从文本中提取图片路径(java 解析富文本处理 img 标签)
很多项目都需要到富文本来添加内容,就好比新闻啊,旅游景点之类的,都需要使用富文本去添加数据,然而怎么我这边就发现了两个问题
怎样将富文本的图片的 src 获取出来?
方法一:
利用正则表达式:
public static List<String> getImgStr(String htmlStr) {
List<String> list = new ArrayList<>();
String img = "";
Pattern p_image;
Matcher m_image;
// String regEx_img = "<img.*src=(.*?)[^>]*?>"; //图片链接地址
String regEx_img = "<img.*src\\s*=\\s*(.*?)[^>]*?>";
p_image = Pattern.compile(regEx_img, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(htmlStr);
while (m_image.find()) {
// 得到<img />数据
img = m_image.group();
// 匹配<img>中的src数据
Matcher m = Pattern.compile("src\\s*=\\s*\"?(.*?)(\"|>|\\s+)").matcher(img);
while (m.find()) {
list.add(m.group(1));
}
}
return list;
}
即可获取到以下结果

方法二:
引入一个叫做 jsoup 的 jar, (下载地址:https://jsoup.org/download)
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
下面是工具类
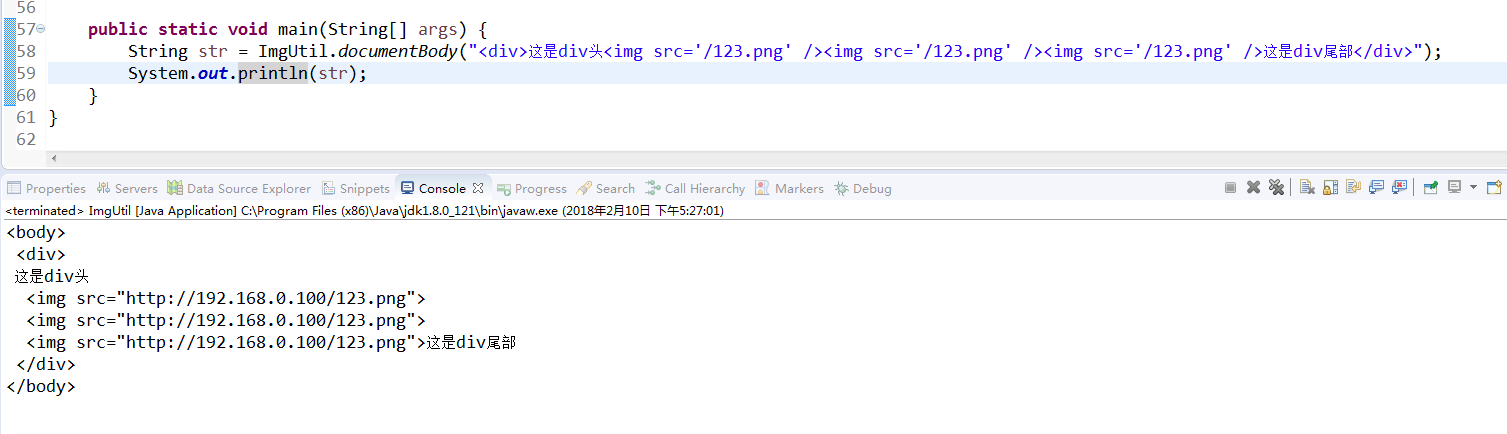
public static String documentBody (String newsBody) {
Element doc = Jsoup.parseBodyFragment(newsBody).body();
Elements pngs = doc.select("img[src]");
String httpHost = "http://192.168.0.100";
for (Element element : pngs) {
String imgUrl = element.attr("src");
if (imgUrl.trim().startsWith("/")) { // 会去匹配我们富文本的图片的 src 的相对路径的首个字符,请注意一下
imgUrl =httpHost + imgUrl;
element.attr("src", imgUrl);
}
}
return newsBody = doc.toString();
}
转载自:https://www.cnblogs.com/xjbBill/p/8439248.html
从文本中提取图片路径(java 解析富文本处理 img 标签)的更多相关文章
- JAVA-替换html中图片的路径-从html代码中提取图片路径并下载(完整版)
transHtml方法实现提取网络图片中得图片路径,将其重新下载到本地,并替换html中原来得路径 package com.googosoft.until; import java.io.Buffer ...
- java 解析富文本处理 img 标签
很多项目都需要到富文本来添加内容,就好比新闻啊,旅游景点之类的,都需要使用富文本去添加数据,然而怎么我这边就发现了两个问题 1)怎样将富文本的图片的 src 获取出来? 2)后台上传的时候用的是相对路 ...
- 用正则从html代码中提取图片路径
$str = '<div align="center"> <img src="http://www.99tyg.com/public/images/e8 ...
- wxParse解析富文本内容使点击图片可以选中并实现放大缩小
wxParse解析富文本内容不多说,之前写过步骤介绍,主要是在使用过程中发现解析的富文本内容里有图片时有的可以点击放大缩小,有的点击却报错,找不到imgUrls. 经过排查发现:循环解析的富文本内容正 ...
- 利用ROS工具从bag文件中提取图片
bag文件是ROS常用的数据存储格式,因此要从bag文件中提取数据就需要了解一点ROS的背景知识. 1. 什么是ROS及其优势 ROS全称Robot Operating System,是BSD-lic ...
- C#正则表达式匹配HTML中的图片路径,图片地址
C#正则表达式匹配HTML中的图片路径,图片地址 最近的项目中有个关于网页取图的功能需要我自己开发,那就是用正则表达式来匹配图片标签. 一般来说一个 HTML 文档有很多标签,比如“< ...
- NLP入门(十一)从文本中提取时间
在我们的日常生活和工作中,从文本中提取时间是一项非常基础却重要的工作,因此,本文将介绍如何从文本中有效地提取时间. 举个简单的例子,我们需要从下面的文本中提取时间: 6月28日,杭州市统计局权 ...
- 从html富文本中提取纯文本
其实从html富文本中提取纯文本很简单,富文本基本上是使用html标签给文本加上丰富多彩的样式. 所以只需要将富文本字符串中的“<.....>”标签剔除,即可得到纯文本.我们可以使用正则表 ...
- php读取出字符串中的img标签中的图片路径
php读取出字符串中的img标签中的图片路径 $pageContents = '字符串,带img标签'; $pageContents = str_replace('\"','"', ...
随机推荐
- python连接Greenplum数据库
配置greenplum客户端认证 配置pg_hba.conf cd /home/gpadmin/gpdbdata/master/gpseg- vim pg_hba.conf 增加 host all g ...
- 改变input的值不会触发change事件的解决思路
通常来说,如果我们自己通过 value 改变了 input 元素的值,我们肯定是知道的,但是在某些场景下,页面上有别的逻辑在改变 input 的 value 值,我们可能希望能在这个值发生变化的时候收 ...
- Lua IUP 环境搭建
1.从sourceforge.net下载Luabinaries.IUP.CD.IM.LuaGL的源码 2.编译CD 2.1.用cd\mak.vc12中的lua_version53.props替换lua ...
- Nacos发布0.5.0版本,轻松玩转动态 DNS 服务
阿里巴巴微服务开源项目Nacos于近期发布v0.5.0版本,该版本主要包括了DNS-basedService Discovery,对Java 11的支持,持续优化Nacos产品用户体验,更深度的与Sp ...
- Build a Machine Learning Portfolio(构建机器学习投资组合)
Complete Small Focused Projects and Demonstrate Your Skills (完成小型针对性机器学习项目,证明你的能力) A portfolio is ty ...
- go使用rpc
RPC是远程过程调用的缩写(Remote Procedure Call),通俗地说就是调用远处的一个函数,是分布式系统中不同节点间流行的通信方式.Go语言的标准库提供了一个简单的RPC实现 serve ...
- man mountd(rpc.mountd中文手册)
本人译作集合:http://www.cnblogs.com/f-ck-need-u/p/7048359.html rpc.mountd() System Manager's Manual rpc.mo ...
- 基于SpringMVC+Spring+MyBatis实现秒杀系统【数据库接口】
前言 该篇教程主要关注MyBatis实现底层的接口,把MyBatis交给Spring来托管.数据库连接池用的c3p0.数据库用的MySQL.主要有2个大类:秒杀商品的查询.秒杀明细的插入. 准备工作 ...
- word2vec初探
在自然语言处理入门里我们提到了词向量的概念,tf-idf的概念,并且在实际的影评正负面预测项目中使用了tf-idf,取得了还算不错的效果.这一篇,我们来尝试一下使用来自google的大名鼎鼎的word ...
- AngularJs_自定义注入对象_笔记1
A-自定义控件示例: 我的自定义控件文件为:angular-seagull2-common.js (function (window, angular) { 'use strict'; $urlPro ...