Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程
第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下

点击Network之后出现如下内容:

第二步:进入如下页面分析Network中的内容(网址、编码方式一般为gbk)


第三步:程序详细分析如下所示:
# _*_ utf-8 _*_:
# author:Administrator
from urllib import request #导入请求库,有的版本是import requests
import re #用于正则表达式
first_url="http://www.quanshuwang.com/book/9/9055" #你所需要下载的小说的网址
html=request.urlopen(first_url).read().decode('gbk') #上图箭头所示
novel_info={} #创建一个空的字典,注意不是空的集合序列
novel_info['title']=re.findall(r' <div class="chapName">.*<strong>(.*)</strong>',html) #()中的正则表达式,提取的内容放到novel_info里面 re.findall返回的是一个列表 而之后要把它转化为字符串处理 一定要注意那些是列表那些是字符串
novel_info['author']=re.findall(r' <div class="chapName"><span class="r">作者:(.*)</span><strong>盗墓笔记</strong><div class="clear"></div></div>',html)
div_info=re.findall(r'<DIV class="clearfix dirconone">(.*?)</DIV> ',html,re.S|re.I)[0] #此处在re.finall()返回一个序列,序列里只有一个元素,在后面加个[0]将他访问出来,转化为字符串,re.S|re.I不能丢否则得到空集
#获取每一个章节的地址
tag_a=re.findall(r'<a.*?</a>',div_info)
#循环每个章节依次获得内容
for i in range(0,60):
chapter_title = re.findall(r'title="(.*?)"', tag_a[i])[0]
chapter_url=re.findall(r'href="(.*?)"',tag_a[i])[0]
chapter_content=request.urlopen( chapter_url).read().decode('gbk') #与上面的思路一样
chapter_text = re.findall(r'<div class="mainContenr" (.*)style6', chapter_content, re.I | re.S)[0]
# print(chapter_content)
chapter_clear = chapter_text.replace(r" ", "") #都是清洗数据的步骤,可以依据具体环境而定
chapter_clear1 = chapter_clear.replace(r"<br />", "")
chapter_clear2 = chapter_clear1.replace(r'id="content"><script type="text/javascript">style5();</script>', "")
chapter_clear3 = chapter_clear2.replace(r'<script type="text/javascript">', "")
file = open(r'E:\老九门全书网.txt', 'a')
file.write(chapter_title+'\n'+chapter_clear3+'\n\n') #文件的读写操作
print(chapter_title)
file.close()
其他:
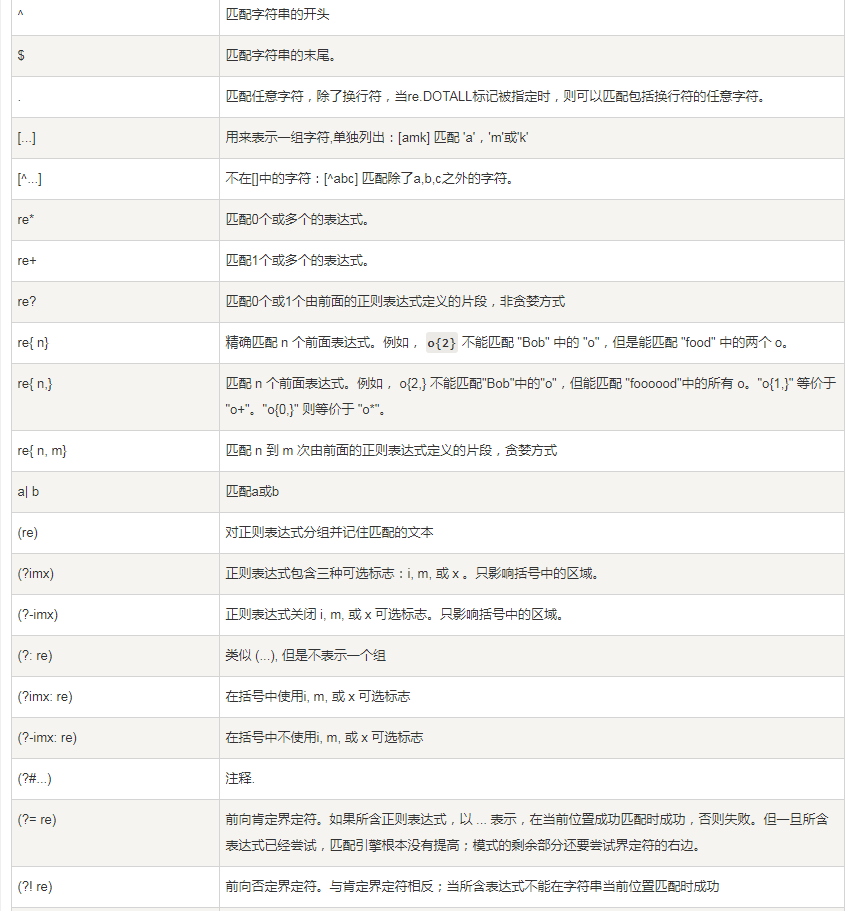
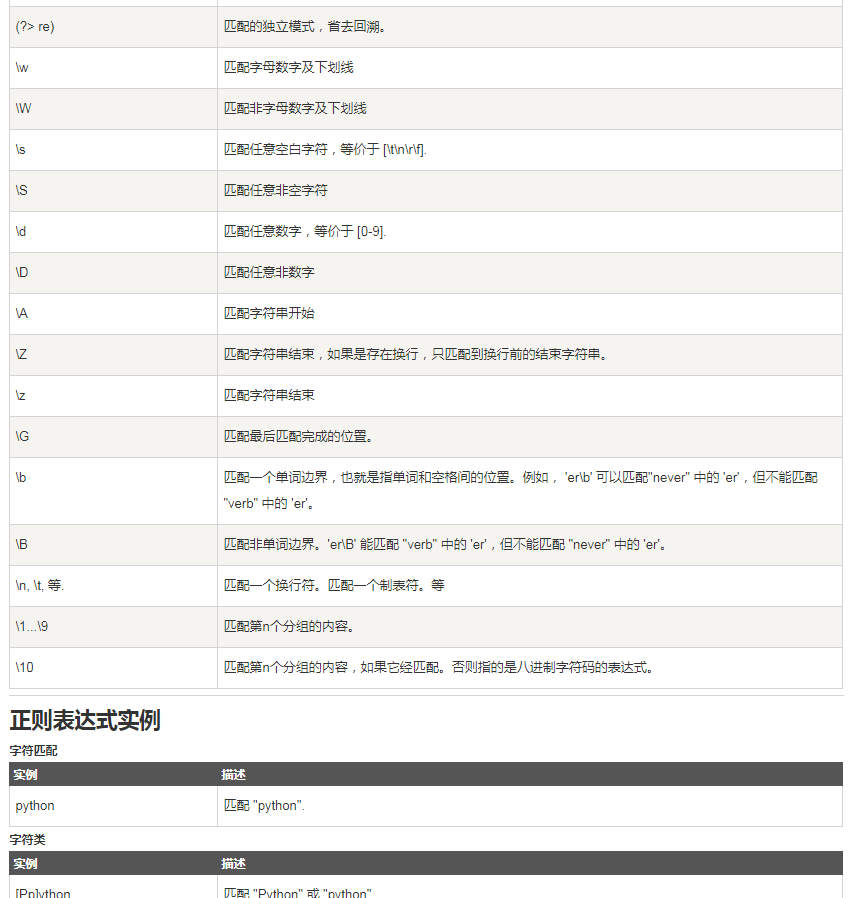
正则表达式附录:


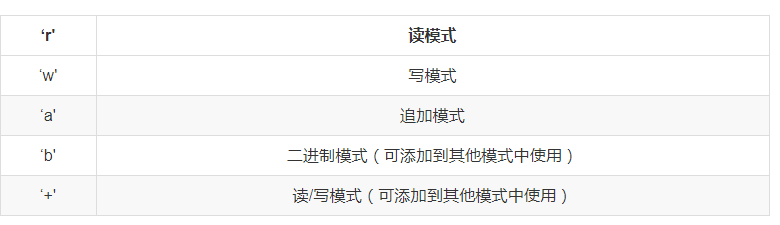
Python文件读写:
Python爬虫爬取全书网小说,程序源码+程序详细分析的更多相关文章
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- Python爬虫 爬取百合网的女人们和男人们
学Python也有段时间了,目前学到了Python的类.个人感觉Python的类不应称之为类,而应称之为数据类型,只是数据类型而已!只是数据类型而已!只是数据类型而已!重要的事情说三篇. 据书上说一个 ...
- python爬虫爬取赶集网数据
一.创建项目 scrapy startproject putu 二.创建spider文件 scrapy genspider patubole patubole.com 三.利用chrome浏览器 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
随机推荐
- 从flink-example分析flink组件(3)WordCount 流式实战及源码分析
前面介绍了批量处理的WorkCount是如何执行的 <从flink-example分析flink组件(1)WordCount batch实战及源码分析> <从flink-exampl ...
- springcloud-熔断监控Hystrix Dashboard和Turbine
作者:纯洁的微笑出处:http://www.ityouknow.com/ 版权归作者所有,转载请注明出处 Hystrix-dashboard是一款针对Hystrix进行实时监控的工具,通过Hystri ...
- Nginx安装(详细版本)
Nginx安装文档 前言: 最近,系统部署人员那边,让我们给写一个傻瓜式的Nginx安装过程.所以就有了这个文档,本着独乐乐不如众乐乐,就分享一下.我觉得对入门小白来说,有图,乃至运行过程图,是很重要 ...
- c#小灶——使用visual studio编写第一个程序
虽然,写程序有文本编辑器和编译器就已经足够,但是,我们为了增加工作效率还是要使用IDE. 我们接下来所有的教程都将会在visual studio中实现,visual studio简称vs,是微软开发的 ...
- c# 控制台console进度条
1 说明 笔者大多数的开发在 Linux 下,多处用到进度条的场景,但又无需用到图形化界面,所以就想着弄个 console 下的进度条显示. 2 步骤 清行显示 //清行处理操作 int curren ...
- HttpClientFactory 使用说明 及 对 HttpClient 的回顾和对比
目录 HttpClient 日常使用及坑点: HttpClientFactory 优势: HttpClientFactory 使用方法: 实战用法1:常规用法 1. 在 Startup.cs 中进行注 ...
- kube-scheduler源码分析
kubernetes集群三步安装 kube-scheduler源码分析 关于源码编译 我嫌弃官方提供的编译脚本太麻烦,所以用了更简单粗暴的方式编译k8s代码,当然官方脚本在编译所有项目或者夸平台编译以 ...
- 【C++】string::find函数
int vis=a.find(b):从string a开头开始查找第一个遇到的string b,返回string a中所匹配字符串的第一个字符的下标位置,找不到则返回-1. int vis=a.fin ...
- 算法与数据结构基础 - 位运算(Bit Manipulation)
位运算基础 说到与(&).或(|).非(~).异或(^).位移等位运算,就得说到位运算的各种奇淫巧技,下面分运算符说明. 1. 与(&) 计算式 a&b,a.b各位中同为 1 ...
- LeetCode——372. Super Pow
题目链接:https://leetcode.com/problems/super-pow/description/ Your task is to calculate ab mod 1337 wher ...