Spark 学习笔记之 Streaming Window
Streaming Window:
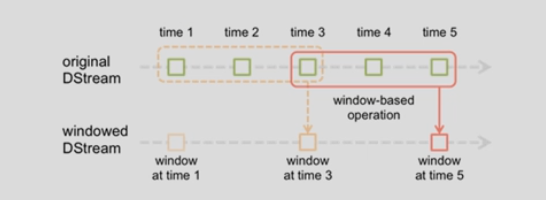
上图意思:每隔2秒统计前3秒的数据
slideDuration: 2
windowDuration: 3
例子:
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent object WindowStreaming { def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("KafkaDirect").setMaster("local[1]")
val ssc = new StreamingContext(conf, Seconds(1))
val kafkaMapParams = Map[String, Object](
"bootstrap.servers" -> "192.168.1.151:9092,192.168.1.152:9092,192.168.1.153:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "g1",
"auto.offset.reset" -> "latest", //earliest|latest
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topicsSet = Set("ScalaTopic")
val kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topicsSet, kafkaMapParams)
) val finalResultRDD: DStream[(Int, String)] = kafkaStream.flatMap(row => row.value().split(" "))
.map((_, 1)).reduceByKeyAndWindow((x: Int, y: Int) => x + y, Seconds(3), Seconds(2))
.transform(rdd => rdd.map(tuple => (tuple._2, tuple._1))
.sortByKey(false).map(tuple => (tuple._1, tuple._2))
) finalResultRDD.print() ssc.start()
ssc.awaitTermination()
} }
运行结果:

Spark 学习笔记之 Streaming Window的更多相关文章
- Spark 学习笔记之 Streaming和Kafka Direct
Streaming和Kafka Direct: Spark version: 2.2.0 Scala version: 2.11 Kafka version: 0.11.0.0 Note: 最新版本感 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
随机推荐
- hdu 6435 CSGO
题意:现在有n个主武器, m个副武器, 你要选择1个主武器,1个副武器, 使得 题目给定的那个式子最大. 题解:这个题目困难的地方就在于有绝对值,| a - b | 我们将绝对值去掉之后 他的值就为 ...
- LeetCode380 常数时间插入、删除和获取随机元素
LeetCode380 常数时间插入.删除和获取随机元素 题目要求 设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构. insert(val):当元素 val 不存在时,向集合中插 ...
- 手把手告诉你如何安装多个版本的node,妈妈再也不用担心版本高低引发的一系列后遗症(非常详细,非常实用)
简介 最近好多人都问到node怎么同时安装多个版本? 如何配置node的环境变量,如何自如的在多个版本中切换node?还有就是自己在做appium自动化的时候,有时候会因为node的版本过高或者是太低 ...
- zabbix监控nginx脚本
~]# cd /etc/zabbix/scripts/ scripts]# ls nginx_status.sh scripts]# cat nginx_status.sh ############# ...
- 5分钟理解 SpringBoot 响应式的核心-Reactor
目录 一.前言 二. Mono 与 Flux 构造器 三. 流计算 1. 缓冲 2. 过滤/提取 3. 转换 4. 合并 5. 合流 6. 累积 四.异常处理 五.线程调度 小结 参考阅读 一.前言 ...
- vim 高级功能
本文章原创首发于公众号:编程三分钟 ,文末二维码. 文本编辑.跳转.删除.复制.替换这些操作用vim确实是快:但是好像仅仅是这样根本不能说服我vim超过鼠标的地方. 花点时间弄熟这些,除了炫技意外,主 ...
- 人工智能-智能创意平台架构成长之路(四)-丰富多彩的banner图生成解密第一部分(对标阿里鹿班的设计)
我们之前讲了很多都是平台架构的主体设计,应用架构设计以及技术架构的设计,那么现在我们就来分享一下丰富多彩的banner图是怎么生成出来的. banner图的生成我们也是不断的进行迭代和优化,这块是最核 ...
- Redis常用命令(key、string、List)
1.Key 1.keys * 查询所有数据 2.exists key名 判断key名是否存在 3.move key名 数据库号(0-15) 移动数据key名到相应的数据库 4.expire ...
- JSP获取网络IP地址
import javax.servlet.http.HttpServletRequest; public class RemoteAddress { public static String getR ...
- 章节十六、9-Listeners监听器
一.IInokedMethodListener 1.实现一个类来监听testcase的运行情况. package listenerspackage; import org.testng.IInvoke ...