PCA降维笔记
PCA降维笔记
一个非监督的机器学习算法
主要用于数据的降维
通过降维, 可以发现更便 于人类理解的特征
其他应用:可视化;去噪
PCA(Principal Component Analysis)是一种常用的数据分析方法。
PCA通过线性变换,将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
降维思路
原数据:
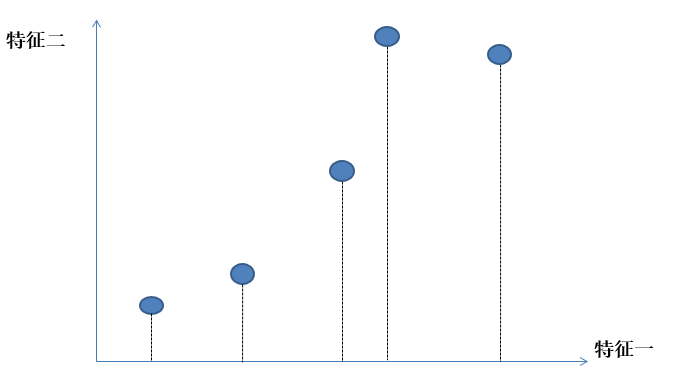

二维数据据降维到一维数:

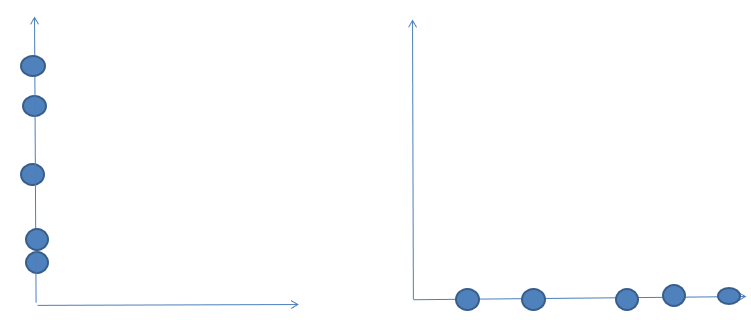
这是去掉特征1和特征2降维后的样子,从图中我们可以感觉到,右边这个比左边这个好一些,因为他们分散的间距比较大,可区分度比较高,这样数据保留的信息也比较多,我们认为这样数据丢失的量就更小一些,达到了我们既 降低了维度,又尽可能多保留信息的目的。
如何找到这个让样本间距最大的轴呢?
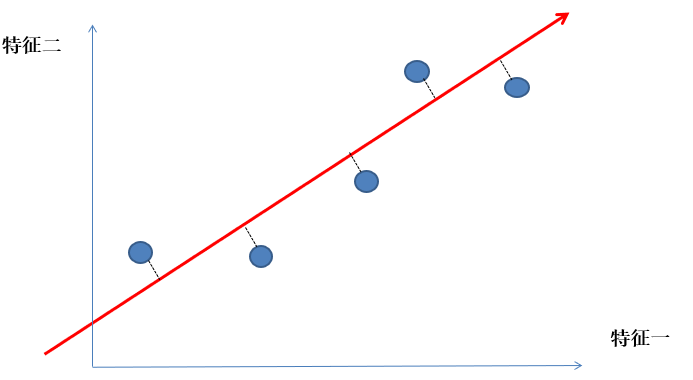

降维推导



随机梯度下降解决降维
第一步将样本均值归零
x = x-x_mean



第二步:求第一主成分的单位向量W=(w1,w2)
我们将所有的样本数据通过投影映射到这个方向向量上得到一个新的向量,我们称作X_pr, 所以我们最后的 目标就是为了求方向向量上所有的 X_pr这个向量的方差最大 如下图:



第三步:梯度上升来最优化这个方差
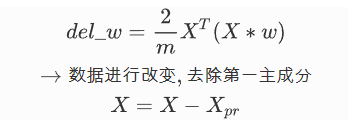
PCA解决降维
降维问题的优化目标
将一组N维向量降为K维(0<K<N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
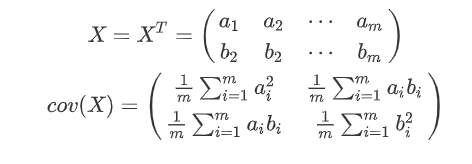
协方差矩阵对角化
前提:

设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:

现在事情很明白了!我们要找的P不是别的,而是能让原始协方差矩阵C对角化的P。
PCA的算法步骤
设有m条n维数据。
将原始数据X进行转置
将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
求出协方差矩阵
求出协方差矩阵的特征值及对应的特征向量
将特征向量按对应特征值大小从上到下按行排列成矩阵取前k行组成矩阵P
Y=PX即为降维到k维后的数据
PCA实例
用PCA的方法将整个二维的数据降到一维

1.将原始数据X进行转置

2.将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值

3.求出协方差矩阵

4.求出协方差矩阵的特征值及对应的特征向量

5.将特征向量按对应特征值大小从上到下按行排列成矩阵取前k行组成矩阵P

6.Y=PX即为降维到k维后的数据

这里可以看到D是一个对角化的矩阵,满足的条件
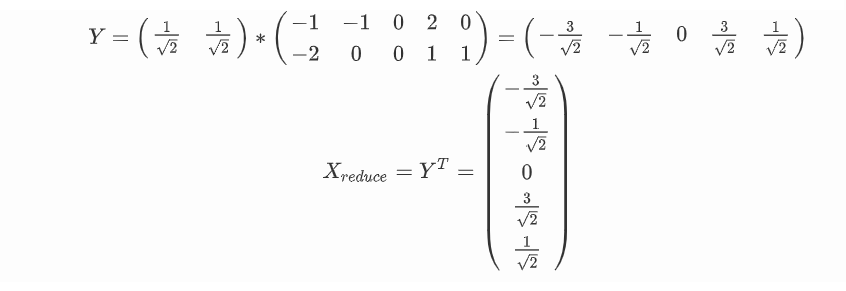
SVD算法解决降维
也就是在PCA的过程中,第三步和第四步改为奇异值分解:
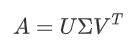

SVD的计算步骤
(1) 对矩阵A和A转置的乘积进行特征值分解

其中v就是右奇异向量.
(2)通过仿真求解左奇异向量

其中奇异值σ跟特征值很类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,其中r<<n,这里定义一下部分奇异值分解:

(3)选择适当的r值,就可以将原数据进行压缩


使用特征值分解实现降维
import numpy as np
def PCA(X, k):
data = X - np.mean(X, axis=0)
# 计算协方差矩阵
cov = np.cov(data.T)
# 计算协方差矩阵的特征值和特征向量
eig_val, eig_vec = np.linalg.eig(cov)
# 将特征值和特征向量组成一个元组
eig_pairs = [(np.abs(eig_val[i]), eig_vec[:, i]) for i in range(data.shape[1])]
# 将特征值和特征向量从大到小排序
eig_pairs.sort(reverse=True)
# #保留最大的K个特征向量
ft = []
for i in range(k):
ft.append(list(eig_pairs[i][1]))
return np.dot(data, np.array(ft).T)
使用SVD分解实现降维
def SVD(data, k=2):
data = data - np.mean(data)
u, s, vt = np.linalg.svd(data)
v_reduce = vt[:k, :].T # 取前k个特征向量
Z = np.dot(data, v_reduce)
return Z
梯度上升实现降维
def GD_PCA(X,n_components, eta=0.01, n_iters=1e4):
# 将均值归零 也就是将坐标轴进行移动
def demean(X):
return X - np.mean(X, axis=0)
# 损失函数(方差)
def f(w, X):
return np.sum((X.dot(w) ** 2)) / len(X)
# 损失函数的导数
# 把w向量变成单位向量 也就是除于自己的模
def direction(w):
return w / np.linalg.norm(w)
# 进行梯度下降
def first_component(X, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8):
# 保证每次的w为单位向量
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = X.T.dot(X.dot(w)) * 2. / len(X)
last_w = w
# 梯度上升
w = w + eta * gradient
# 每一次重新迭代前,需要把w向量变成单位向量
w = direction(w)
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
# 先将整个数据的中心点移动到圆点
X_pca = demean(X)
# 分几类就是几行,然后列数就是特征集合的列数
components_ = np.empty(shape=(n_components, X.shape[1]))
# 分几类,循环几次
for i in range(n_components):
# 此时初始化theta不能为0了
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca, initial_w, eta, n_iters)
components_[i, :] = w
# 把X_pca在w上的分量去除
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return X.dot(components_.T)
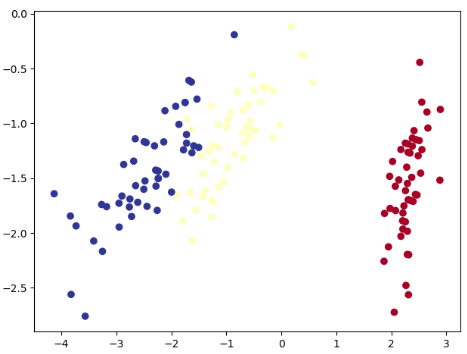
使用鸢尾花实现降维:
PCA降维笔记的更多相关文章
- Python机器学习笔记 使用scikit-learn工具进行PCA降维
之前总结过关于PCA的知识:深入学习主成分分析(PCA)算法原理.这里打算再写一篇笔记,总结一下如何使用scikit-learn工具来进行PCA降维. 在数据处理中,经常会遇到特征维度比样本数量多得多 ...
- 机器学习公开课笔记(8):k-means聚类和PCA降维
K-Means算法 非监督式学习对一组无标签的数据试图发现其内在的结构,主要用途包括: 市场划分(Market Segmentation) 社交网络分析(Social Network Analysis ...
- [学习笔记] numpy次成分分析和PCA降维
存个代码,以后参考. numpy次成分分析和PCA降维 SVD分解做次成分分析 原图: 次成分复原图: 代码: import numpy as np from numpy import linalg ...
- 关于PCA降维中遇到的python问题小结
由于论文需要,开始逐渐的学习CNN关于文本抽取的问题,由于语言功底不好,所以在学习中难免会有很多函数不会用的情况..... ̄へ ̄ 主要是我自己的原因,但是我更多的把语言当成是一个工具,需要的时候查找就 ...
- [综] PCA降维
http://blog.json.tw/using-matlab-implementing-pca-dimension-reduction 設有m筆資料, 每筆資料皆為n維, 如此可將他們視為一個mx ...
- PCA降维—降维后样本维度大小
之前对PCA的原理挺熟悉,但一直没有真正使用过.最近在做降维,实际用到了PCA方法对样本特征进行降维,但在实践过程中遇到了降维后样本维数大小限制问题. MATLAB自带PCA函数:[coeff, sc ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 【资料收集】PCA降维
重点整理: PCA(Principal Components Analysis)即主成分分析,是图像处理中经常用到的降维方法 1.原始数据: 假定数据是二维的 x=[2.5, 0.5, 2.2, 1. ...
- 第四章 PCA降维
目录 1. PCA降维 PCA:主成分分析(Principe conponents Analysis) 2. 维度的概念 一般认为时间的一维,而空间的维度,众说纷纭.霍金认为空间是10维的. 3. 为 ...
随机推荐
- PHP开发高可用高安全App后端☆
第1章 本章先讲解课程所含技术点,并演示相关的项目,让小伙伴对课程有个初步的认知,然后再带领小伙伴进行功能的分析,表的ER总关系图 第2章本章主要讲解课程的一些准备工作知识.包括工具.环境.模板等. ...
- [RK3399] /bin/sh: 1: lz4c: not found
CPU:RK3399 系统:Android 8.1 第一次在 RK3399 编译 Android 8.1 的系统,编译内核过程中报错如下: /bin/sh: : lz4c: not found mak ...
- 阿里巴巴高可用技术专家襄玲:压测环境的设计和搭建 PTS - 襄玲 云栖社区 今天
阿里巴巴高可用技术专家襄玲:压测环境的设计和搭建 PTS - 襄玲 云栖社区 今天
- C++在线编程网站
1.推荐 http://www.dooccn.com/cpp/ 2.https://wandbox.org/ 3.https://www.tutorialspoint.com/compile_cpp_ ...
- 总结解决 Android-Studio 编译耗时(好久、太长)问题
首先通过搜索有关Android-Studio 编译耗时(好久.太长)问题的博客,速度确实有所改善. 一.暂时解决 Android-Studio 编译耗时(好久.太长)问题 本文链接:https://b ...
- C语言 消灭编译警告(Warning)
如何看待编译警告 当编译程序发现程序中某个地方有疑问,可能有问题时就会给出一个警告信息.警告信息可能意味着程序中隐含的大错误,也可能确实没有问题.对于警告的正确处理方式应该是:尽可能地消除之.对于编译 ...
- 38 Flutter仿京东商城项目 渲染结算页面商品数据
加群452892873 下载对应38课文件,运行方法,建好项目,直接替换lib目录 CartServices.dart import 'dart:convert'; import 'Storage.d ...
- 阶段5 3.微服务项目【学成在线】_day16 Spring Security Oauth2_05-SpringSecurityOauth2研究-搭建认证服务器
3 Spring Security Oauth2研究 3.1 目标 本项目认证服务基于Spring Security Oauth2进行构建,并在其基础上作了一些扩展,采用JWT令牌机制,并自定 义了用 ...
- List根据多个字段分组
List<ClassEntity> distinctClass = classEntities.stream().collect(Collectors.collectingAndThen( ...
- 123456---com.twoapp.ErTongNongChangPinTu---儿童农场拼图
com.twoapp.ErTongNongChangPinTu---儿童农场拼图