ML: 聚类算法R包 - 模型聚类
模型聚类
- mclust::Mclust
- RWeka::Cobweb
mclust::Mclust
EM算法也称为期望最大化算法,在是使用该算法聚类时,将数据集看作一个有隐形变量的概率模型,并实现模型最优化,即获取与数据本身性质最契合的聚类方式为目的,通过‘反复估计’模型参数找出最优解,同时给出相应的最有类别级数k
所需程序安装包
install.packages("mclust")
函数示例代码
> library(mclust)
> EM<-Mclust(iris[,-5])
> summary(EM,parameters=T)
----------------------------------------------------
Gaussian finite mixture model fitted by EM algorithm
---------------------------------------------------- Mclust VEV (ellipsoidal, equal shape) model with 2 components: log.likelihood n df BIC ICL
-215.726 150 26 -561.7285 -561.7289 Clustering table:
1 2
50 100 Mixing probabilities:
1 2
0.333332 0.666668 Means:
[,1] [,2]
Sepal.Length 5.0060021 6.261996
Sepal.Width 3.4280046 2.871999
Petal.Length 1.4620006 4.905993
Petal.Width 0.2459998 1.675997
可以看到最优类别级数为2,各类分别含有50,100,
mclust::plot.Mclust(EM,what = "classification")
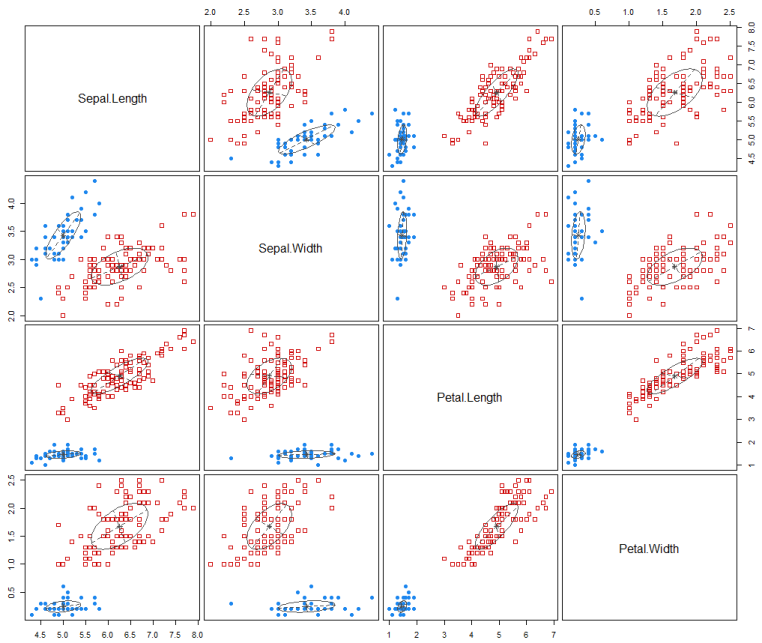
mclust::plot.Mclust(EM,what = "density")

RWeka::Cobweb
COBWEB是一种流行的简增量概念聚类算法。它以一个分类树的形式创建层次聚类,每个节点对应一个概念,包含该概念的一个概率描述,概述被分在该节点下的对象。使得该函数,需要安装RWeka包,在安装的过程中,可能出现如下的异常
** R
** inst
** preparing package for lazy loading
Error : .onLoad failed in loadNamespace() for 'rJava', details:
call: fun(libname, pkgname)
error: JAVA_HOME cannot be determined from the Registry
ERROR: lazy loading failed for package 'RWeka'
* removing 'C:/Users/zhushy/Documents/R/win-library/3.2/RWeka'
安装jre, 参考资料: http://blog.csdn.net/afei__/article/details/51464783
RWeka包未安装成功,示例代码未验证,待确认
library(RWeka) dcom=iris[,-5]
c1<-Cobweb(dcom)
c1
c1$class_ids
table(predict(c1),dcom$clas)
参考资料:
ML: 聚类算法R包 - 模型聚类的更多相关文章
- ML: 聚类算法R包-模糊聚类
1965年美国加州大学柏克莱分校的扎德教授第一次提出了'集合'的概念.经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面.为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析.用模 ...
- ML: 聚类算法R包-层次聚类
层次聚类 stats::hclust stats::dist R使用dist()函数来计算距离,Usage: dist(x, method = "euclidean", di ...
- ML: 聚类算法R包-网格聚类
网格聚类算法 optpart::clique optpart::clique CLIQUE(Clustering In QUEst)是一种简单的基于网格的聚类方法,用于发现子空间中基于密度的簇.CLI ...
- ML: 聚类算法R包 - 密度聚类
密度聚类 fpc::dbscan fpc::dbscan DBSCAN核心思想:如果一个点,在距它Eps的范围内有不少于MinPts个点,则该点就是核心点.核心和它Eps范围内的邻居形成一个簇.在一个 ...
- ML: 聚类算法R包-对比
测试验证环境 数据: 7w+ 条,数据结构如下图: > head(car.train) DV DC RV RC SOC HV LV HT LT Type TypeName 1 379 85.09 ...
- ML: 聚类算法R包-K中心点聚类
K-medodis与K-means比较相似,但是K-medoids和K-means是有区别的,不一样的地方在于中心点的选取,在K-means中,我们将中心点取为当前cluster中所有数据点的平均值, ...
- 聚类算法之k-均值聚类
k-均值聚类算法 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 适用数据类型:数值型数据 其工作流程:首先,随机确定k个初始点作为质心,然后将数据集中的每个点分配到一个簇中,具 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- Kmeans文档聚类算法实现之python
实现文档聚类的总体思想: 将每个文档的关键词提取,形成一个关键词集合N: 将每个文档向量化,可以参看计算余弦相似度那一章: 给定K个聚类中心,使用Kmeans算法处理向量: 分析每个聚类中心的相关文档 ...
随机推荐
- Bug04_spring注解报错
maven 的pom文件中, 没有导入spring的依赖 <dependency> <groupId>org.springframework</groupId> & ...
- [转]redis主从配置及主从切换
http://blog.csdn.net/zfl092005/article/details/17523945 环境描述: 主Redis:192.168.10.1 6379 从redis:192.16 ...
- 安卓与Unity交互之-Android Studio创建Module库模块教程
安卓开发工具创建Module库 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- 心分 ...
- php基础-3
php的数据类型 字符串 字符串的声明:$str = "aaa"; 字符串的方法 strpos(str, find_str):该方法在一个字符串中查找需要查找的字符串,并回来该字符 ...
- 实验吧—Web——WP之 因缺思汀的绕过
首先打开解题链接查看源码: 查看源码后发现有一段注释: <!--source: source.txt-->这点的意思是:原来的程序员在写网页时给自己的一个提醒是源码在这个地方,我们要查看时 ...
- 一道dp[不太好写]
http://acm.csu.edu.cn:20080/csuoj/problemset/problem?pid=2281 Description An arithmetic progression ...
- pageContext中page、request、session、application四种范围变量的用法。
在PageContext中有很多作用域 第一种:PageContext.PAGE_SCOPE适用于当前页面的作用域,其接受数据的代码是pageContext.getAttribute();访问页面也是 ...
- 【HAOI2014】遥感监测
独立博客被硬盘保护干掉了真不爽啊…… 原题: 外星人指的是地球以外的智慧生命.外星人长的是不是与地球上的人一样并不重要,但起码应该符合我们目前对生命基本形式的认识.比如,我们所知的任何生命都离不开液态 ...
- JQuery中serialize()方法的使用
- scala学习笔记-面向对象编程之Trait
将trait作为接口使用 1 // Scala中的Triat是一种特殊的概念 2 // 首先我们可以将Trait作为接口来使用,此时的Triat就与Java中的接口非常类似 3 // 在triat中可 ...