DBCP2的使用例子和源码详解(不包括JNDI和JTA支持的使用)
简介
DBCP用于创建和管理连接,利用“池”的方式复用连接减少资源开销,和其他连接池一样,也具有连接数控制、连接有效性检测、连接泄露控制、缓存语句等功能。目前,tomcat自带的连接池就是DBCP,Spring开发组也推荐使用DBCP,阿里的druid也是参照DBCP开发出来的。
DBCP除了我们熟知的使用方式外,还支持通过JNDI获取数据源,并支持获取JTA或XA事务中用于2PC(两阶段提交)的连接对象,本文也将以例子说明。
本文将包含以下内容(因为篇幅较长,可根据需要选择阅读):
DBCP的使用方法(入门案例说明);DBCP的配置参数详解;DBCP主要源码分析;DBCP其他特性的使用方法,如JNDI和JTA支持。
使用例子
需求
使用DBCP连接池获取连接对象,对用户数据进行简单的增删改查。
工程环境
JDK:1.8.0_201
maven:3.6.1
IDE:eclipse 4.12
mysql-connector-java:8.0.15
mysql:5.7.28
DBCP:2.6.0
主要步骤
编写
dbcp.properties,设置数据库连接参数和连接池基本参数等。通过
BasicDataSourceFactory加载dbcp.properties,并获得BasicDataDource对象。通过
BasicDataDource对象获取Connection对象。使用
Connection对象对用户表进行增删改查。
创建项目
项目类型Maven Project,打包方式war(其实jar也可以,之所以使用war是为了测试JNDI)。
引入依赖
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- dbcp -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.6.0</version>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- mysql驱动的jar包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
编写dbcp.prperties
路径resources目录下,因为是入门例子,这里仅给出数据库连接参数和连接池基本参数,后面源码会对配置参数进行详细说明。另外,数据库sql脚本也在该目录下。
#连接基本属性
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
#-------------连接池大小和连接超时参数--------------------------------
#初始化连接数量:连接池启动时创建的初始化连接数量
#默认为0
initialSize=0
#最大活动连接数量:连接池在同一时间能够分配的最大活动连接的数量, 如果设置为负数则表示不限制
#默认为8
maxTotal=8
#最大空闲连接:连接池中容许保持空闲状态的最大连接数量,超过的空闲连接将被释放,如果设置为负数表示不限制
#默认为8
maxIdle=8
#最小空闲连接:连接池中容许保持空闲状态的最小连接数量,低于这个数量将创建新的连接,如果设置为0则不创建
#注意:timeBetweenEvictionRunsMillis为正数时,这个参数才能生效。
#默认为0
minIdle=0
#最大等待时间
#当没有可用连接时,连接池等待连接被归还的最大时间(以毫秒计数),超过时间则抛出异常,如果设置为<=0表示无限等待
#默认-1
maxWaitMillis=-1
获取连接池和获取连接
项目中编写了JDBCUtils来初始化连接池、获取连接和释放资源等,具体参见项目源码。
路径:cn.zzs.dbcp
// 导入配置文件
Properties properties = new Properties();
InputStream in = JDBCUtil.class.getClassLoader().getResourceAsStream("dbcp.properties");
properties.load(in);
// 根据配置文件内容获得数据源对象
DataSource dataSource = BasicDataSourceFactory.createDataSource(properties);
// 获得连接
Connection conn = dataSource.getConnection();
编写测试类
这里以保存用户为例,路径test目录下的cn.zzs.dbcp。
@Test
public void save() throws SQLException {
// 创建sql
String sql = "insert into demo_user values(null,?,?,?,?,?)";
Connection connection = null;
PreparedStatement statement = null;
try {
// 获得连接
connection = JDBCUtils.getConnection();
// 开启事务设置非自动提交
connection.setAutoCommit(false);
// 获得Statement对象
statement = connection.prepareStatement(sql);
// 设置参数
statement.setString(1, "zzf003");
statement.setInt(2, 18);
statement.setDate(3, new Date(System.currentTimeMillis()));
statement.setDate(4, new Date(System.currentTimeMillis()));
statement.setBoolean(5, false);
// 执行
statement.executeUpdate();
// 提交事务
connection.commit();
} finally {
// 释放资源
JDBCUtils.release(connection, statement, null);
}
}
配置文件详解
这部分内容从网上参照过来,同样的内容发的到处都是,暂时没找到出处。因为内容太过杂乱,而且最新版本更新了不少内容,所以我花了好大功夫才改好,后面找到出处再补上参考资料吧。
基本连接属性
注意,这里在url后面拼接了多个参数用于避免乱码、时区报错问题。 补充下,如果不想加入时区的参数,可以在mysql命令窗口执行如下命令:set global time_zone='+8:00'。
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
连接池大小参数
这几个参数都比较常用,具体设置多少需根据项目调整。
#-------------连接池大小和连接超时参数--------------------------------
#初始化连接数量:连接池启动时创建的初始化连接数量
#默认为0
initialSize=0
#最大活动连接数量:连接池在同一时间能够分配的最大活动连接的数量, 如果设置为负数则表示不限制
#默认为8
maxTotal=8
#最大空闲连接:连接池中容许保持空闲状态的最大连接数量,超过的空闲连接将被释放,如果设置为负数表示不限制
#默认为8
maxIdle=8
#最小空闲连接:连接池中容许保持空闲状态的最小连接数量,低于这个数量将创建新的连接,如果设置为0则不创建
#注意:timeBetweenEvictionRunsMillis为正数时,这个参数才能生效。
#默认为0
minIdle=0
#最大等待时间
#当没有可用连接时,连接池等待连接被归还的最大时间(以毫秒计数),超过时间则抛出异常,如果设置为<=0表示无限等待
#默认-1
maxWaitMillis=-1
#连接池创建的连接的默认的数据库名,如果是使用DBCP的XA连接必须设置,不然注册不了多个资源管理器
#defaultCatalog=github_demo
#连接池创建的连接的默认的schema。如果是mysql,这个设置没什么用。
#defaultSchema=github_demo
缓存语句
缓存语句在mysql下建议关闭。
#-------------缓存语句--------------------------------
#是否缓存preparedStatement,也就是PSCache。
#PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭
#默认为false
poolPreparedStatements=false
#缓存PreparedStatements的最大个数
#默认为-1
#注意:poolPreparedStatements为true时,这个参数才有效
maxOpenPreparedStatements=-1
#缓存read-only和auto-commit状态。设置为true的话,所有连接的状态都会是一样的。
#默认是true
cacheState=true
连接检查参数
针对连接失效和连接泄露的问题,建议开启testWhileIdle,而不是开启testOnReturn或testOnBorrow(从性能考虑)。
#-------------连接检查情况--------------------------------
#通过SQL查询检测连接,注意必须返回至少一行记录
#默认为空。即会调用Connection的isValid和isClosed进行检测
#注意:如果是oracle数据库的话,应该改为select 1 from dual
validationQuery=select 1 from dual
#SQL检验超时时间
validationQueryTimeout=-1
#是否从池中取出连接前进行检验。
#默认为true
testOnBorrow=true
#是否在归还到池中前进行检验
#默认为false
testOnReturn=false
#是否开启空闲资源回收器。
#默认为false
testWhileIdle=false
#空闲资源的检测周期(单位为毫秒)。
#默认-1。即空闲资源回收器不工作。
timeBetweenEvictionRunsMillis=-1
#做空闲资源回收器时,每次的采样数。
#默认3,单位毫秒。如果设置为-1,就是对所有连接做空闲监测。
numTestsPerEvictionRun=3
#资源池中资源最小空闲时间(单位为毫秒),达到此值后将被移除。
#默认值1000*60*30 = 30分钟
minEvictableIdleTimeMillis=1800000
#资源池中资源最小空闲时间(单位为毫秒),达到此值后将被移除。但是会保证minIdle
#默认值-1
#softMinEvictableIdleTimeMillis=-1
#空闲资源回收策略
#默认org.apache.commons.pool2.impl.DefaultEvictionPolicy
#如果要自定义的话,需要实现EvictionPolicy重写evict方法
evictionPolicyClassName=org.apache.commons.pool2.impl.DefaultEvictionPolicy
#连接最大存活时间。非正数表示不限制
#默认-1
maxConnLifetimeMillis=-1
#当达到maxConnLifetimeMillis被关闭时,是否打印相关消息
#默认true
#注意:maxConnLifetimeMillis设置为正数时,这个参数才有效
logExpiredConnections=true
事务相关参数
这里的参数主要和事务相关,一般默认就行。
#-------------事务相关的属性--------------------------------
#连接池创建的连接的默认的auto-commit状态
#默认为空,由驱动决定
defaultAutoCommit=true
#连接池创建的连接的默认的read-only状态。
#默认值为空,由驱动决定
defaultReadOnly=false
#连接池创建的连接的默认的TransactionIsolation状态
#可用值为下列之一:NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
#默认值为空,由驱动决定
defaultTransactionIsolation=REPEATABLE_READ
#归还连接时是否设置自动提交为true
#默认true
autoCommitOnReturn=true
#归还连接时是否设置回滚事务
#默认true
rollbackOnReturn=true
连接泄漏回收参数
当我们从连接池获得了连接对象,但因为疏忽或其他原因没有close,这个时候这个连接对象就是一个泄露资源。通过配置以下参数可以回收这部分对象。
#-------------连接泄漏回收参数--------------------------------
#当未使用的时间超过removeAbandonedTimeout时,是否视该连接为泄露连接并删除(当getConnection()被调用时检测)
#默认为false
#注意:这个机制在(getNumIdle() < 2) and (getNumActive() > (getMaxActive() - 3))时被触发
removeAbandonedOnBorrow=false
#当未使用的时间超过removeAbandonedTimeout时,是否视该连接为泄露连接并删除(空闲evictor检测)
#默认为false
#注意:当空闲资源回收器开启才生效
removeAbandonedOnMaintenance=false
#泄露的连接可以被删除的超时值, 单位秒
#默认为300
removeAbandonedTimeout=300
#标记当Statement或连接被泄露时是否打印程序的stack traces日志。
#默认为false
logAbandoned=true
#这个不是很懂
#默认为false
abandonedUsageTracking=false
其他
这部分参数比较少用。
#-------------其他--------------------------------
#是否使用快速失败机制
#默认为空,由驱动决定
fastFailValidation=false
#当使用快速失败机制时,设置触发的异常码
#多个code用","隔开
#disconnectionSqlCodes
#borrow连接的顺序
#默认true
lifo=true
#每个连接创建时执行的语句
#connectionInitSqls=
#连接参数:例如username、password、characterEncoding等都可以在这里设置
#多个参数用";"隔开
#connectionProperties=
#指定数据源的jmx名。注意,配置了才能注册MBean
jmxName=cn.zzs.jmx:type=BasicDataSource,name=zzs001
#查询超时时间
#默认为空,即根据驱动设置
#defaultQueryTimeout=
#控制PoolGuard是否容许获取底层连接
#默认为false
accessToUnderlyingConnectionAllowed=false
#如果容许则可以使用下面的方式来获取底层物理连接:
# Connection conn = ds.getConnection();
# Connection dconn = ((DelegatingConnection) conn).getInnermostDelegate();
# ...
# conn.close();
源码分析
注意:考虑篇幅和可读性,以下代码经过删减,仅保留所需部分。
创建数据源和连接池
研究之前,先来看下BasicDataSource的UML图:
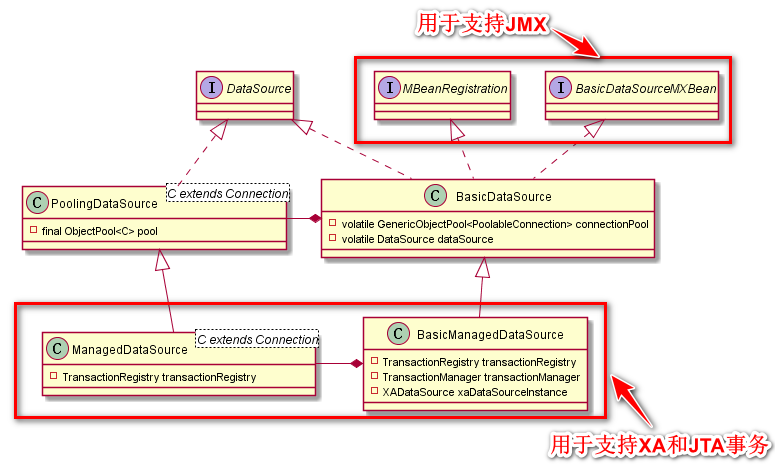
这里介绍下这几个类的作用:
| 类名 | 描述 |
|---|---|
BasicDataSource |
用于满足基本数据库操作需求的数据源 |
BasicManagedDataSource |
BasicDataSource的子类,用于创建支持XA事务或JTA事务的连接 |
PoolingDataSource |
BasicDataSource中实际调用的数据源,可以说BasicDataSource只是封装了PoolingDataSource |
ManagedDataSource |
PoolingDataSource的子类,用于支持XA事务或JTA事务的连接。是BasicManagedDataSource中实际调用的数据源,可以说BasicManagedDataSource只是封装了ManagedDataSource |
另外,为了支持JNDI,DBCP也提供了相应的类。
| 类名 | 描述 |
|---|---|
InstanceKeyDataSource |
用于支持JDNI环境的数据源 |
PerUserPoolDataSource |
InstanceKeyDataSource的子类,针对每个用户会单独分配一个连接池,每个连接池可以设置不同属性。例如以下需求,相比user,admin可以创建更多地连接以保证 |
SharedPoolDataSource |
InstanceKeyDataSource的子类,不同用户共享一个连接池 |
本文的源码分析仅会涉及到BasicDataSource(包含它封装的PoolingDataSource),其他的数据源暂时不扩展。
BasicDataSource.getConnection()
BasicDataSourceFactory.createDataSource(Properties)只是简单地new了一个BasicDataSource对象并初始化配置参数,此时真正的数据源(PoolingDataSource)以及连接池(GenericObjectPool)并没有创建,而创建的时机为我们第一次调用getConnection()的时候,如下:
public Connection getConnection() throws SQLException {
return createDataSource().getConnection();
}
但是,当我们设置了 initialSize > 0,则在BasicDataSourceFactory.createDataSource(Properties)时就会完成数据源和连接池的初始化。感谢moranshouwang的指正。
当然,过程都是相同的,只是时机不一样。下面从BasicDataSource的createDataSource()方法开始分析。
BasicDataSource.createDataSource()
这个方法会创建数据源和连接池,整个过程可以概括为以下几步:
- 注册
MBean,用于支持JMX; - 创建连接池对象
GenericObjectPool<PoolableConnection>; - 创建数据源对象
PoolingDataSource<PoolableConnection>; - 初始化连接数;
- 开启空闲资源回收线程(如果设置
timeBetweenEvictionRunsMillis为正数)。
protected DataSource createDataSource() throws SQLException {
if(closed) {
throw new SQLException("Data source is closed");
}
if(dataSource != null) {
return dataSource;
}
synchronized(this) {
if(dataSource != null) {
return dataSource;
}
// 注册MBean,用于支持JMX,这方面的内容不在这里扩展
jmxRegister();
// 创建原生Connection工厂:本质就是持有数据库驱动对象和几个连接参数
final ConnectionFactory driverConnectionFactory = createConnectionFactory();
// 将driverConnectionFactory包装成池化Connection工厂
PoolableConnectionFactory poolableConnectionFactory = createPoolableConnectionFactory(driverConnectionFactory);
// 设置PreparedStatements缓存(其实在这里可以发现,上面创建池化工厂时就设置了缓存,这里没必要再设置一遍)
poolableConnectionFactory.setPoolStatements(poolPreparedStatements);
poolableConnectionFactory.setMaxOpenPreparedStatements(maxOpenPreparedStatements);
// 创建数据库连接池对象GenericObjectPool,用于管理连接
// BasicDataSource将持有GenericObjectPool对象
createConnectionPool(poolableConnectionFactory);
// 创建PoolingDataSource对象
// 该对象持有GenericObjectPool对象的引用
DataSource newDataSource = createDataSourceInstance();
newDataSource.setLogWriter(logWriter);
// 根据我们设置的initialSize创建初始连接
for(int i = 0; i < initialSize; i++) {
connectionPool.addObject();
}
// 开启连接池的evictor线程
startPoolMaintenance();
// 最后BasicDataSource将持有上面创建的PoolingDataSource对象
dataSource = newDataSource;
return dataSource;
}
}
以上方法涉及到几个类,这里再补充下UML图。
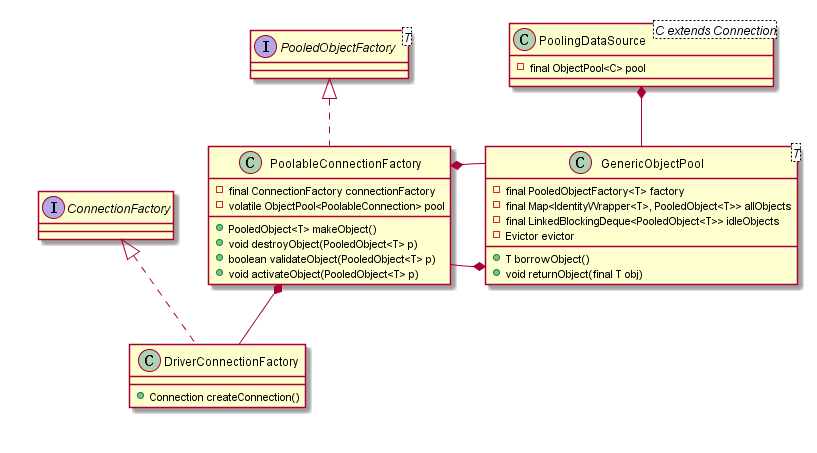
| 类名 | 描述 |
|---|---|
DriverConnectionFactory |
用于生成原生的Connection对象 |
PoolableConnectionFactory |
用于生成池化的Connection对象,持有ConnectionFactory对象的引用 |
GenericObjectPool |
数据库连接池,用于管理连接。持有PoolableConnectionFactory对象的引用 |
获取连接对象
上面已经大致分析了数据源和连接池对象的获取过程,接下来研究下连接对象的获取。在此之前先了解下DBCP中几个Connection实现类。
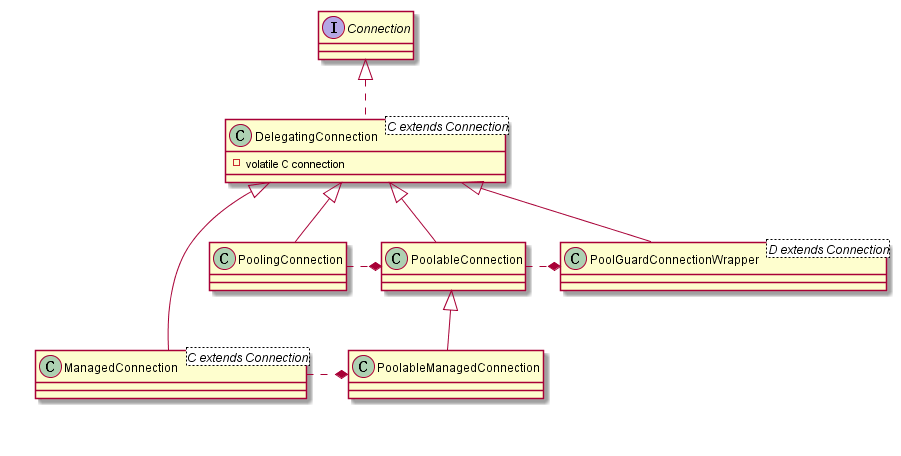
| 类名 | 描述 |
|---|---|
DelegatingConnection |
Connection实现类,是以下几个类的父类 |
PoolingConnection |
用于包装原生的Connection,支持缓存prepareStatement和prepareCall |
PoolableConnection |
用于包装原生的PoolingConnection(如果没有开启poolPreparedStatements,则包装的只是原生Connection),调用close()时只是将连接还给连接池 |
PoolableManagedConnection |
PoolableConnection的子类,用于包装ManagedConnection,支持JTA和XA事务 |
ManagedConnection |
用于包装原生的Connection,支持JTA和XA事务 |
PoolGuardConnectionWrapper |
用于包装PoolableConnection,当accessToUnderlyingConnectionAllowed才能获取底层连接对象。我们获取到的就是这个对象 |
另外,这里先概括下获得连接的整个过程:
- 如果设置了
removeAbandonedOnBorrow,达到条件会进行检测; - 从连接池中获取连接,如果没有就通过工厂创建(通过
DriverConnectionFactory创建原生对象,再通过PoolableConnectionFactory包装为池化对象); - 通过工厂重新初始化连接对象;
- 如果设置了
testOnBorrow或者testOnCreate,会通过工厂校验连接有效性; - 使用
PoolGuardConnectionWrapper包装连接对象,并返回给客户端
PoolingDataSource.getConnection()
前面已经说过,BasicDataSource本质上是调用PoolingDataSource的方法来获取连接,所以这里从PoolingDataSource.getConnection()开始研究。
以下代码可知,该方法会从连接池中“借出”连接。
public Connection getConnection() throws SQLException {
// 这个泛型C指的是PoolableConnection对象
// 调用的是GenericObjectPool的方法返回PoolableConnection对象,这个方法后面会展开
final C conn = pool.borrowObject();
if (conn == null) {
return null;
}
// 包装PoolableConnection对象,当accessToUnderlyingConnectionAllowed为true时,可以使用底层连接
return new PoolGuardConnectionWrapper<>(conn);
}
GenericObjectPool.borrowObject()
GenericObjectPool是一个很简练的类,里面涉及到的属性设置和锁机制都涉及得非常巧妙。
// 存放着连接池所有的连接对象(但不包含已经释放的)
private final Map<IdentityWrapper<T>, PooledObject<T>> allObjects =
new ConcurrentHashMap<>();
// 存放着空闲连接对象的阻塞队列
private final LinkedBlockingDeque<PooledObject<T>> idleObjects;
// 为n>1表示当前有n个线程正在创建新连接对象
private long makeObjectCount = 0;
// 创建连接对象时所用的锁
private final Object makeObjectCountLock = new Object();
// 连接对象创建总数量
private final AtomicLong createCount = new AtomicLong(0);
public T borrowObject() throws Exception {
// 如果我们设置了连接获取等待时间,“借出”过程就必须在指定时间内完成
return borrowObject(getMaxWaitMillis());
}
public T borrowObject(final long borrowMaxWaitMillis) throws Exception {
// 校验连接池是否打开状态
assertOpen();
// 如果设置了removeAbandonedOnBorrow,达到触发条件是会遍历所有连接,未使用时长超过removeAbandonedTimeout的将被释放掉(一般可以检测出泄露连接)
final AbandonedConfig ac = this.abandonedConfig;
if (ac != null && ac.getRemoveAbandonedOnBorrow() &&
(getNumIdle() < 2) &&
(getNumActive() > getMaxTotal() - 3) ) {
removeAbandoned(ac);
}
PooledObject<T> p = null;
// 连接数达到maxTotal是否阻塞等待
final boolean blockWhenExhausted = getBlockWhenExhausted();
boolean create;
final long waitTime = System.currentTimeMillis();
// 如果获取的连接对象为空,会再次进入获取
while (p == null) {
create = false;
// 获取空闲队列的第一个元素,如果为空就试图创建新连接
p = idleObjects.pollFirst();
if (p == null) {
// 后面分析这个方法
p = create();
if (p != null) {
create = true;
}
}
// 连接数达到maxTotal且暂时没有空闲连接,这时需要阻塞等待,直到获得空闲队列中的连接或等待超时
if (blockWhenExhausted) {
if (p == null) {
if (borrowMaxWaitMillis < 0) {
// 无限等待
p = idleObjects.takeFirst();
} else {
// 等待maxWaitMillis
p = idleObjects.pollFirst(borrowMaxWaitMillis,
TimeUnit.MILLISECONDS);
}
}
// 这个时候还是没有就只能抛出异常
if (p == null) {
throw new NoSuchElementException(
"Timeout waiting for idle object");
}
} else {
if (p == null) {
throw new NoSuchElementException("Pool exhausted");
}
}
// 如果连接处于空闲状态,会修改连接的state、lastBorrowTime、lastUseTime、borrowedCount等,并返回true
if (!p.allocate()) {
p = null;
}
if (p != null) {
// 利用工厂重新初始化连接对象,这里会去校验连接存活时间、设置lastUsedTime、及其他初始参数
try {
factory.activateObject(p);
} catch (final Exception e) {
try {
destroy(p);
} catch (final Exception e1) {
// Ignore - activation failure is more important
}
p = null;
if (create) {
final NoSuchElementException nsee = new NoSuchElementException(
"Unable to activate object");
nsee.initCause(e);
throw nsee;
}
}
// 根据设置的参数,判断是否检测连接有效性
if (p != null && (getTestOnBorrow() || create && getTestOnCreate())) {
boolean validate = false;
Throwable validationThrowable = null;
try {
// 这里会去校验连接的存活时间是否超过maxConnLifetimeMillis,以及通过SQL去校验执行时间
validate = factory.validateObject(p);
} catch (final Throwable t) {
PoolUtils.checkRethrow(t);
validationThrowable = t;
}
// 如果校验不通过,会释放该对象
if (!validate) {
try {
destroy(p);
destroyedByBorrowValidationCount.incrementAndGet();
} catch (final Exception e) {
// Ignore - validation failure is more important
}
p = null;
if (create) {
final NoSuchElementException nsee = new NoSuchElementException(
"Unable to validate object");
nsee.initCause(validationThrowable);
throw nsee;
}
}
}
}
}
// 更新borrowedCount、idleTimes和waitTimes
updateStatsBorrow(p, System.currentTimeMillis() - waitTime);
return p.getObject();
}
GenericObjectPool.create()
这里在创建连接对象时采用的锁机制非常值得学习,简练且高效。
private PooledObject<T> create() throws Exception {
int localMaxTotal = getMaxTotal();
if (localMaxTotal < 0) {
localMaxTotal = Integer.MAX_VALUE;
}
final long localStartTimeMillis = System.currentTimeMillis();
final long localMaxWaitTimeMillis = Math.max(getMaxWaitMillis(), 0);
// 创建标识:
// - TRUE: 调用工厂创建返回对象
// - FALSE: 直接返回null
// - null: 继续循环
Boolean create = null;
while (create == null) {
synchronized (makeObjectCountLock) {
final long newCreateCount = createCount.incrementAndGet();
if (newCreateCount > localMaxTotal) {
// 当前池已经达到maxTotal,或者有另外一个线程正在试图创建一个新的连接使之达到容量极限
createCount.decrementAndGet();
if (makeObjectCount == 0) {
// 连接池确实已达到容量极限
create = Boolean.FALSE;
} else {
// 当前另外一个线程正在试图创建一个新的连接使之达到容量极限,此时需要等待
makeObjectCountLock.wait(localMaxWaitTimeMillis);
}
} else {
// 当前连接池容量未到达极限,可以继续创建连接对象
makeObjectCount++;
create = Boolean.TRUE;
}
}
// 当达到maxWaitTimeMillis时不创建连接对象,直接退出循环
if (create == null &&
(localMaxWaitTimeMillis > 0 &&
System.currentTimeMillis() - localStartTimeMillis >= localMaxWaitTimeMillis)) {
create = Boolean.FALSE;
}
}
if (!create.booleanValue()) {
return null;
}
final PooledObject<T> p;
try {
// 调用工厂创建对象,后面对这个方法展开分析
p = factory.makeObject();
} catch (final Throwable e) {
createCount.decrementAndGet();
throw e;
} finally {
synchronized (makeObjectCountLock) {
// 创建标识-1
makeObjectCount--;
// 唤醒makeObjectCountLock锁住的对象
makeObjectCountLock.notifyAll();
}
}
final AbandonedConfig ac = this.abandonedConfig;
if (ac != null && ac.getLogAbandoned()) {
p.setLogAbandoned(true);
// TODO: in 3.0, this can use the method defined on PooledObject
if (p instanceof DefaultPooledObject<?>) {
((DefaultPooledObject<T>) p).setRequireFullStackTrace(ac.getRequireFullStackTrace());
}
}
// 连接数量+1
createdCount.incrementAndGet();
// 将创建的对象放入allObjects
allObjects.put(new IdentityWrapper<>(p.getObject()), p);
return p;
}
PoolableConnectionFactory.makeObject()
public PooledObject<PoolableConnection> makeObject() throws Exception {
// 创建原生的Connection对象
Connection conn = connectionFactory.createConnection();
if (conn == null) {
throw new IllegalStateException("Connection factory returned null from createConnection");
}
try {
// 执行我们设置的connectionInitSqls
initializeConnection(conn);
} catch (final SQLException sqle) {
// Make sure the connection is closed
try {
conn.close();
} catch (final SQLException ignore) {
// ignore
}
// Rethrow original exception so it is visible to caller
throw sqle;
}
// 连接索引+1
final long connIndex = connectionIndex.getAndIncrement();
// 如果设置了poolPreparedStatements,则创建包装连接为PoolingConnection对象
if (poolStatements) {
conn = new PoolingConnection(conn);
final GenericKeyedObjectPoolConfig<DelegatingPreparedStatement> config = new GenericKeyedObjectPoolConfig<>();
config.setMaxTotalPerKey(-1);
config.setBlockWhenExhausted(false);
config.setMaxWaitMillis(0);
config.setMaxIdlePerKey(1);
config.setMaxTotal(maxOpenPreparedStatements);
if (dataSourceJmxObjectName != null) {
final StringBuilder base = new StringBuilder(dataSourceJmxObjectName.toString());
base.append(Constants.JMX_CONNECTION_BASE_EXT);
base.append(Long.toString(connIndex));
config.setJmxNameBase(base.toString());
config.setJmxNamePrefix(Constants.JMX_STATEMENT_POOL_PREFIX);
} else {
config.setJmxEnabled(false);
}
final PoolingConnection poolingConn = (PoolingConnection) conn;
final KeyedObjectPool<PStmtKey, DelegatingPreparedStatement> stmtPool = new GenericKeyedObjectPool<>(
poolingConn, config);
poolingConn.setStatementPool(stmtPool);
poolingConn.setCacheState(cacheState);
}
// 用于注册连接到JMX
ObjectName connJmxName;
if (dataSourceJmxObjectName == null) {
connJmxName = null;
} else {
connJmxName = new ObjectName(
dataSourceJmxObjectName.toString() + Constants.JMX_CONNECTION_BASE_EXT + connIndex);
}
// 创建PoolableConnection对象
final PoolableConnection pc = new PoolableConnection(conn, pool, connJmxName, disconnectionSqlCodes,
fastFailValidation);
pc.setCacheState(cacheState);
// 包装成连接池所需的对象
return new DefaultPooledObject<>(pc);
}
空闲对象回收器Evictor
以上基本已分析完连接对象的获取过程,下面再研究下空闲对象回收器。前面已经讲到当创建完数据源对象时会开启连接池的evictor线程,所以我们从BasicDataSource.startPoolMaintenance()开始分析。
BasicDataSource.startPoolMaintenance()
前面说过timeBetweenEvictionRunsMillis为非正数时不会开启开启空闲对象回收器,从以下代码可以理解具体逻辑。
protected void startPoolMaintenance() {
// 只有timeBetweenEvictionRunsMillis为正数,才会开启空闲对象回收器
if (connectionPool != null && timeBetweenEvictionRunsMillis > 0) {
connectionPool.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
}
}
BaseGenericObjectPool.setTimeBetweenEvictionRunsMillis(long)
这个BaseGenericObjectPool是上面说到的GenericObjectPool的父类。
public final void setTimeBetweenEvictionRunsMillis(
final long timeBetweenEvictionRunsMillis) {
// 设置回收线程运行间隔时间
this.timeBetweenEvictionRunsMillis = timeBetweenEvictionRunsMillis;
// 继续调用本类的方法,下面继续进入方法分析
startEvictor(timeBetweenEvictionRunsMillis);
}
BaseGenericObjectPool.startEvictor(long)
这里会去定义一个Evictor对象,这个其实是一个Runnable对象,后面会讲到。
final void startEvictor(final long delay) {
synchronized (evictionLock) {
if (null != evictor) {
EvictionTimer.cancel(evictor, evictorShutdownTimeoutMillis, TimeUnit.MILLISECONDS);
evictor = null;
evictionIterator = null;
}
// 创建回收器任务,并执行定时调度
if (delay > 0) {
evictor = new Evictor();
EvictionTimer.schedule(evictor, delay, delay);
}
}
}
EvictionTimer.schedule(Evictor, long, long)
DBCP是使用ScheduledThreadPoolExecutor来实现回收器的定时检测。 涉及到ThreadPoolExecutor为JDK自带的api,这里不再深入分析线程池如何实现定时调度。感兴趣的朋友可以复习下常用的几款线程池。
static synchronized void schedule(
final BaseGenericObjectPool<?>.Evictor task, final long delay, final long period)
if (null == executor) {
// 创建线程池,队列为DelayedWorkQueue,corePoolSize为1,maximumPoolSize为无限大
executor = new ScheduledThreadPoolExecutor(1, new EvictorThreadFactory());
// 当任务被取消的同时从等待队列中移除
executor.setRemoveOnCancelPolicy(true);
}
// 设置任务定时调度
final ScheduledFuture<?> scheduledFuture =
executor.scheduleWithFixedDelay(task, delay, period, TimeUnit.MILLISECONDS);
task.setScheduledFuture(scheduledFuture);
}
BaseGenericObjectPool.Evictor
Evictor是BaseGenericObjectPool的内部类,实现了Runnable接口,这里看下它的run方法。
class Evictor implements Runnable {
private ScheduledFuture<?> scheduledFuture;
@Override
public void run() {
final ClassLoader savedClassLoader =
Thread.currentThread().getContextClassLoader();
try {
// 确保回收器使用的类加载器和工厂对象的一样
if (factoryClassLoader != null) {
final ClassLoader cl = factoryClassLoader.get();
if (cl == null) {
cancel();
return;
}
Thread.currentThread().setContextClassLoader(cl);
}
try {
// 回收符合条件的对象,后面继续扩展
evict();
} catch(final Exception e) {
swallowException(e);
} catch(final OutOfMemoryError oome) {
// Log problem but give evictor thread a chance to continue
// in case error is recoverable
oome.printStackTrace(System.err);
}
try {
// 确保最小空闲对象
ensureMinIdle();
} catch (final Exception e) {
swallowException(e);
}
} finally {
Thread.currentThread().setContextClassLoader(savedClassLoader);
}
}
void setScheduledFuture(final ScheduledFuture<?> scheduledFuture) {
this.scheduledFuture = scheduledFuture;
}
void cancel() {
scheduledFuture.cancel(false);
}
}
GenericObjectPool.evict()
这里的回收过程包括以下四道校验:
按照
evictionPolicy校验idleSoftEvictTime、idleEvictTime;利用工厂重新初始化样本,这里会校验
maxConnLifetimeMillis(testWhileIdle为true);校验
maxConnLifetimeMillis和validationQueryTimeout(testWhileIdle为true);校验所有连接的未使用时间是否超过r
emoveAbandonedTimeout(removeAbandonedOnMaintenance为true)。
public void evict() throws Exception {
// 校验当前连接池是否关闭
assertOpen();
if (idleObjects.size() > 0) {
PooledObject<T> underTest = null;
// 介绍参数时已经讲到,这个evictionPolicy我们可以自定义
final EvictionPolicy<T> evictionPolicy = getEvictionPolicy();
synchronized (evictionLock) {
final EvictionConfig evictionConfig = new EvictionConfig(
getMinEvictableIdleTimeMillis(),
getSoftMinEvictableIdleTimeMillis(),
getMinIdle());
final boolean testWhileIdle = getTestWhileIdle();
// 获取我们指定的样本数,并开始遍历
for (int i = 0, m = getNumTests(); i < m; i++) {
if (evictionIterator == null || !evictionIterator.hasNext()) {
evictionIterator = new EvictionIterator(idleObjects);
}
if (!evictionIterator.hasNext()) {
// Pool exhausted, nothing to do here
return;
}
try {
underTest = evictionIterator.next();
} catch (final NoSuchElementException nsee) {
// 当前样本正被另一个线程借出
i--;
evictionIterator = null;
continue;
}
// 判断如果样本是空闲状态,设置为EVICTION状态
// 如果不是,说明另一个线程已经借出了这个样本
if (!underTest.startEvictionTest()) {
i--;
continue;
}
boolean evict;
try {
// 调用回收策略来判断是否回收该样本,按照默认策略,以下情况都会返回true:
// 1. 样本空闲时间大于我们设置的idleSoftEvictTime,且当前池中空闲连接数量>minIdle
// 2. 样本空闲时间大于我们设置的idleEvictTime
evict = evictionPolicy.evict(evictionConfig, underTest,
idleObjects.size());
} catch (final Throwable t) {
PoolUtils.checkRethrow(t);
swallowException(new Exception(t));
evict = false;
}
// 如果需要回收,则释放这个样本
if (evict) {
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
} else {
// 如果设置了testWhileIdle,会
if (testWhileIdle) {
boolean active = false;
try {
// 利用工厂重新初始化样本,这里会校验maxConnLifetimeMillis
factory.activateObject(underTest);
active = true;
} catch (final Exception e) {
// 抛出异常标识校验不通过,释放样本
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
}
if (active) {
// 接下来会校验maxConnLifetimeMillis和validationQueryTimeout
if (!factory.validateObject(underTest)) {
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
} else {
try {
// 这里会将样本rollbackOnReturn、autoCommitOnReturn等
factory.passivateObject(underTest);
} catch (final Exception e) {
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
}
}
}
}
// 如果状态为EVICTION或EVICTION_RETURN_TO_HEAD,修改为IDLE
if (!underTest.endEvictionTest(idleObjects)) {
//空
}
}
}
}
}
// 校验所有连接的未使用时间是否超过removeAbandonedTimeout
final AbandonedConfig ac = this.abandonedConfig;
if (ac != null && ac.getRemoveAbandonedOnMaintenance()) {
removeAbandoned(ac);
}
}
以上已基本研究完数据源创建、连接对象获取和空闲资源回收器,后续有空再做补充。
通过JNDI获取数据源对象
需求
本文测试使用JNDI获取PerUserPoolDataSource和SharedPoolDataSource对象,选择使用tomcat 9.0.21作容器。
如果之前没有接触过JNDI,并不会影响下面例子的理解,其实可以理解为像spring的bean配置和获取。
源码分析时已经讲到,除了我们熟知的BasicDataSource,DBCP还提供了通过JDNI获取数据源,如下表。
| 类名 | 描述 |
|---|---|
InstanceKeyDataSource |
用于支持JDNI环境的数据源,是以下两个类的父类 |
PerUserPoolDataSource |
InstanceKeyDataSource的子类,针对每个用户会单独分配一个连接池,每个连接池可以设置不同属性。例如以下需求,相比user,admin可以创建更多地连接以保证 |
SharedPoolDataSource |
InstanceKeyDataSource的子类,不同用户共享一个连接池 |
引入依赖
本文在前面例子的基础上增加以下依赖,因为是web项目,所以打包方式为war:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>javax.servlet.jsp-api</artifactId>
<version>2.2.1</version>
<scope>provided</scope>
</dependency>
编写context.xml
在webapp文件下创建目录META-INF,并创建context.xml文件。这里面的每个resource节点都是我们配置的对象,类似于spring的bean节点。其中bean/DriverAdapterCPDS这个对象需要被另外两个使用到。
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<Resource
name="bean/SharedPoolDataSourceFactory"
auth="Container"
type="org.apache.commons.dbcp2.datasources.SharedPoolDataSource"
factory="org.apache.commons.dbcp2.datasources.SharedPoolDataSourceFactory"
singleton="false"
driverClassName="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true"
username="root"
password="root"
maxTotal="8"
maxIdle="10"
dataSourceName="java:comp/env/bean/DriverAdapterCPDS"
/>
<Resource
name="bean/PerUserPoolDataSourceFactory"
auth="Container"
type="org.apache.commons.dbcp2.datasources.PerUserPoolDataSource"
factory="org.apache.commons.dbcp2.datasources.PerUserPoolDataSourceFactory"
singleton="false"
driverClassName="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true"
username="root"
password="root"
maxTotal="8"
maxIdle="10"
dataSourceName="java:comp/env/bean/DriverAdapterCPDS"
/>
<Resource
name="bean/DriverAdapterCPDS"
auth="Container"
type="org.apache.commons.dbcp2.cpdsadapter.DriverAdapterCPDS"
factory="org.apache.commons.dbcp2.cpdsadapter.DriverAdapterCPDS"
singleton="false"
driverClassName="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true"
userName="root"
userPassword="root"
maxIdle="10"
/>
</Context>
编写web.xml
在web-app节点下配置资源引用,每个resource-env-ref指向了我们配置好的对象。
<resource-env-ref>
<description>Test DriverAdapterCPDS</description>
<resource-env-ref-name>bean/DriverAdapterCPDS</resource-env-ref-name>
<resource-env-ref-type>org.apache.commons.dbcp2.cpdsadapter.DriverAdapterCPDS</resource-env-ref-type>
</resource-env-ref>
<resource-env-ref>
<description>Test SharedPoolDataSource</description>
<resource-env-ref-name>bean/SharedPoolDataSourceFactory</resource-env-ref-name>
<resource-env-ref-type>org.apache.commons.dbcp2.datasources.SharedPoolDataSource</resource-env-ref-type>
</resource-env-ref>
<resource-env-ref>
<description>Test erUserPoolDataSource</description>
<resource-env-ref-name>bean/erUserPoolDataSourceFactory</resource-env-ref-name>
<resource-env-ref-type>org.apache.commons.dbcp2.datasources.erUserPoolDataSource</resource-env-ref-type>
</resource-env-ref>
编写jsp
因为需要在web环境中使用,如果直接建类写个main方法测试,会一直报错的,目前没找到好的办法。这里就简单地使用jsp来测试吧(这是从tomcat官网参照的例子)。
<body>
<%
// 获得名称服务的上下文对象
Context initCtx = new InitialContext();
Context envCtx = (Context)initCtx.lookup("java:comp/env/");
// 查找指定名字的对象
DataSource ds = (DataSource)envCtx.lookup("bean/SharedPoolDataSourceFactory");
DataSource ds2 = (DataSource)envCtx.lookup("bean/PerUserPoolDataSourceFactory");
// 获取连接
Connection conn = ds.getConnection("root","root");
System.out.println("conn" + conn);
Connection conn2 = ds2.getConnection("zzf","zzf");
System.out.println("conn2" + conn2);
// ... 使用连接操作数据库,以及释放资源 ...
conn.close();
conn2.close();
%>
</body>
测试结果
打包项目在tomcat9上运行,访问 http://localhost:8080/DBCP-demo/testInstanceKeyDataSource.jsp ,控制台打印如下内容:
conn=1971654708, URL=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true, UserName=root@localhost, MySQL Connector/J
conn2=128868782, URL=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true, UserName=zzf@localhost, MySQL Connector/J
使用DBCP测试两阶段提交
前面源码分析已经讲到,以下类用于支持JTA事务。本文将介绍如何使用DBCP来实现JTA事务两阶段提交(当然,实际项目并不支持使用2PC,因为性能开销太大)。
| 类名 | 描述 |
|---|---|
BasicManagedDataSource |
BasicDataSource的子类,用于创建支持XA事务或JTA事务的连接 |
ManagedDataSource |
PoolingDataSource的子类,用于支持XA事务或JTA事务的连接。是BasicManagedDataSource中实际调用的数据源,可以说BasicManagedDataSource只是封装了ManagedDataSource |
准备工作
因为测试例子使用的是mysql,使用XA事务需要开启支持。注意,mysql只有innoDB引擎才支持(另外,XA事务和常规事务是互斥的,如果开启了XA事务,其他线程进来即使只读也是不行的)。
SHOW VARIABLES LIKE '%xa%' -- 查看XA事务是否开启
SET innodb_support_xa = ON -- 开启XA事务
除了原来的github_demo数据库,我另外建了一个test数据库,简单地模拟两个数据库。
mysql的XA事务使用
测试之前,这里简单回顾下直接使用sql操作XA事务的过程,将有助于对以下内容的理解:
XA START 'my_test_xa'; -- 启动一个xid为my_test_xa的事务,并使之为active状态
UPDATE github_demo.demo_user SET deleted = 1 WHERE id = '1'; -- 事务中的语句
XA END 'my_test_xa'; -- 把事务置为idle状态
XA PREPARE 'my_test_xa'; -- 把事务置为prepare状态
XA COMMIT 'my_test_xa'; -- 提交事务
XA ROLLBACK 'my_test_xa'; -- 回滚事务
XA RECOVER; -- 查看处于prepare状态的事务列表
引入依赖
在入门例子的基础上,增加以下依赖,本文采用第三方atomikos的实现。
<!-- jta:用于测试DBCP对JTA事务的支持 -->
<dependency>
<groupId>javax.transaction</groupId>
<artifactId>jta</artifactId>
<version>1.1</version>
</dependency>
<dependency>
<groupId>com.atomikos</groupId>
<artifactId>transactions-jdbc</artifactId>
<version>3.9.3</version>
</dependency>
获取BasicManagedDataSource
这里千万记得要设置DefaultCatalog,否则当前事务中注册不同资源管理器时,可能都会被当成同一个资源管理器而拒绝注册并报错,因为这个问题,花了我好长时间才解决。
public BasicManagedDataSource getBasicManagedDataSource(
TransactionManager transactionManager,
String url,
String username,
String password) {
BasicManagedDataSource basicManagedDataSource = new BasicManagedDataSource();
basicManagedDataSource.setTransactionManager(transactionManager);
basicManagedDataSource.setUrl(url);
basicManagedDataSource.setUsername(username);
basicManagedDataSource.setPassword(password);
basicManagedDataSource.setDefaultAutoCommit(false);
basicManagedDataSource.setXADataSource("com.mysql.cj.jdbc.MysqlXADataSource");
return basicManagedDataSource;
}
@Test
public void test01() throws Exception {
// 获得事务管理器
TransactionManager transactionManager = new UserTransactionManager();
// 获取第一个数据库的数据源
BasicManagedDataSource basicManagedDataSource1 = getBasicManagedDataSource(
transactionManager,
"jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true",
"root",
"root");
// 注意,这一步非常重要
basicManagedDataSource1.setDefaultCatalog("github_demo");
// 获取第二个数据库的数据源
BasicManagedDataSource basicManagedDataSource2 = getBasicManagedDataSource(
transactionManager,
"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true",
"zzf",
"zzf");
// 注意,这一步非常重要
basicManagedDataSource1.setDefaultCatalog("test");
}
编写两阶段提交的代码
通过运行代码可以发现,当数据库1和2的操作都成功,才会提交,只要其中一个数据库执行失败,两个操作都会回滚。
@Test
public void test01() throws Exception {
Connection connection1 = null;
Statement statement1 = null;
Connection connection2 = null;
Statement statement2 = null;
transactionManager.begin();
try {
// 获取连接并进行数据库操作,这里会将会将XAResource注册到当前线程的XA事务对象
/**
* XA START xid1;-- 启动一个事务,并使之为active状态
*/
connection1 = basicManagedDataSource1.getConnection();
statement1 = connection1.createStatement();
/**
* update github_demo.demo_user set deleted = 1 where id = '1'; -- 事务中的语句
*/
boolean result1 = statement1.execute("update github_demo.demo_user set deleted = 1 where id = '1'");
System.out.println(result1);
/**
* XA START xid2;-- 启动一个事务,并使之为active状态
*/
connection2 = basicManagedDataSource2.getConnection();
statement2 = connection2.createStatement();
/**
* update test.demo_user set deleted = 1 where id = '1'; -- 事务中的语句
*/
boolean result2 = statement2.execute("update test.demo_user set deleted = 1 where id = '1'");
System.out.println(result2);
/**
* 当这执行以下语句:
* XA END xid1; -- 把事务置为idle状态
* XA PREPARE xid1; -- 把事务置为prepare状态
* XA END xid2; -- 把事务置为idle状态
* XA PREPARE xid2; -- 把事务置为prepare状态
* XA COMMIT xid1; -- 提交事务
* XA COMMIT xid2; -- 提交事务
*/
transactionManager.commit();
} catch(Exception e) {
e.printStackTrace();
} finally {
statement1.close();
statement2.close();
connection1.close();
connection2.close();
}
}
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/12003922.html
DBCP2的使用例子和源码详解(不包括JNDI和JTA支持的使用)的更多相关文章
- dom4j的测试例子和源码详解(重点对比和DOM、SAX的区别)
目录 简介 DOM.SAX.JAXP和DOM4J xerces解释器 SAX DOM JAXP DOM解析器 获取SAX解析器 DOM4j 项目环境 工程环境 创建项目 引入依赖 使用例子--生成xm ...
- jdbc-mysql测试例子和源码详解
目录 简介 什么是JDBC 几个重要的类 使用中的注意事项 使用例子 需求 工程环境 主要步骤 创建表 创建项目 引入依赖 编写jdbc.prperties 获得Connection对象 使用Conn ...
- cglib测试例子和源码详解
目录 简介 为什么会有动态代理? 常见的动态代理有哪些? 什么是cglib 使用例子 需求 工程环境 主要步骤 创建项目 引入依赖 编写被代理类 编写MethodInterceptor接口实现类 编写 ...
- [Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
本课主题 CacheManager 运行原理图 CacheManager 源码解析 CacheManager 运行原理图 [下图是CacheManager的运行原理图] 首先 RDD 是通过 iter ...
- [Qt Creator 快速入门] 第2章 Qt程序编译和源码详解
一.编写 Hello World Gui程序 Hello World程序就是让应用程序显示"Hello World"字符串.这是最简单的应用,但却包含了一个应用程序的基本要素,所以 ...
- Spark Sort-Based Shuffle具体实现内幕和源码详解
为什么讲解Sorted-Based shuffle?2方面的原因:一,可能有些朋友看到Sorted-Based Shuffle的时候,会有一个误解,认为Spark基于Sorted-Based Shuf ...
- Arouter核心思路和源码详解
前言 阅读本文之前,建议读者: 对Arouter的使用有一定的了解. 对Apt技术有所了解. Arouter是一款Alibaba出品的优秀的路由框架,本文不对其进行全面的分析,只对其最重要的功能进行源 ...
- go map数据结构和源码详解
目录 1. 前言 2. go map的数据结构 2.1 核心结体体 2.2 数据结构图 3. go map的常用操作 3.1 创建 3.2 插入或更新 3.3 删除 3.4 查找 3.5 range迭 ...
- 源码详解系列(八) ------ 全面讲解HikariCP的使用和源码
简介 HikariCP 是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,和 dr ...
随机推荐
- Java 导出数据库表信息生成Word文档
一.前言 最近看见朋友写了一个导出数据库生成word文档的业务,感觉很有意思,研究了一下,这里也拿出来与大家分享一波~ 先来看看生成的word文档效果吧 下面我们也来一起简单的实现吧 二.Java 导 ...
- vue实现tab选项卡切换效果
tab选项卡切换效果: 通过点击事件传入参数,然后通过v-show来进行切换显示 <template> <div class="box"> <div ...
- python之小木马(文件上传,下载,调用命令行,按键监控记录)
window版 服务端: 开启两个线程,一个用来接收客户端的输入,一个用来监控服务端键盘的记录 客户端: get 文件(下载)put 文件(上传) window下cmd命令执行结果会直接打印出来,ke ...
- css3 input placeholder颜色修改方法
css3 input placeholder颜色修改方法<pre> input::-webkit-input-placeholder { /* placeholder颜色 */ color ...
- Hibernate中关于Query返回查询结果是类名的问题
query.list返回的是一个装有类的信息的集合,而不装有数据库信息的集合.如下图 运行结果为: 因为得到的集合是类,所以要将list泛型设为那个类,并且将得到的集合进行.get(x).getx ...
- [WPF] Caliburn Micro学习三 Binding
Caliburn Micro学习一 Installation Caliburn Micro学习二 Infrastructure 如果说WPF推崇的Binding开辟了一条UI开发新的方式——让写代码的 ...
- 插入排序的代码实现(C语言)
void insert_sort(int arr[], int len) { for (int i = 1; i < len; ++i) { if (arr[i] < arr[i - 1] ...
- Salesforce学习之路(十三)Aura案例实战分析
Aura相关知识整合: Salesforce学习之路(十)Aura组件工作原理 Salesforce学习之路(十一)Aura组件属性<aura:attribute /> Salesforc ...
- pat 1023 Have Fun with Numbers(20 分)
1023 Have Fun with Numbers(20 分) Notice that the number 123456789 is a 9-digit number consisting exa ...
- hdu 1874 畅通工程续 (floyd)
畅通工程续Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...