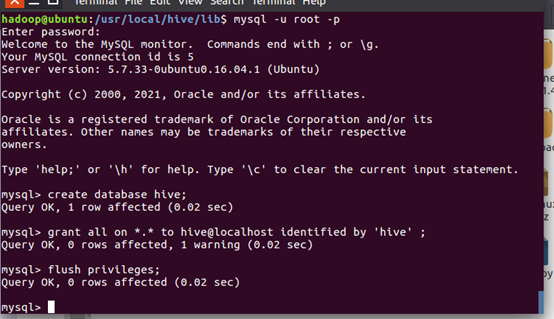
- 在mysql新建hive数据库
- 配置mysql允许hive接入
- 启停
- 启动Hadoop--启动Hive--退出Hive--停止Hadoop

二、Hive操作
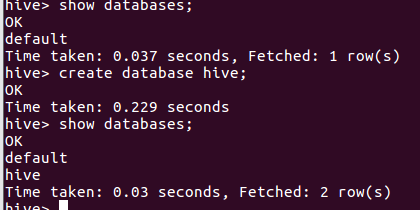
- hive创建与查看数据库
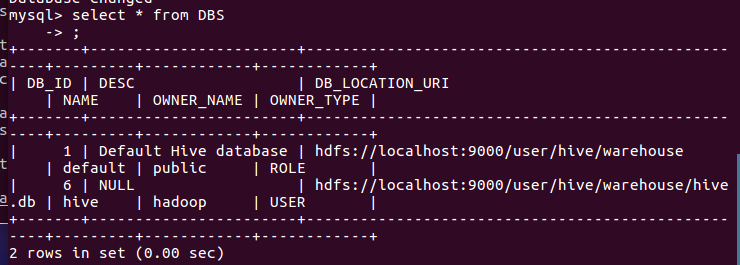
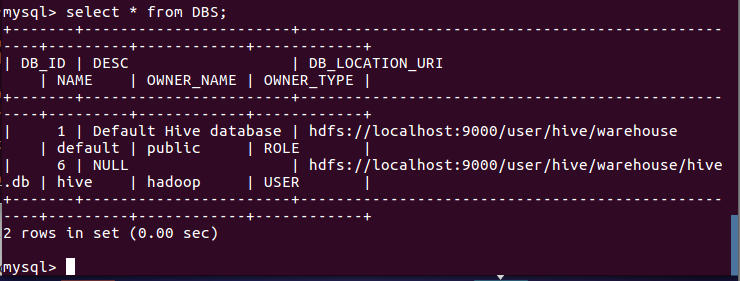
- mysql查看hive元数据表DBS
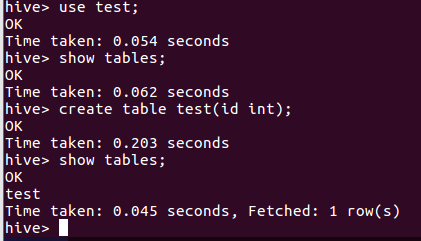
- hive创建与查看表
- mysql查看hive元数据表TBLS

- hdfs查看表文件位置


- hive删除表
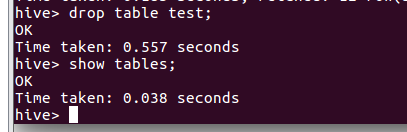
- mysql查看hive元数据表TBLS

- hive删除数据库
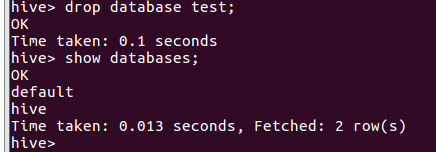
- mysql查看hive元数据表DBS
三、hive进行词频统计
- 准备txt文件
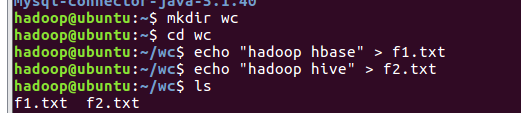
- 启动hadoop,启动hive
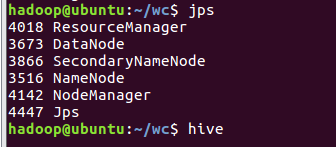
- 创建并查看文本表 create table
- 导入文件的数据到文本表中 load data local inpath

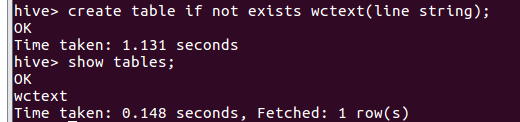
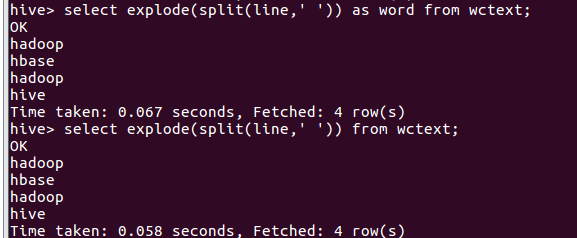
- 分割文本 split

- 行转列explode
- 统计词频group by


准备txt文件

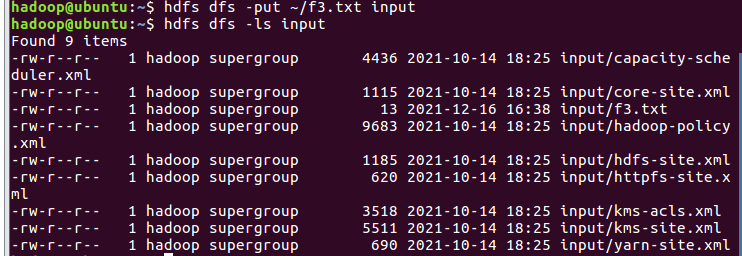
上传文件至hdfs
从hdfs导入文件内容到表wctext, 并查看hdfs源文件,hfds数据库文件
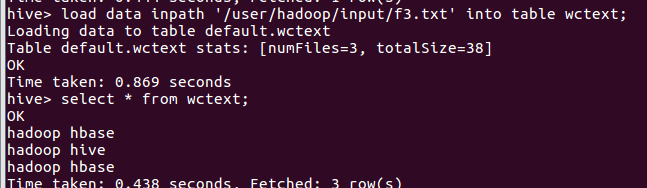
统计词频

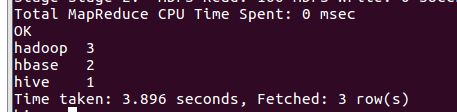
词频统计结果存到数据表里,并查看表和文件

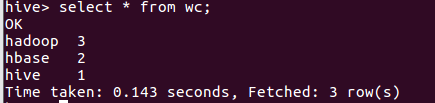
本地调用本地hql文件进行词频统计,将结果保存为本地文件



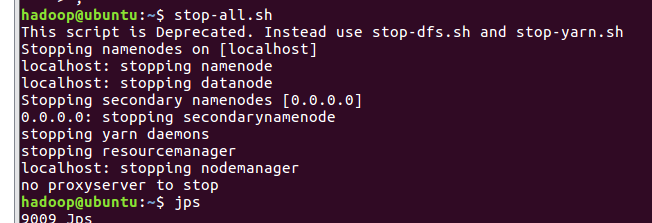
退出hive,停止hadoop
- hive创建与查看数据库
- 启动Hadoop--启动Hive--退出Hive--停止Hadoop
09 Hive安装与操作的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive安装
实验目的 了解hive的原理和安装方式 学习使用MySQL数据库 使用hive进行基本操作 实验原理 1.Hive Hive是一个数据仓库技术,包括解释器.编译器.优化器,一次将一个sql语句装化为m ...
- Hive 安装操作
本篇为安装篇较简单: 前提:1: 安装了hadoop-1.0.4(1.0.3也可以)正常运行2:安装了hbase-0.94.3, 正常运行 接下来,安装Hive,基于已经安装好的hadoop,步骤如下 ...
- hive安装--设置mysql为远端metastore
作业任务:安装Hive,有条件的同学可考虑用mysql作为元数据库安装(有一定难度,可以获得老师极度赞赏),安装完成后做简单SQL操作测试.将安装过程和最后测试成功的界面抓图提交 . 已有的当前虚拟机 ...
- Hive安装与部署集成mysql
前提条件: 1.一台配置好hadoop环境的虚拟机.hadoop环境搭建教程:稍后补充 2.存在hadoop账户.不存在的可以新建hadoop账户安装配置hadoop. 安装教程: 一.Mysql安装 ...
- 【转】 hive安装配置及遇到的问题解决
原文来自: http://blog.csdn.net/songchunhong/article/details/51423823 1.下载Hive安装包apache-hive-1.2.1-bin.ta ...
- macbook hive安装
1 原材料 1.1 已经安装好的伪分布式hadoop,版本2.8.3(参见链接https://www.cnblogs.com/wooluwalker/p/9128859.html) 1.2 apach ...
- Hive安装与配置--- 基于MySQL元数据
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行. 其优点是学习成本低,可以通过 ...
- Hadoop3集群搭建之——hive安装
Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hbase安装及简单操作 现在到 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 【大数据系列】Hive安装及web模式管理
一.什么是Hive Hive是建立在Hadoop基础常的数据仓库基础架构,,它提供了一系列的工具,可以用了进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在Hadoop中的按规模数据的 ...
随机推荐
- element3 form表单校验对象里面有对象的情况
let formSearch = reactive({ queryParam: [ { field: "", //查询的字段 gzcs: "", //规则参数 ...
- centos下安装部署nginx
1.在安装Nginx之前,要确保已经安装了需要的软件:gcc.pcre-devel.zlib-devel.openssl-devel.如果没有安装,执行下面命令. yum -y install gcc ...
- python正则表达式提取数据
re模块, 常用写法 import re def abs_string(): s_string = ' @pytest.mark.Level1@pytest.mark.SmartSharedListd ...
- Vulnhub 靶场 DIGITALWORLD.LOCAL: SNAKEOIL
Vulnhub 靶场 DIGITALWORLD.LOCAL: SNAKEOIL 前期准备 靶机地址:https://www.vulnhub.com/entry/digitalworldlocal-sn ...
- shell特殊符号
符号 含义 ; 命令分隔符 # 配置文件注释: root用户命令终端提示符 ~ 家目录 cd ~ - 上一次所在路径 cd - su - linux切换用户环境 ^ 非 [^abcd] $ ...
- 通过EXCEL/WPS文件,拼接SQL,刷数据库数据
WPS如何把日期变成文本格式? [快捷选择同一列多条记录]同一列,鼠标左键标记A,SHIFT+鼠标左键标记B ,等于选择A-B的之间的数据 [向下填充]在第一行输入数据,选择同一列A-B的之间的数据, ...
- NPOI 导出 EXCEL
1. 2.创建NPOIHelper using System;using System.Collections.Generic;using System.Data;using System.IO;us ...
- bootstrap-treeview手动修改源码添加与后台交互的id
bootstrap-treeview中只有自增的参数data-nodeid,没有id的参数,不方便后台交互,修改源码添加id. 1.图一为添加的自定义的node.Id; 2. 下图为添加的id 3.后 ...
- get 和 post 请求在缓存方面的区别
get 请求类似于查找的过程,用户获取数据,可以不用每次都与数据库连接,所以可以 使用缓存. post 不同,post 做的一般是修改和删除的工作,所以必须与数据库交互,所以不能使用 缓存.因此 ge ...
- kibana启动时报错:Validation Failed: 1: this action would add [2] total shards, but this cluster currently has [999]/[1000] maximum shards open
解决方案: curl -XPUT -H "Content-Type:application/json" -d '{"persistent":{"clu ...