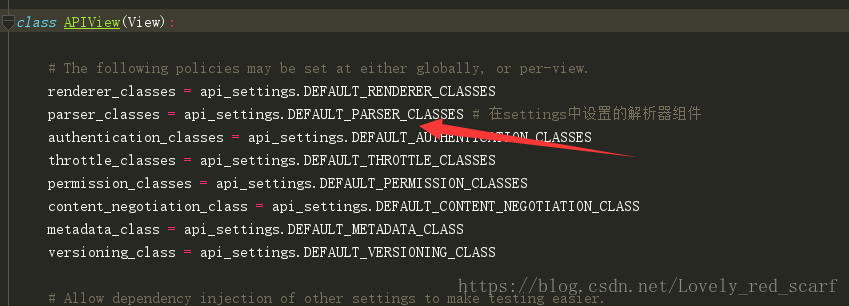
REST Framework组件的解析源码
首先我们要知道解析器的作用
- 解析器就是对你请求体中的数据进行反序列化、封装 把你的所有的请求数据都封装在request.data中 以后就在request.data中获取数据
我们先导入rest_framework的解析器
from rest_framework.parsers import JSONParser,FormParser
from rest_framework.parsers import JSONParser,FormParser
class PaserView(APIView):
parser_classes = [JSONParser,FormParser,]
#JSONParser:表示只能解析content-type:application/json的头
#FormParser:表示只能解析content-type:application/x-www-form-urlencoded的头
def post(self,request,*args,**kwargs):
#获取解析后的结果
print(request.data)
return HttpResponse('paser')在settings中的配置
#全局配置
REST_FRAMEWORK = {
#版本
"DEFAULT_VERSIONING_CLASS":"rest_framework.versioning.URLPathVersioning",
#解析器
"DEFAULT_PARSER_CLASSES":["rest_framework.parsers.JSONParser","rest_framework.parsers.FormParser"]
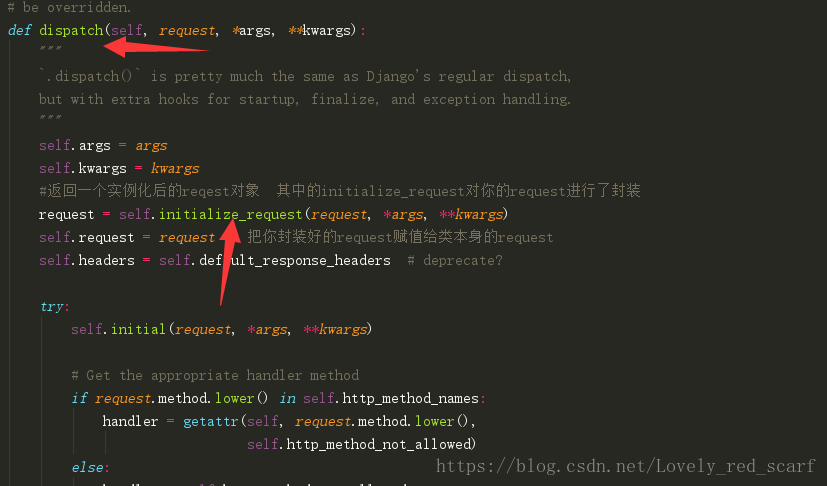
}先通过APIView进入源码 因为APIView是rest_framework的源码进入口
- 然后进入你的dispath函数中的initialize_request
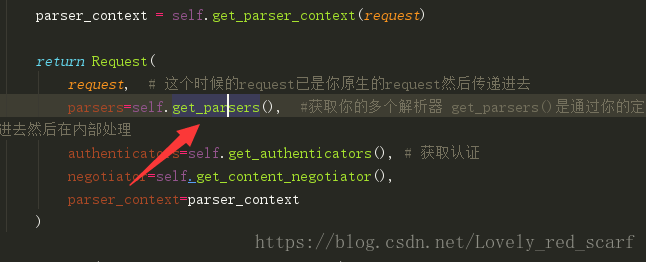
def initialize_request(self, request, *args, **kwargs):
"""
Returns the initial request object.
"""
parser_context = self.get_parser_context(request)
return Request(
request, # 这个时候的request已是你原生的request然后传递进去
parsers=self.get_parsers(), #获取你的多个解析器 get_parsers()是通过你的定义 parser_classes进行的得到的信息 然后得到的列表 赋值给parsers传递进去然后在内部处理
authenticators=self.get_authenticators(), # 获取认证
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
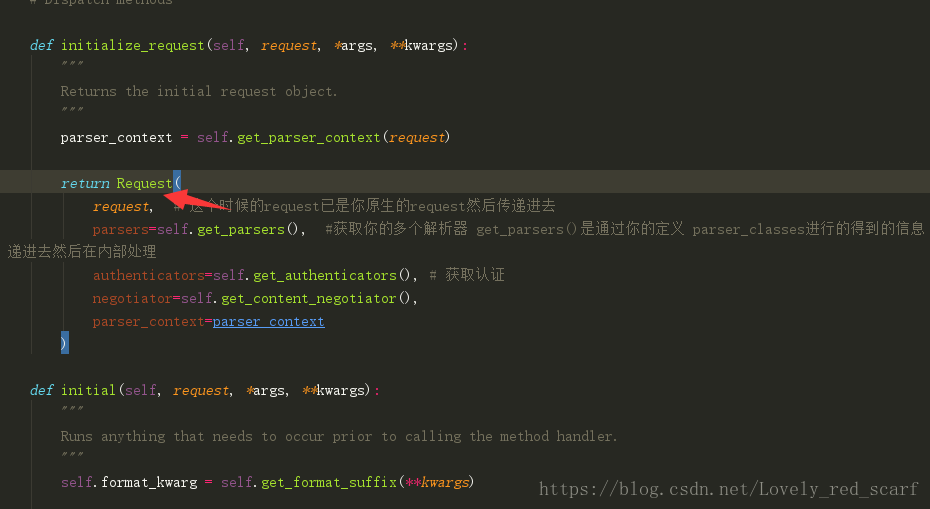
然后你的self.get_parsers()获取你的代码中的parser内容赋值给parsers
def get_parsers(self):
"""
Instantiates and returns the list of parsers that this view can use.
"""
return [parser() for parser in self.parser_classes] # 返回列表生成式 遍历你的self.parser_classes 是对你的在settings中设置的配置进行判断
你的self.parser_classes是从你的requet类中的get_parsers是从最开始APIView中获取值的 然后返回一个列表进行到request对象中
然后进入你的request对象中
def __init__(self, request, parsers=None, authenticators=None,
negotiator=None, parser_context=None):
assert isinstance(request, HttpRequest), (
'The `request` argument must be an instance of '
'`django.http.HttpRequest`, not `{}.{}`.'
.format(request.__class__.__module__, request.__class__.__name__)
)
self._request = request # 对你的原生了request进行 封装
self.parsers = parsers or () #如果有parsers请求体重的数据就拿到没有就为空
self.authenticators = authenticators or ()
self.negotiator = negotiator or self._default_negotiator()
self.parser_context = parser_context
self._data = Empty
self._files = Empty
self._full_data = Empty
self._content_type = Empty
self._stream = Empty然后执行你的这个里面的def _parse方法
def _parse(self): # 解析器会走这个
"""
Parse the request content, returning a two-tuple of (data, files) # 解析请求的内容会返回两个一个元组内部有两个参数
May raise an `UnsupportedMediaType`, or `ParseError` exception.
"""
media_type = self.content_type # 获取你的请求体中的数据类型
try:
stream = self.stream
except RawPostDataException:
if not hasattr(self._request, '_post'):
raise
# If request.POST has been accessed in middleware, and a method='POST'
# request was made with 'multipart/form-data', then the request stream
# will already have been exhausted.
if self._supports_form_parsing():
return (self._request.POST, self._request.FILES)
stream = None
if stream is None or media_type is None:
if media_type and is_form_media_type(media_type):
empty_data = QueryDict('', encoding=self._request._encoding)
else:
empty_data = {}
empty_files = MultiValueDict()
return (empty_data, empty_files)
parser = self.negotiator.select_parser(self, self.parsers) # select_parser 对你拿到的parsers实例化对象 然后select_parser再根据你的实例对象进行请求方式的匹配 self.parsers是拿到你的请求值
你的_parse是对你的init中的传递进来deparser进行加工判断

_parse方法中的media_type = self.content_type # 获取你的请求体中的数据类型 也是至关重要的,然后你的self.negotiator.select_parser() 就对你的传递进来的值进行解析判断
点击进入self.negotiator.select_parser()方法中

def select_parser(self, request, parsers):
"""
Given a list of parsers and a media type, return the appropriate
parser to handle the incoming request. 给定解析器列表和媒体类型,返回相应的
解析器来处理传入的请求。
"""
for parser in parsers: # 对你传递进来的值进行请求方式的匹配
if media_type_matches(parser.media_type, request.content_type):
return parser
return None
negotiator.select_parser()是通过对象本身的media_type 请求方式对你的请求体中内容进行的解析 然后这一步才最终解析完毕
综上就是rest_framework的源码执行流程
首先你要先从APIView中获取进入 在Request对象中中通过get_parsers方法获取你的setting中设置的解释器组件 然后循环这个解析器组件得到每一个解析器
然后得到的解析器给parsers通过第三path方法中的initialize_request方法内部的Request对象
然后Request中的_parse方法对你传递进来的然后针对你的parser解析器对象和请求方式media_type 获取你的请求方式 进行请求方式和请求解析器的匹配
然后你的_parse中的select_parser方法根据 media_type和解析器对象进行匹配判断 使用对应的解析器进行请求方式的解析
所以先是循环你的解析器对象 然后 把这个对象传递进Request中然后Request中的_parse中再对象你的请求方式和解析器匹配 然后选择对应的解析器对你的 请求方式进行解析
纯属个人见解 看了两天才看懂也是够笨的了希望对正在钻研的你有帮助、 与君共勉!!!
REST Framework组件的解析源码的更多相关文章
- EventBus源码解析 源码阅读记录
EventBus源码阅读记录 repo地址: greenrobot/EventBus EventBus的构造 双重加锁的单例. static volatile EventBus defaultInst ...
- 调试 .NET Framework 源代码、.DotNetCore源码
调试 .NET Framework 源代码..DotNetCore源码 如何调试 .NET Framework 源代码 在 Visual Studio 调试器中指定符号 (.pdb) 和源文件 .NE ...
- Flink 源码解析 —— 源码编译运行
更新一篇知识星球里面的源码分析文章,去年写的,周末自己录了个视频,大家看下效果好吗?如果好的话,后面补录发在知识星球里面的其他源码解析文章. 前言 之前自己本地 clone 了 Flink 的源码,编 ...
- .Net Core 认证组件之Cookie认证组件解析源码
接着上文.Net Core 认证系统源码解析,Cookie认证算是常用的认证模式,但是目前主流都是前后端分离,有点鸡肋但是,不考虑移动端的站点或者纯管理后台网站可以使用这种认证方式.注意:基于浏览器且 ...
- Django的rest_framework认证组件之全局设置源码解析
前言: 在我的上一篇博客我介绍了一下单独为某条url设置认证,但是如果我们想对所有的url设置认证,该怎么做呢?我们这篇博客就是给大家介绍一下在Rest_framework中如何实现全局的设置认证组件 ...
- Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码
在文章:Mybatis源码解析,一步一步从浅入深(一):创建准备工程,中我们为了解析mybatis源码创建了一个mybatis的简单工程(源码已上传github,链接在文章末尾),并实现了一个查询功能 ...
- Mybatis的初始化和结合Spring Framework后初始化的源码探究
带着下面的问题进行学习: (1)Mybatis 框架或 Spring Framework 框架对数据层 Mapper 接口做了代理,那是做了 JDK 动态代理还是 CGLIB 代理? (2)Mappe ...
- Vue3全局APi解析-源码学习
本文章共5314字,预计阅读时间5-15分钟. 前言 不知不觉Vue-next的版本已经来到了3.1.2,最近对照着源码学习Vue3的全局Api,边学习边整理了下来,希望可以和大家一起进步. 我们以官 ...
- SPRING多个占位符配置文件解析源码研究--转
原文地址:http://www.cnphp6.com/archives/85639 Spring配置文件: <context:property-placeholder location=&quo ...
随机推荐
- 基于TrueLicense实现产品License验证功能
受朋友所托,需要给产品加上License验证功能,进行试用期授权,在试用期过后,产品不再可用. 通过研究调查,可以利用Truelicense开源框架实现,下面分享一下如何利用Truelicense实现 ...
- 在Struts2标签s:textfield中显示正确的日期
Java代码 struts2中的日期期输入显示问题 struts2 中的默认的日期输出并不符合我们的中文日常习惯.以下是我知道的在struts2中进行日期格式化输出的几种方式. 1.利用 &l ...
- ruby中nil?, empty? and blank?的选择
In Ruby, you check with nil? if an object is nil: article = nil article.nil? # => true empty? che ...
- [BZOJ 5072]小A的树
Description 题库链接 给你 \(n\) 个节点的一棵树,点分黑白. \(q\) 组询问,每次询问类似于"是否存在树中 \(x\) 个点的连通块恰有 \(y\) 个黑点" ...
- 求两个Linux文本文件的交集、差集、并集
一.交集 sort a.txt b.txt | uniq -d 二.并集 sort a.txt b.txt | uniq 三.差集 a.txt-b.txt: sort a.txt b.txt b.tx ...
- hadoop学习笔记(五):HDFS Shell命令
一.HDFS文件命令 以下是比较重要的一些命令: [root@master01 hadoop]# hadoop fs -ls / //查看根目录下的所有文件 [root@master01 hadoop ...
- httpSession的正确理解
关于HttpSession的误解实在是太多了,本来是一个很简单的问题,怎会搞的如此的复杂呢?下面说说我的理解吧: 一个session就是一系列某用户和服务器间的通讯.服务器有能力分辨出不同的用户.一个 ...
- Unity主线程和子线程跳转调用(2)
在上一篇介绍了多线程和Unity交互方式,但是由于我的项目是一个unity编辑器插件项目,很显然上一篇的代码需要加以修改,在编辑器下实现Loom. 1,Editor下的没有Update这个生命周期函数 ...
- spring boot获取request
1. Controller中 1.1 通过静态方法获取 HttpServletRequest request = ((ServletRequestAttributes)RequestContextHo ...
- HDU 1142
A Walk Through the Forest Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Jav ...