排序算法<No.7>【希尔排序】
排序算法进入到第7篇,这个也还是比较基础的一种,希尔排序,该排序算法,是依据该算法的发明人donald shell的名字命名的。1959年,shell基于传统的直接插入排序算法,对其性能做了下提升,其思路,主要是基于下面的原因进行的:
下面,我们就看看希尔排序,具体的实现思路如下:
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止
由上面的分析可知,希尔排序,其实是对原始待排序列的分组插入排序,这种分组,很巧妙,再次体现了分而治之这个思想的厉害。前面介绍过的排序:
排序算法<No.3>【桶排序】,排序算法<No.4>【基数排序】都是分治思想的体现。
针对上面的实现思路,可以将其分解为如下的代码实现步骤:
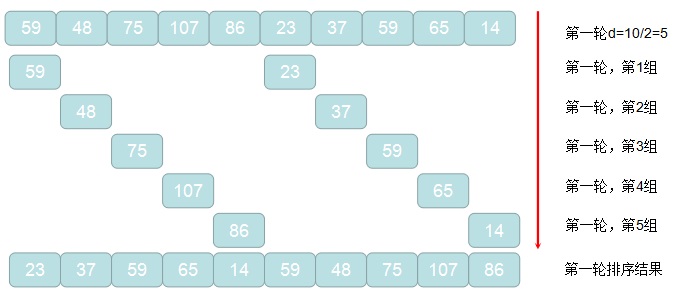
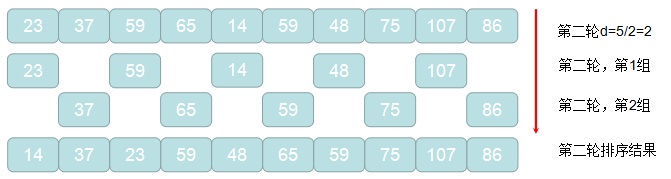
1. 获取原始待排记录的元素个数len,并计算初始增量d=len/2
2. 通过d = d/2进行循环,对待排记录进行分组,d作为增量值,每间隔d的元素被划分到一组
3. 对2中每组元素进行直接插入排序算法进行排序
4. 重复2,3的过程,直到2中计算的增量d=1的这轮排序结束,程序退出,排序完成
下面,举个栗子来看看,希尔排序的实现过程吧,例如待排序列:59,48,75,107,86,23,37,59,65,14

相应的java代码实现如下:
/**
* @author "shihuc"
* @date 2017年4月9日
*/
package shellSort; import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner; /**
* @author "shihuc"
*
*/
public class Solution { /**
* @param args
*/
public static void main(String[] args) {
File file = new File("./src/shellSort/sample.txt");
Scanner sc = null;
try {
sc = new Scanner(file);
int N = sc.nextInt();
for (int i = ; i < N; i++) {
int S = sc.nextInt();
int A[] = new int[S];
for (int j = ; j < S; j++) {
A[j] = sc.nextInt();
}
shellSort(A);
print(A, i, "....");
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (sc != null) {
sc.close();
}
} } /**
* 希尔排序的实现过程
*
* @param src 待排序的原始数列
*/
private static void shellSort(int src[]) { /*
* 实现步骤 (1)
* 获取原始待排记录的元素个数len,并计算初始增量d=len/2
*/
int d = src.length / ; /*
* 实现步骤(4)
*/
while (d > ) { /*
* 实现步骤(3)
* 通过增量d对待排序的数列进行分组,进行插入排序. 注意,排序中待比较的元素之间的差距是d
*/
for(int i = d; i<src.length; i=i+d){ int temp = src[i];
int j = i - d; /*
* 在获取参考值,也就待排序数列中当前位置的值,然后与其前面的需要排序的组内成员进行
* 插入排序。注意,这里的步长是d,和直接插入排序算法中的步长1的差异。认真想想,不难理解的。
*/
while(j >= && src[j] > temp){
src[j+d] = src[j];
j = j - d;
}
src[j+d] = temp;
} /*
* 实现步骤(2)
* 下面这个过程,其实就是不断迭代计算出新的增量d。
*/
d = d / ;
}
} /**
* 用来打印输出堆中的数据内容。
*
* @param A
* 堆对应的数组
* @param idx
* 当前是第几组待测试的数据
* @param info
* 打印中输出的特殊信息
*/
private static void print(int A[], int idx, String info) {
System.out.println(String.format("No. %02d %s ====================== ", idx, info));
for (int i = ; i < A.length; i++) {
System.out.print(A[i] + ", ");
}
System.out.println();
}
}
测试栗子文件内容如下:
测试运行的结果如下:
No. .... ======================
, , , , , , , , , ,
No. .... ======================
, , , , , , ,
No. .... ======================
, , , , , , , , , ,
No. .... ======================
, , , , , , , , , , ,
No. .... ======================
, , , , , , ,
No. .... ======================
, , , , , , , , ,
其实,还是比较简单的,重点在于分组,插入排序的步长由原来的普通插入排序步长1变成了现在的d。
排序算法<No.7>【希尔排序】的更多相关文章
- 八大排序算法之二希尔排序(Shell Sort)
希尔排序是1959 年由D.L.Shell 提出来的,相对直接排序有较大的改进.希尔排序又叫缩小增量排序 基本思想: 先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录 ...
- 排序算法入门之希尔排序(java实现)
希尔排序是对插入排序的改进.插入排序是前面元素已经有序了,移动元素是一个一个一次往后移动,当插入的元素比前面排好序的所有元素都小时,则需要将前面所有元素都往后移动.希尔排序有了自己的增量,可以理解为插 ...
- python算法介绍:希尔排序
python作为一种新的语言,在很多功能自然要比Java要好一些,也容易让人接受,而且不管您是成年人还是少儿都可以学习这个语言,今天就为大家来分享一个python算法教程之希尔排序,现在我们就来看看吧 ...
- python算法与数据结构-希尔排序算法(35)
一.希尔排序的介绍 希尔排序(Shell Sort)是插入排序的一种.也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本.希尔排序是非稳定排序算法. 希尔排序是把记录按下标的一定增量分组,对每 ...
- C# 插入排序 冒泡排序 选择排序 高速排序 堆排序 归并排序 基数排序 希尔排序
C# 插入排序 冒泡排序 选择排序 高速排序 堆排序 归并排序 基数排序 希尔排序 以下列出了数据结构与算法的八种基本排序:插入排序 冒泡排序 选择排序 高速排序 堆排序 归并排序 基数排序 希尔排序 ...
- Java常见排序算法之直接选择排序
在学习算法的过程中,我们难免会接触很多和排序相关的算法.总而言之,对于任何编程人员来说,基本的排序算法是必须要掌握的. 从今天开始,我们将要进行基本的排序算法的讲解.Are you ready?Let ...
- Java排序算法之直接选择排序
Java排序算法之直接选择排序 基本过程:假设一序列为R[0]~R[n-1],第一次用R[0]和R[1]~R[n-1]相比较,若小于R[0],则交换至R[0]位置上.第二次从R[1]~R[n-1]中选 ...
- Hark的数据结构与算法练习之希尔排序
算法说明 希尔排序是插入排序的优化版. 插入排序的最坏时间复杂度是O(n2),但如果要排序的数组是一个几乎有序的数列,那么会降低有效的减低时间复杂度. 希尔排序的目的就是通过一个increment(增 ...
- C#算法基础之希尔排序
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- Java与算法之(10) - 希尔排序
希尔排序是插入排序的一种,是直接插入排序的改进版本. 对于上节介绍的直接插入排序法,如果数据原来就已经按要求的顺序排列,则在排序过程中不需要进行数据移动操作,即可得到有序数列.但是,如果最初的数据是按 ...
随机推荐
- :after和:before伪元素的解释
:after 是清除浮动 让其高度和内容高度相同 :before 是防止上边塌陷 关注微信小程序
- 【Python】多进程2
#练习:测试单进程和多进程执行效率 import multiprocessing import time def m1(x): time.sleep(0.01) return x * x if __n ...
- box-sizing布局
box-sizing 语法:box-sizing: content-box | border-box | inherit; 参考: https://www.jianshu.com/p/e2eb0d8c ...
- Python学习笔记第十七周
目录: 一.jQuery 内容: 一.jQuery: ps:版本 1.xx (推荐最新版本,兼容性好) 2.xx 3.xx 转换: jQuery对象[0] => DOM对象 $(DOM对象 ...
- 20165228 2017-2018-2 《Java程序设计》第5周学习总结
20165228 2017-2018-2 <Java程序设计>第5周学习总结 教材学习内容总结 内部类和匿名类 通过throw关键字抛出异常对象,终止方法的继续执行 使用try-catch ...
- tinyxml2使用
项目中遇到一个问题,C/C++需要与JAVA通信,JAVA方已经使用了XML序列化传输.本可以考虑JSON/GOOGLE PROTOCOL BUFFER的,但为了使JAVA方不做过多改动,坚持使用XM ...
- servlet简单介绍
什么是Servlet? servlet是一种Java编程语言类,用于扩展托管通过请求 - 响应编程模型访问的应用程序的服务器的功能.尽管servlet可以响应任何类型的请求,但它们通常用于扩展Web服 ...
- J - FatMouse's Speed
p的思路不一定要到最后去找到ans:也可以设置成在中间找到ans:比如J - FatMouse's Speed 这个题,如果要是让dp[n]成为最终答案的话,即到了i,最差的情况也是dp[i-1],就 ...
- python笔记-1(import导入、time/datetime/random/os/sys模块)
python笔记-6(import导入.time/datetime/random/os/sys模块) 一.了解模块导入的基本知识 此部分此处不展开细说import导入,仅写几个点目前的认知即可.其 ...
- PS学习之如何把小姐姐塞进瓶子里
准备素材 开始制作 用PS新建一个国际通用纸张大小的画布 分辨率可以调为72 改变背景色 插入图片 水平居中对齐 插入木质素材 放大 覆盖之前的素材 调整图层顺序 创建剪切蒙版 对木桩添加曲线 设置立 ...