python selenium 基础框架
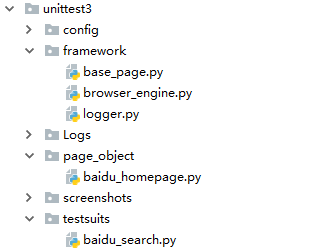
base_page.py
# coding=utf-8
import time
from selenium.common.exceptions import NoSuchElementException
import os.path
from unittest3.framework.logger import Logger # create a logger instance
logger = Logger(logger="BasePage").getlog() class BasePage(object):
"""
定义一个页面基类,让所有页面都继承这个类,封装一些常用的页面操作方法到这个类
""" def __init__(self, driver):
self.driver = driver # quit browser and end testing def quit_browser(self):
self.driver.quit() # 浏览器前进操作 def forward(self):
self.driver.forward()
logger.info("Click forward on current page.") # 浏览器后退操作 def back(self):
self.driver.back()
logger.info("Click back on current page.") # 隐式等待 def wait(self, seconds):
self.driver.implicitly_wait(seconds)
logger.info("wait for %d seconds." % seconds) # 点击关闭当前窗口 def close(self):
try:
self.driver.close()
logger.info("Closing and quit the browser.")
except NameError as e:
logger.error("Failed to quit the browser with %s" % e) # 保存图片 def get_windows_img(self):
"""
在这里我们把file_path这个参数写死,直接保存到我们项目根目录的一个文件夹.\Screenshots下
"""
file_path = os.path.dirname(os.path.abspath('.')) + '/screenshots/'
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
screen_name = file_path + rq + '.png'
try:
self.driver.get_screenshot_as_file(screen_name)
logger.info("Had take screenshot and save to folder : /screenshots")
except NameError as e:
logger.error("Failed to take screenshot! %s" % e)
self.get_windows_img() # 定位元素方法 def find_element(self, selector):
"""
这个地方为什么是根据=>来切割字符串,请看页面里定位元素的方法
submit_btn = "id=>su"
login_lnk = "xpath => //*[@id='u1']/a[7]" # 百度首页登录链接定位
如果采用等号,结果很多xpath表达式中包含一个=,这样会造成切割不准确,影响元素定位
:param selector:
:return: element
"""
element = ''
if '=>' not in selector:
return self.driver.find_element_by_id(selector)
selector_by = selector.split('=>')[0]
selector_value = selector.split('=>')[1] if selector_by == "i" or selector_by == 'id':
try:
element = self.driver.find_element_by_id(selector_value)
logger.info("Had find the element \' %s \' successful "
"by %s via value: %s " % (element.text, selector_by, selector_value))
except NoSuchElementException as e:
logger.error("NoSuchElementException: %s" % e)
self.get_windows_img() # take screenshot
elif selector_by == "n" or selector_by == 'name':
element = self.driver.find_element_by_name(selector_value)
elif selector_by == "c" or selector_by == 'class_name':
element = self.driver.find_element_by_class_name(selector_value)
elif selector_by == "l" or selector_by == 'link_text':
element = self.driver.find_element_by_link_text(selector_value)
elif selector_by == "p" or selector_by == 'partial_link_text':
element = self.driver.find_element_by_partial_link_text(selector_value)
elif selector_by == "t" or selector_by == 'tag_name':
element = self.driver.find_element_by_tag_name(selector_value)
elif selector_by == "x" or selector_by == 'xpath':
try:
element = self.driver.find_element_by_xpath(selector_value)
logger.info("Had find the element \' %s \' successful "
"by %s via value: %s " % (element.text, selector_by, selector_value))
except NoSuchElementException as e:
logger.error("NoSuchElementException: %s" % e)
self.get_windows_img()
elif selector_by == "s" or selector_by == 'selector_selector':
element = self.driver.find_element_by_css_selector(selector_value)
else:
raise NameError("Please enter a valid type of targeting elements.") return element # 输入 def type(self, selector, text): el = self.find_element(selector)
el.clear()
try:
el.send_keys(text)
logger.info("Had type \' %s \' in inputBox" % text)
except NameError as e:
logger.error("Failed to type in input box with %s" % e)
self.get_windows_img() # 清除文本框 def clear(self, selector): el = self.find_element(selector)
try:
el.clear()
logger.info("Clear text in input box before typing.")
except NameError as e:
logger.error("Failed to clear in input box with %s" % e)
self.get_windows_img() # 点击元素 def click(self, selector): el = self.find_element(selector)
try:
el.click()
logger.info("The element \' %s \' was clicked." % el.text)
except NameError as e:
logger.error("Failed to click the element with %s" % e) # 或者网页标题 def get_page_title(self):
logger.info("Current page title is %s" % self.driver.title)
return self.driver.title @staticmethod
def sleep(seconds):
time.sleep(seconds)
logger.info("Sleep for %d seconds" % seconds)
browser_engine.py
# coding=utf-8
from selenium import webdriver class BrowserEngine(object):
"""
定义一个浏览器引擎类,根据browser_type的值去,控制启动不同的浏览器,这里主要是IE,Firefox, Chrome """ def __init__(self, driver):
self.driver = driver browser_type = "Chrome" # maybe Firefox, Chrome, IE def get_browser(self):
"""
通过if语句,来控制初始化不同浏览器的启动,默认是启动Chrome
:return: driver
""" if self.browser_type == 'Firefox':
driver = webdriver.Firefox()
elif self.browser_type == 'Chrome':
driver = webdriver.Chrome()
elif self.browser_type == 'IE':
driver = webdriver.Ie()
else:
driver = webdriver.Chrome() # driver.maximize_window()
driver.implicitly_wait(10)
driver.get("https://www.baidu.com")
return driver
logger.py
# _*_ coding: utf-8 _*_
import logging
import os.path
import time class Logger(object):
def __init__(self, logger):
"""
指定保存日志的文件路径,日志级别,以及调用文件
将日志存入到指定的文件中
:param logger:
"""
# 创建一个logger
self.logger = logging.getLogger(logger)
self.logger.setLevel(logging.DEBUG) # 创建一个handler,用于写入日志文件
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
log_path = os.path.dirname(os.getcwd()) + '/Logs/'
log_name = log_path + rq + '.log'
fh = logging.FileHandler(log_name)
fh.setLevel(logging.INFO) # 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.INFO) # 定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter) # 给logger添加handler
self.logger.addHandler(fh)
self.logger.addHandler(ch) def getlog(self):
return self.logger
baidu_homepage.py
# coding=utf-8
from unittest3.framework.base_page import BasePage class HomePage(BasePage):
input_box = "id=>kw"
search_submit_btn = "xpath=>//*[@id='su']" def type_search(self, text):
self.type(self.input_box, text) def send_submit_btn(self):
self.click(self.search_submit_btn)
测试类代码 baidu_search.py
# coding=utf-8
import time
import unittest
from selenium import webdriver
from unittest3.page_object.baidu_homepage import HomePage
from unittest3.framework.browser_engine import BrowserEngine class BaiduSearch(unittest.TestCase):
def setUp(self):
"""
测试固件的setUp()的代码,主要是测试的前提准备工作
:return:
"""
# 添加如下代码,可运行
# -------------------------------------------
# browse = BrowserEngine(self)
# self.driver = webdriver.Firefox()
# self.driver.get('https://www.baidu.com')
#-------------------------------------------
# 修改代码可以执行
browse = BrowserEngine(self)
self.driver=browse.get_browser() def tearDown(self):
"""
测试结束后的操作,这里基本上都是关闭浏览器
:return:
"""
self.driver.quit() def test_baidu_search(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
:return:
"""
homepage = HomePage(self.driver)
homepage.type_search('selenium') # 调用页面对象中的方法
homepage.send_submit_btn() # 调用页面对象类中的点击搜索按钮方法
time.sleep(2)
homepage.get_windows_img() # 调用基类截图方法
try:
assert 'selenium' in homepage.get_page_title() # 调用页面对象继承基类中的获取页面标题方法
print('Test Pass.')
except Exception as e:
print('Test Fail.', format(e)) if __name__ == '__main__':
unittest.main()
python selenium 基础框架的更多相关文章
- Python+Selenium基础入门及实践
Python+Selenium基础入门及实践 32018.08.29 11:21:52字数 3220阅读 23422 一.Selenium+Python环境搭建及配置 1.1 selenium 介绍 ...
- python+selenium+unnittest框架
python+selenium+unnittest框架,以百度搜索为例,做了一个简单的框架,先看一下整个项目目录结构 我用的是pycharm工具,我觉得这个工具是天使,超好用也超好看! 这些要感谢原作 ...
- 从零开始到设计Python+Selenium自动化测试框架-如何开始
如何开始学习web ui自动化测试?如何选择一门脚本语言?选择什么自动化测试工具? 本人已经做测试快5年,很惭愧,感觉积累不够,很多测试都不会,三年多功能测试,最近两年才开始接触和学习自动化测试.打算 ...
- 《一头扎进》系列之Python+Selenium自动化测试框架实战篇6 - 价值好几K的框架,呦!这个框架还真牛叉哦!!!
1. 简介 本文开始介绍如何通过unittest来管理和执行测试用例,这一篇主要是介绍unittest下addTest()方法来加载测试用例到测试套件中去.用addTest()方法来加载我们测试用例到 ...
- python+selenium基础篇,切入切出frame
1.首先制作一个html的文件,代码如下 <!DOCTYPE html> <html> <head> <title>Frame_test</tit ...
- Python+Selenium基础篇之1-环境搭建
Python + Selenium 自动化环境搭建过程 1. 所需组建 1.1 Selenium for python 1.2 Python 1.3 Notepad++ 作为刚初学者,这里不建议使用P ...
- python+selenium之框架设计
一.自动化测试框架 1.什么是自动化测试框架 简单来说,自动化测试框架就是由一些标准,协议,规则组成,提供脚本运行的环境.自动化测试框架能够提供很多便利给用户高效完成一些事情,例如,结构清晰开发脚本, ...
- selenium基础框架的封装(Python版)
一.常用函数的封装 在使用selenium做web自动化测试的过程中,经常会碰到各种各样的问题,比如: 1.页面加载比较慢时,selenium查找元素抛出异常,导致脚本运行中止 2.写完脚本后发现代码 ...
- selenium基础框架的封装(Python版)这篇帖子在百度关键词搜索的第一位了,有图为证,开心!
百度搜索结果页地址:https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&rsv_idx=1&tn=baidu&wd=se ...
随机推荐
- nginx链接末尾自动补全斜杠
放在locaation里边就行 if (-d $request_filename){ rewrite ^(.*[^/])$ $/ permanent;#加斜杠 } 这样,nginx就会进行判断了,如果 ...
- fastjson 对象和json互转
list转json List<Openid> openids = od.getAll(session); String json = JSONObject.toJSONString(ope ...
- python元祖和列表
下面讲到的分别有: 列表:元祖 列表的定义 list(列表)是python中使用最频繁的数据类型,在其他语言中叫做数组 专门储存一串信息 列表[ ]定义,数据之间有逗号分隔 列表的索引是从0开始的 ...
- Leetcode54. Spiral Matrix螺旋矩阵
给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素. 示例 1: 输入: [ [ 1, 2, 3 ], [ 4, 5, 6 ], [ 7, 8, 9 ...
- Java 1.8 Stream 用例测试
package stream; import model.Student; import org.junit.jupiter.api.Test; import java.util.*; import ...
- Spring boot--控制器增强
在Spring3.2中,新增了@ControllerAdvice注解.关于这个注解的官方说明https://docs.spring.io/spring-framework/docs/5.0.0.M1/ ...
- day38 15-Spring的配置文件引入的问题
配置文件内容过多修改起来维护起来很麻烦.Struts 2可以在总的配置文件中引入其他的配置文件.这是一种办法.第二种办法在加载配置文件的时候,里面可以一次性传多个. <?xml version= ...
- Thrift框架应用参考
Thrift https://blog.csdn.net/aquester/article/details/48261609 https://www.cnblogs.com/liboBlog/p/60 ...
- ios开发ARC,IBOutlets之strong与weak
今天在写程序的时候,用IBOutlets连了一个自定义的控件,出现了问题,后面访问的时候,控件里有些subviews没有初始化好,取到的时候为nil, 程序里用了ARC, IBOutlets一连接上, ...
- 剑指offer 1-6
1. 二维数组中的查找 在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数. 分析 ...