RabbitMQ学习笔记(五、RabbitMQ集群)
目录:
- RabbitMQ集群
- 镜像队列
- RabbitMQ服务日志
- RabbitMQ分布式部署
- 高可用集群
RabbitMQ集群:
1、集群中组件的状态
首先MQ一定要是一个高可用的中间件所以集群肯定是必不可少的,它可以提高RabbitMQ的吞吐量。
那你可能会问RabbitMQ集群后消息就不会丢失了么?会丢失的,当一个节点崩溃后所有的消息都会丢失,因为RabbitMQ默认是不会将消息在集群中复制的。
队列在集群中如何存在:队列在集群中是不会复制的,其它节点只会保存队列所处的元数据。
交换器在集群中如何存在:交换器再集群中会复制,因为它本身也只是一个类似于Hashmap的映射关系。
建议:集群中至少要有一个磁盘节点(也就是持久化的RabbitMQ节点),虽然磁盘节点挂掉了依然可以发送和接受消息,但却不能执行创建队列、交换器、绑定关系等等操作。高可用的话建议至少两个磁盘节点,如果不确认如何选择磁盘节点与内存节点时建议全部选择磁盘节点,但这样的话会在一定程度上影响RabbitMQ的吞吐量。
2、单机多节点集群(自己玩玩时使用,不建议在生产环境中使用)
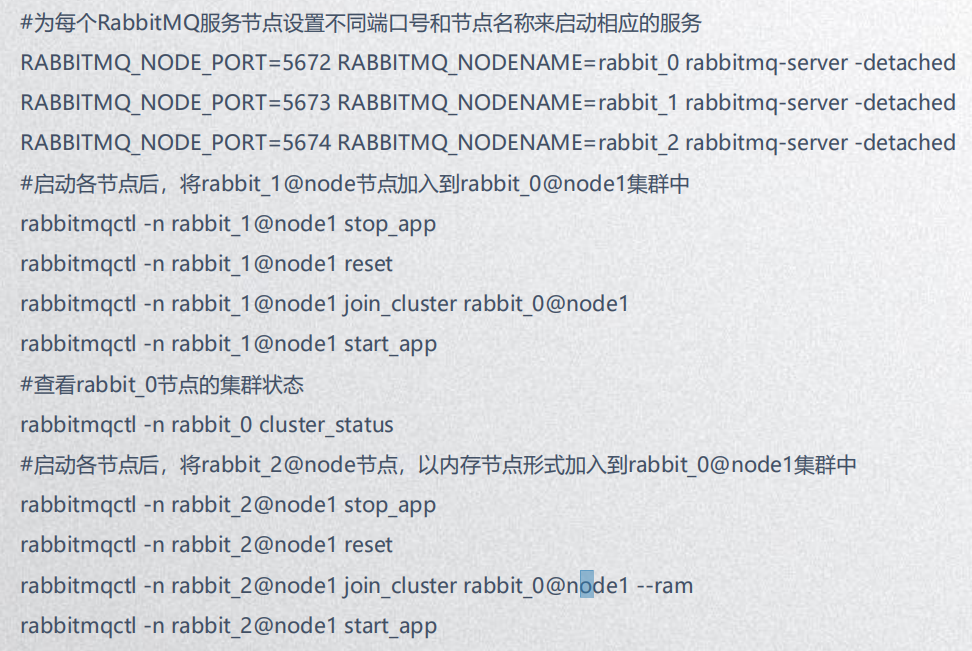
3、多机多节点集群

4、集群管理

镜像队列:
如果RabbitMQ中只有一个broker节点的话,那么在节点宕机后会有短暂的时间无法提供服务,可能会导致消息的丢失。
所以RabbitMQ引入了镜像队列这一概念,它可以将队列镜像的复制到其它的broker上,当集群中一个节点失效后便会将队列切换到另一个节点上去,从而保障服务的可用性。
设置镜像队列:rabbitmqctl set_policy --priority 0 --apply-to queues mirror_queue "^demo." '{"ha-mode":" exactly","ha-params":3, "ha-sync-mode":"automatic"}'
ha-mode:
- all:及群众所有节点都进行镜像。
- exactly:指定个数节点上进行镜像,ha-params为指定个数。
- nodes:指定节点上进行镜像,ha-params为指定节点名称。
RabbitMQ服务日志:
日志存放路径:$RABBITMQ_HOME/var/log/rabbitmq/log-name
RabbitMQ分布式部署:
RabbitMQ实现高可用的方式一般是集群+镜像队列,但这种基于镜像队列来实现的方式在多机房夸区域的环境下,可能会因为网络原因导致无法成功镜像成功。
针对因这一情况,可以使用对网络要求不高的Federation/Shovel来实现高可用。
Federation:
1、将两个节点的federation插件开启
rabbitmq-plugins enable rabbitmq_federation_management
2、在broker2中定义一个upstream
rabbitmqctl set_parameter federation-upstream f1 '{"uri":"amqp://account:password@ip:port","ack-mode":"on-confirm"}'
3、在broker2中定义一一个Policy
rabbitmqctl set_ policy --apply-to exchanges p1 "demo.exchange" '{"federation-upstream":"f1"}'
Shovel:
1、开启每个节点的shovel插件
rabbitmq-plugins enable rabbitmq_ shovel_ management
2、部署Shovel
rabbitmqctl set_parameter shovel hidden_shovel \'{"src-uri":"amqp://account:password@ip:port","src-queue":"demo.queue","dest-uri":"amqp://account:password@ip:port","src-exchange-key":"rk2","prefetch-count":64,"reconnect-delay":5,"publish-properties":[],"add-forward-headers":true,"ack-mode":"on-confirm"}'
格式化后:
rabbitmqctl set_parameter shovel hidden_shovel \'{
"src-uri": "amqp://account:password@ip:port",
"src-queue": "demo.queue",
"dest-uri": "amqp://account:password@ip:port",
"src-exchange-key": "rk2",
"prefetch-count": 64,
"reconnect-delay": 5,
"publish-properties": [],
"add-forward-headers": true,
"ack-mode": "on-confirm"
}'
高可用集群(负载均衡算法实现):
1、客户端本地实现:用代码实现本地轮询法、加权轮询法、随即法、哈希地址法、最小连接数法等等。
2、HAProxy负载均衡
3、Keepalived + HAProxy高可用负载均衡:光使用HAProxy时,当HAProxy挂掉了后整个RabbitMQ集群都无法正常提供服务,所以用Keepalived的主备机制进一步优化。
RabbitMQ学习笔记(五、RabbitMQ集群)的更多相关文章
- Redis学习笔记八:集群模式
作者:Grey 原文地址:Redis学习笔记八:集群模式 前面提到的Redis学习笔记七:主从复制和哨兵只能解决Redis的单点压力大和单点故障问题,接下来要讲的Redis Cluster模式,主要是 ...
- ZooKeeper学习笔记一:集群搭建
作者:Grey 原文地址:ZooKeeper学习笔记一:集群搭建 说明 单机版的zk安装和运行参考:https://zookeeper.apache.org/doc/r3.6.3/zookeeperS ...
- RabbitMQ学习笔记五:RabbitMQ之优先级消息队列
RabbitMQ优先级队列注意点: 1.只有当消费者不足,不能及时进行消费的情况下,优先级队列才会生效 2.RabbitMQ3.5以后才支持优先级队列 代码在博客:RabbitMQ学习笔记三:Java ...
- redis 学习笔记(6)-cluster集群搭建
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞shardi ...
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- Redis学习笔记~conf自主集群模式
回到目录 Redis自主提供了集群模式,当然也只是比较简单的读写分离模式,或者叫主从模式,它在各个redis服务端自己做数据同步机制,当然就是将主服务端的信息同步到各个slave服务器上,在客户端集成 ...
- 开源流媒体服务器SRS学习笔记(4) - Cluster集群方案
单台服务器做直播,总归有单点风险,利用SRS的Forward机制 + Edge Server设计,可以很容易搭建一个大规模的高可用集群,示意图如下 源站服务器集群:origin server clus ...
- K8S学习笔记之CentOS7集群使用Chrony实现时间同步
0x00 概述 容器集群对时间同步要求高,实际使用环境中必须确保集群中所有系统时间保持一致,openstack官方也推荐使用chrony代替ntp做时间同步. Chrony是一个开源的自由软件,像Ce ...
- Nginx学习笔记---服务与集群
一.集群 什么是集群 服务器架构集群:多台服务器组成的响应式大并发,高数据量访问的架构体系. 特点: (1)成本高 (2)能够降低单台服务器的压力,使用流量平均分配到多台服务器 (3)使网站服务架构更 ...
随机推荐
- mysql的锁机制详解
这段时间一直在学习mysql数据库.项目组一直用的是oracle,所以对mysql的了解也不深.本文主要是对mysql锁的总结. Mysql的锁主要分为3大类: 表级锁:存储引擎为Myisam.锁住整 ...
- [转]uipath orchestrator installation
本文转自:https://dotnetbasic.com/2019/08/uipath-orchestrator-installation.html UiPath Orchestrator Insta ...
- library: Vulnhub Walkthrough
网络主机探测: 端口主机扫描: ╰─ nmap -p1-65535 -sV -A -O -sT 10.10.202.136 21/tcp open ftp vsftpd 3.0.380/tcp ope ...
- 苹果_公司开发者账号_申请DUNS number
申请DUNS number 注意事项:a.公司英文名称,例如:北京京城科技有限公司,Beijing Jingcheng Technology Co., Ltd.(Co.和Ltd.都是缩写,中间用“逗号 ...
- 2、nio的例子实践
下面的例子,说明了,nio中的三大核心类的基本使用.buffer,channel,selector package com.shengsiyuan.nio; import org.junit.Test ...
- 初级模拟电路:4-1 BJT交流分析概述
回到目录 BJT晶体管的交流分析(也叫小信号分析)是模拟电路中的一个难点,也可以说是模电中的一个分水岭.如果你能够把BJT交流分析的原理全都搞懂,那之后的学习就是一马平川了.后面的大部分内容,诸如:场 ...
- Cocos2d-x开发教程——《萝莉快跑》
更好的阅读体验请前往<萝莉快跑>开发教程. 配置:win7+Cocos2d-x.2.0.3+VS2012 目标读者:已经了解图形显示.动作.回调函数.定时器的用法. 一.基本知识点 1.动 ...
- 第十六届浙江大学宁波理工学院程序设计大赛 D 雷顿女士与分队hard version(dp)
题意 链接:https://ac.nowcoder.com/acm/contest/2995/D来源:牛客网 卡特莉接到来自某程序设计竞赛集训队的邀请,来为他们进行分队规划. 现在集训队共有n名选手, ...
- pymysql用法,Python连接MySQL数据库
Pymysql模块是专门用来操作mysql数据库的模块,使用前需要安装,安装指令:pip install pymysql 操作流程: 第一步:import pymysql 第二步:获取数据库的连接 , ...
- [PHP]关于连接MySQL的问题
概述 PHP中无论使用MySQL函数抑或PDO连接MySQL服务器,都允许有两种方式,一是通过TCP网络层,一是通过unix socket: PHP并没有给出指明用何种方式去连接数据库,决定使用何种方 ...