web scraper——爬取知乎|微博用户数据模板【三】
前言
在这里呢,我就只给模板,不写具体的教程啦,具体的可以参考我之前写的博文。
https://www.cnblogs.com/wangyang0210/p/10338574.html
模板
进入微博选择粉丝较多的博主
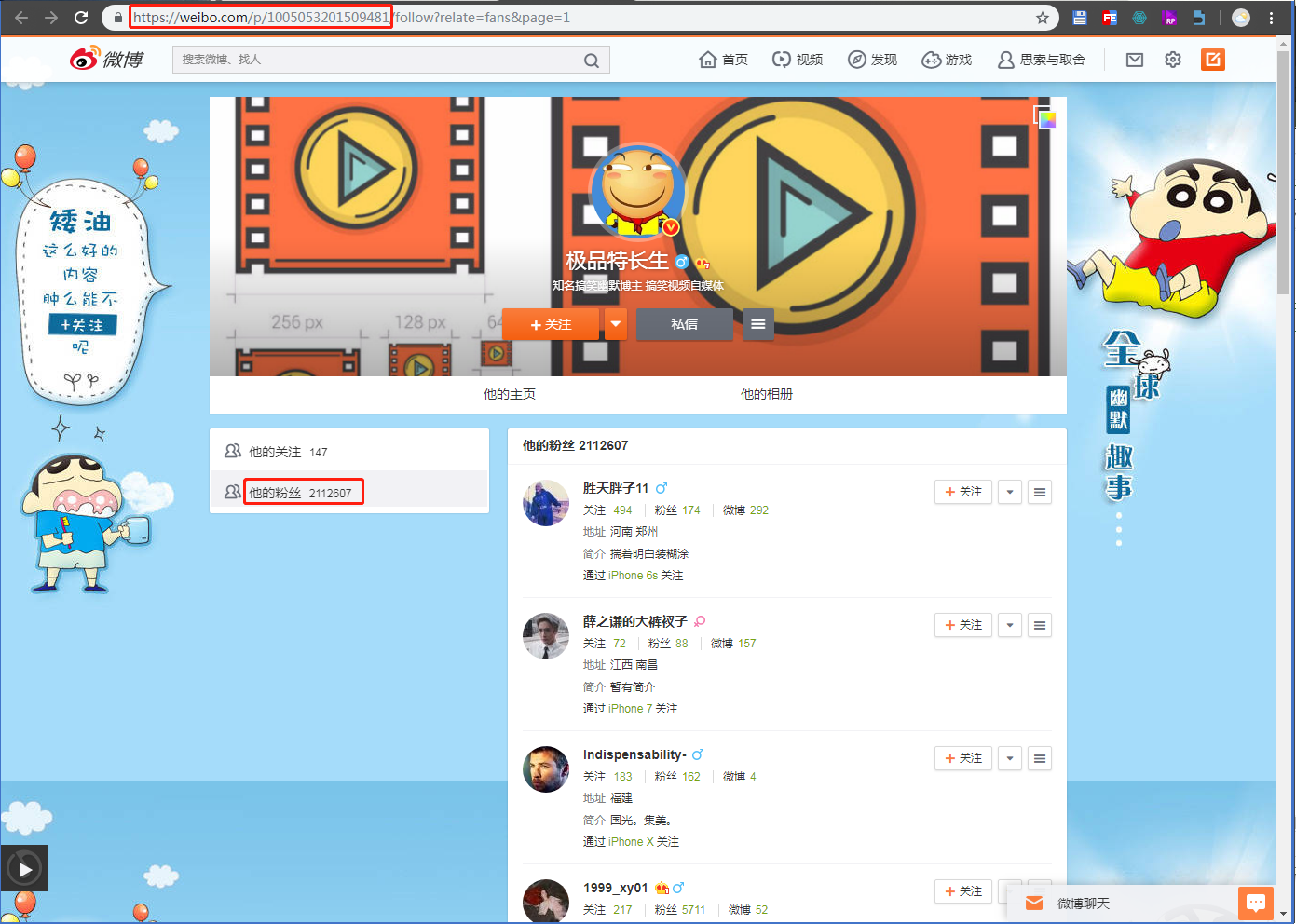
复制下面的模板导入站点即可
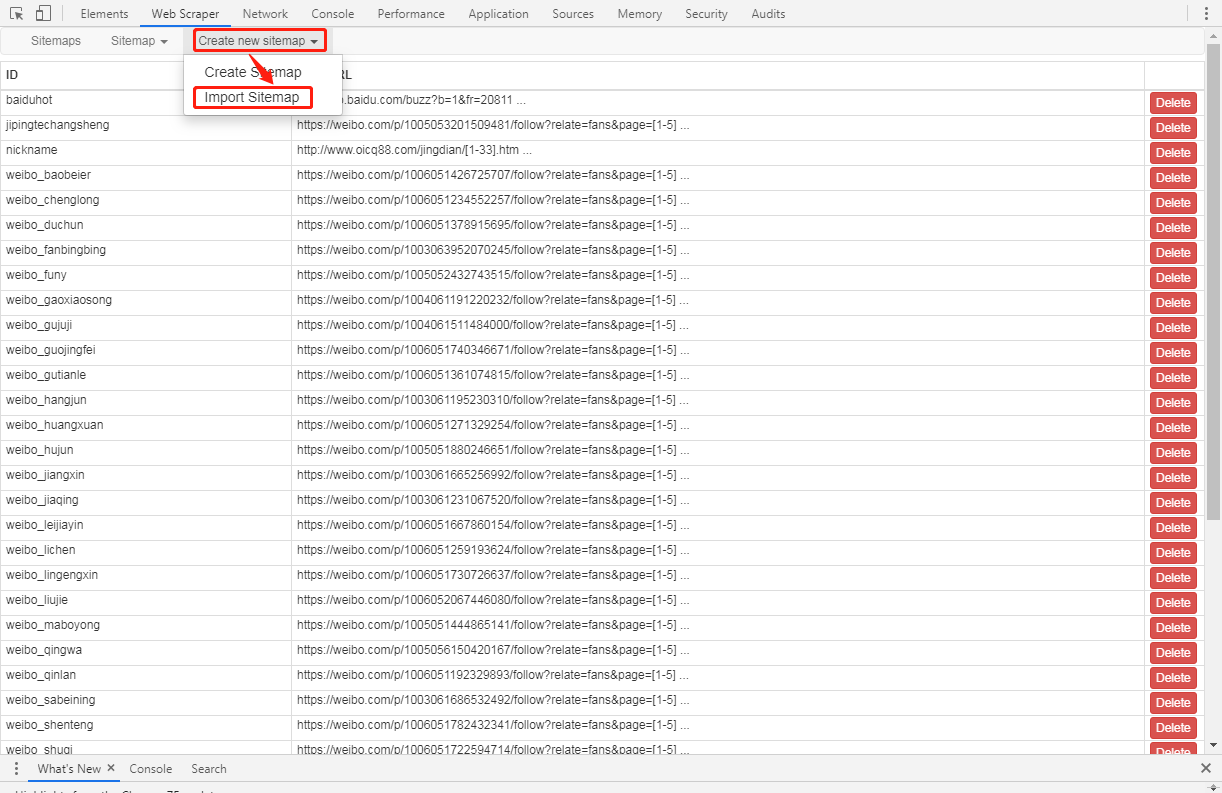
修改地址,编辑好名称,点击
Import Sitemap即可
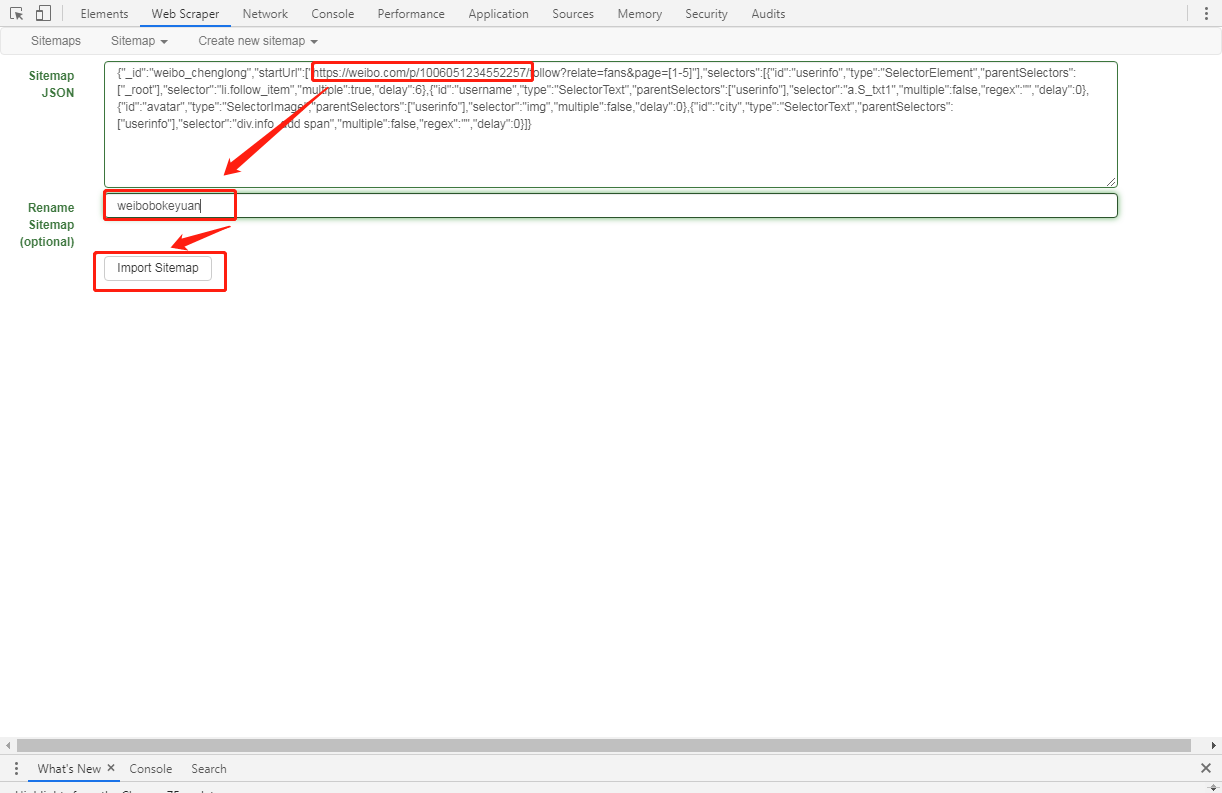
微博
{"_id":"weibo_chenglong","startUrl":["https://weibo.com/p/1006051234552257/follow?relate=fans&page=[1-5]"],"selectors":[{"id":"userinfo","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.follow_item","multiple":true,"delay":6},{"id":"username","type":"SelectorText","parentSelectors":["userinfo"],"selector":"a.S_txt1","multiple":false,"regex":"","delay":0},{"id":"avatar","type":"SelectorImage","parentSelectors":["userinfo"],"selector":"img","multiple":false,"delay":0},{"id":"city","type":"SelectorText","parentSelectors":["userinfo"],"selector":"div.info_add span","multiple":false,"regex":"","delay":0}]}
知乎
{"_id":"zhihuranqiqigongzuoshi","startUrl":["https://www.zhihu.com/people/xie-ling-520/followers?page=[1-45]"],"selectors":[{"id":"list","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.List-item","multiple":true,"delay":0},{"id":"username","type":"SelectorText","parentSelectors":["list"],"selector":"div.UserItem-title","multiple":false,"regex":"","delay":0},{"id":"avatar","type":"SelectorImage","parentSelectors":["list"],"selector":"img","multiple":false,"delay":0}]}
web scraper——爬取知乎|微博用户数据模板【三】的更多相关文章
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- Web Scraper爬取就是这么简单
这应该是最全的一个文档了 https://www.jianshu.com/p/e4c1561a3ea7 所以我就不介绍了,大家直接看就可以了,有问题可以提出来,我会针对问题对文章进行补充~
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- python 爬取知乎图片
先上完整代码 import requests import time import datetime import os import json import uuid from pyquery im ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # 爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # URL https://www.zhihu.co ...
随机推荐
- shell 编写脚本批量Ping IP
服务器总是一下子买了很多的段的ip.通过绑定后,也不知道这些ip是否绑定成功,所以就写了一个shell脚本,把ip输好,批量ping一下,看是不是都能ping通. 脚本如下: 此外.还有一个ip文件, ...
- linux 把nginx加入到系统服务的方法
linux 把nginx加入到系统服务的方法一.首先写一个shell脚本,脚本名称:nginx<pre>#! /bin/bash# chkconfig: 35 85 15 # descri ...
- 嵌入式02 STM32 实验06 按键
按键实验和前面的跑马灯.蜂鸣器主要的区别就是这个是读取外部的输入信号,之前的实验都是对外部输出信号. 一.硬件设计 本实验的硬件为三个按键.两个lED(LED0.LED1).一个蜂鸣器(BEEP). ...
- leetcode的Hot100系列--347. 前 K 个高频元素--hash表+直接选择排序
这个看着应该是使用堆排序,但我图了一个简单,所以就简单hash表加选择排序来做了. 使用结构体: typedef struct node { struct node *pNext; int value ...
- Rsync学习之旅中
rsync配置文件详解 配置文件内容说明 man rsyncd.conf 全局参数 rsyncd.conf参数 参数说明 uid=rsync 运行rsync守护进程的用户. gid=rsync 运行r ...
- jquery加载数据时显示loading加载动画特效
插件下载:http://www.htmleaf.com/jQuery/Layout-Interface/201505061788.html 插件使用: 使用该loading加载插件首先要引入jQuer ...
- centos7 挂载未分配的硬盘空间
=============================================== 2019/7/28_第1次修改 ccb_warlock == ...
- phpdocmentor 生成php 开发文档(转载)
PHPDocumentor是一个用PHP写的工具,对于有规范注释的php程序,它能够快速生成具有相互参照,索引等功能的API文档.老的版本是phpdoc,从1.3.0开始,更名为phpDocument ...
- git设置代理模式,仅为github设置代理
设置代理: 全局代理 git config --global http.proxy 127.0.0.1:1087 局部代理,在github clone 仓库内执行 git config --local ...
- Implicit super constructor Array() is undefined for default constructor. Must define an explicit constructor
因为你的父类已经创建了一个带参的构造函数并且父类中没有无参的构造函数,此时编译器不会为你调用默认的构造函数, 所以子类在继承父类的时候需要在自己的构造函数中显式的调用父类的构造函数,这样才能确保子类在 ...