numba,让python速度提升百倍
python由于它动态解释性语言的特性,跑起代码来相比java、c++要慢很多,尤其在做科学计算的时候,十亿百亿级别的运算,让python的这种劣势更加凸显。
办法永远比困难多,numba就是解决python慢的一大利器,可以让python的运行速度提升上百倍!

什么是numba?
numba是一款可以将python函数编译为机器代码的JIT编译器,经过numba编译的python代码(仅限数组运算),其运行速度可以接近C或FORTRAN语言。
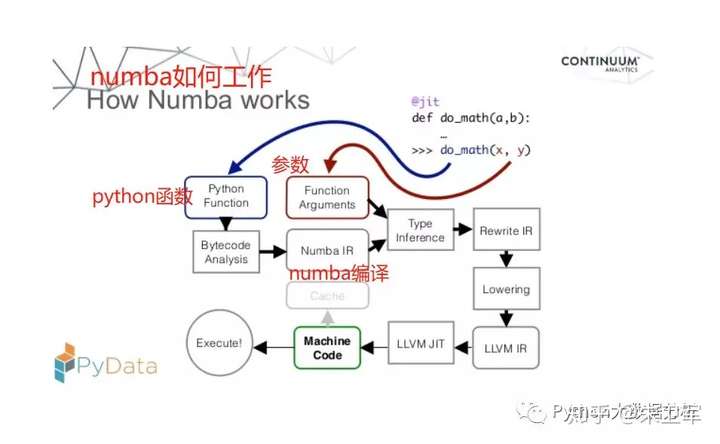
python之所以慢,是因为它是靠CPython编译的,numba的作用是给python换一种编译器。
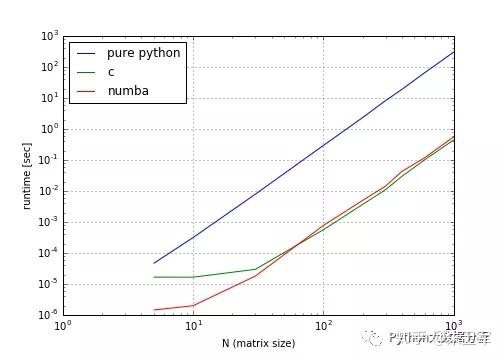
python、c、numba三种编译器速度对比
使用numba非常简单,只需要将numba装饰器应用到python函数中,无需改动原本的python代码,numba会自动完成剩余的工作。
import numpy as np
import numba
from numba import jit @jit(nopython=True) # jit,numba装饰器中的一种
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i])
return a + trace
以上代码是一个python函数,用以计算numpy数组各个数值的双曲正切值,我们使用了numba装饰器,它将这个python函数编译为等效的机器代码,可以大大减少运行时间。
numba适合科学计算
numpy是为面向numpy数组的计算任务而设计的。
在面向数组的计算任务中,数据并行性对于像GPU这样的加速器是很自然的。Numba了解NumPy数组类型,并使用它们生成高效的编译代码,用于在GPU或多核CPU上执行。特殊装饰器还可以创建函数,像numpy函数那样在numpy数组上广播。
什么情况下使用numba呢?
- 使用numpy数组做大量科学计算时
- 使用for循环时
学习使用numba
第一步:导入numpy、numba及其编译器
import numpy as np
import numba
from numba import jit
第二步:传入numba装饰器jit,编写函数
# 传入jit,numba装饰器中的一种
@jit(nopython=True)
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i]) # numba喜欢numpy函数
return a + trace # numba喜欢numpy广播
nopython = True选项要求完全编译该函数(以便完全删除Python解释器调用),否则会引发异常。这些异常通常表示函数中需要修改的位置,以实现优于Python的性能。强烈建议您始终使用nopython = True。
# 因为函数要求传入的参数是nunpy数组
x = np.arange(100).reshape(10, 10)
# 执行函数
go_fast(x)
第四步:经numba加速的函数执行时间
% timeit go_fast(x)
输出:3.63 µs ± 156 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
第五步:不经numba加速的函数执行时间
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i]) # numba喜欢numpy函数
return a + trace # numba喜欢numpy广播 x = np.arange(100).reshape(10, 10)
%timeit go_fast(x)
输出:136 µs ± 1.09 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
结论:
在numba加速下,代码执行时间为3.63微秒/循环。不经过numba加速,代码执行时间为136微秒/循环,两者相比,前者快了40倍。
numba让python飞起来
前面已经对比了numba使用前后,python代码速度提升了40倍,但这还不是最快的。
这次,我们不使用numpy数组,仅用for循环,看看nunba对for循环到底有多钟爱!
# 不使用numba的情况
def t():
x = 0
for i in np.arange(5000):
x += i
return x
%timeit(t())
输出:408 µs ± 9.73 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
# 使用numba的情况
@jit(nopython=True)
def t():
x = 0
for i in np.arange(5000):
x += i
return x
%timeit(t())
输出:1.57 µs ± 53.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
使用numba前后分别是408微秒/循环、1.57微秒/循环,速度整整提升了200多倍!
结语
numba对python代码运行速度有巨大的提升,这极大的促进了大数据时代的python数据分析能力,对数据科学工作者来说,这真是一个lucky tool !
当然numba不会对numpy和for循环以外的python代码有很大帮助,你不要指望numba可以帮你加快从数据库取数,这点它真的做不到哈。
如果大家想要学习更多的python数据分析知识,请关注我的公众号:pydatas
回复:数据分析,可领取《利用python进行数据分析 第二版》电子书

numba,让python速度提升百倍的更多相关文章
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- 如何将 iOS 工程打包速度提升十倍以上
如何将 iOS 工程打包速度提升十倍以上 过慢的编译速度有非常明显的副作用.一方面,程序员在等待打包的过程中可能会分心,比如刷刷朋友圈,看条新闻等等.这种认知上下文的切换会带来很多隐形的时间浪费. ...
- 阿里云maven仓库地址,速度提升100倍
参照:https://www.cnblogs.com/xxt19970908/p/6685777.html maven仓库用过的人都知道,国内有多么的悲催.还好有比较好用的镜像可以使用,尽快记录下来. ...
- 多伦多大学&NVIDIA最新成果:图像标注速度提升10倍!
图像标注速度提升10倍! 这是多伦多大学与英伟达联合公布的一项最新研究:Curve-GCN的应用结果. Curve-GCN是一种高效交互式图像标注方法,其性能优于Polygon-RNN++.在自动模式 ...
- Elasticsearch聚合优化 | 聚合速度提升5倍
https://blog.csdn.net/laoyang360/article/details/79253294 1.聚合为什么慢?大多数时候对单个字段的聚合查询还是非常快的, 但是当需要同时聚合多 ...
- 从 Webpack 到 Snowpack, 编译速度提升十倍以上——TRPG Engine迁移小记
动机 TRPG Engine经过长久以来的迭代,项目已经显得非常臃肿了.数分钟的全量编译, 每次按下保存都会触发一次10s到1m不等的增量编译让我苦不堪言, 庞大的依赖使其每一次编译都会涉及很多文件和 ...
- 使用 Apache Spark 让 MySQL 查询速度提升 10 倍以上
转: https://coyee.com/article/11012-how-apache-spark-makes-your-slow-mysql-queries-10x-faster-or-more ...
- 数据库 | SQL 诊断优化套路包,套路用的对,速度升百倍
本文出自头条号老王谈运维,转载请说明出处. 前言 在DBA的日常工作中,调整个别性能较差的SQL语句是一项富有挑战性的工作.面对慢SQL,一些DBA会心烦,会沮丧,会束手无措,也会沉着冷静.斗智斗勇! ...
- Java动态编译优化——提升编译速度(N倍)
一.前言 最近一直在研究Java8 的动态编译, 并且也被ZipFileIndex$Entry 内存泄漏所困扰,在无意中,看到一个第三方插件的动态编译.并且编译速度是原来的2-3倍.原本打算直接用这个 ...
随机推荐
- 爬虫之突破xm-sign校验反爬
喜马拉雅 网页分析 - 打开我们要爬取的音乐专辑https://www.ximalaya.com/ertong/424529/ - F12打开开发者工具 - 点击XHR 随便点击一首歌曲会看到存储所有 ...
- linux 安装命令 nginx 部署
[TOC] # 安装anocanda wget https://repo.anaconda.com/archive/Anaconda3-2019.03-Linux-x86_64.sh安装:bash A ...
- Spring:定时任务定时器 Quartz的使用
Quartz的使用方式 配置文件方式 一.引入依赖 <!-- spring 其他依赖省略 --> <!-- https://mvnrepository.com/artifact/or ...
- 小白开学Asp.Net Core 开篇
开学Asp.Net Core 开篇 一.准备工作 1.操作环境:Win10 2.开发工具:VS2019 3.运行环境:.Net Core 2.2 4.数据库:SqlServer2012 二.项目搭建 ...
- Html5web全栈前端开发_angular框架
昵称领取全套angular视频教程 一.Typescript typescript简称ts,是js语法的超集,很多js新的语法就借鉴了ts语法.ts是由微软团队维护的 1.1 TS简介 1.1.1 G ...
- Bellman-Ford 算法
根据之前最短路径算法里提到的,我们只要放松所有边直到其全部失效就可以得到最短路径 注意:图中不能有负圈.否则当负圈中某个点经过这个负圈的所有边的松弛操作后,这个点的的d[i]就会减小,此时会发现它可以 ...
- shiro 和 spring boot 的集成
1 添加依赖 使用 shiro-spring-boot-web-starter 在 spring boot 中集成 shiro 只需要再添加一个依赖 <dependency> <gr ...
- macvtap使用教程
kubernetes一键安装 macvtap是虚拟机网络虚拟化常用的一种技术,当然容器也可以用. MACVTAP 的实现基于传统的 MACVLAN. 和 TAP 设备一样,每一个 MACVTAP 设备 ...
- Hadoop 系列(一)—— 分布式文件系统 HDFS
一.介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错.高吞吐量等特性,可以部署在低成本的硬件上. 二.HDFS 设计原理 ...
- .net持续集成测试篇之Nunit 测试配置
系列目录 在开始之前我们先看一个陷阱 用到的Person类如下 public class Person:IPerson { public string Name { get; set; } publi ...