hive集成kerberos
1、票据的生成
kdc服务器操作,生成用于hive身份验证的principal
1.1、创建principal
# kadmin.local -q “addprinc -randkey hive/yjt”
1.2、创建秘钥文件
# kadmin.local -q “xst -norankey -k /etc/hive.keytab hive/yjt”
拷贝秘钥文件到集群,root操作或者有root权限的普通用户操作
# scp /etc/hive.keytab 192.168.0.230:/data1/hadoop/hive/conf
连接到集群,修改文件权限
# chown hduser:hadoop /data1/hadoop/hive/conf/hive.keytab
# chomd 400 /data1/hadoop/hive/conf/hive.keytab
1.3、修改配置文件
Hive-site.xml配置文件添加如下信息:
<property>
<name>hive.server2.authentication</name>
<value>KERBEROS</value>
</property>
<property>
<name>hive.server2.authentication.kerberos.principal</name>
<value>hive/_HOST@HADOOP.COM</value>
</property>
<property>
<name>hive.server2.authentication.kerberos.keytab</name>
<value>/data1/hadoop/hive/conf/hive.keytab</value>
</property>
<property>
<name>hive.metastore.sasl.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.kerberos.keytab.file</name>
<value>/data1/hadoop/hive/conf/hive.keytab</value>
</property>
<property>
<name>hive.metastore.kerberos.principal</name>
<value>hive/_HOST@HADOOP.COM</value>
</property>
2、集群内部测试
2.1、获取票据
# kinit -kt /data1/hadoop/hive/conf/hive.keytab hive/yjt
获取到票据以后,使用klist查看获取的票据是否正确。

2.2、beeline测试
当前测试的hive版本是2.1.0,这个版本集成的hadoop版本是2.5.x,所以需要更换lib库下的hadoop版本或者下载一个高版本
这里拷贝hbase/lib库下的hadoop版本到hive,拷贝之前先删除hve/lib库下的有关hadoop版本的jar包,如下:
# cp /data1/hadoop/hbase/lib/hadoop-*.jar /data1/hadoop/hive/lib
使用beeline连接
# beeline
beeline> !connect jdbc:hive2://yjt:10000/;principal=hive/yjt@HADOOP.HOME -n hduser
0: jdbc:hive2://yjt:10000/> show tables;
+------------+--+
| tab_name |
+------------+--+
| user_info |
+------------+--+
1 row selected (2.363 seconds)
0: jdbc:hive2://yjt:10000/>
2.2、hive shell测试
(1)、测试mr引擎
默认就是mr引擎,所以不用修改说明配置
hive> select count(*) from user_info;
如果成功,说明配置ok
(2) 、测试tez引擎
切换引擎:
hive> set hive.execution.engine=tez;

3、客户端测试
3.1、安装hive
这里我们直接从集群内部拷一份hive配置到客户端
3.2、获取认证用户
# kinit -kt /data1/hadoop/hive/conf/hive.keytab hive/yjt
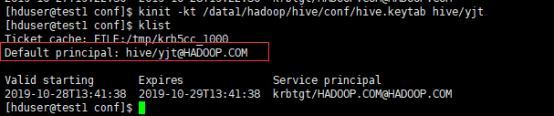
3.3、测试beeline
#beeline
beeline> !connect jdbc:hive2://yjt:10000/;principal=hive/yjt@HADOOP.HOME -n hduser
0: jdbc:hive2://yjt:10000/> show tables;
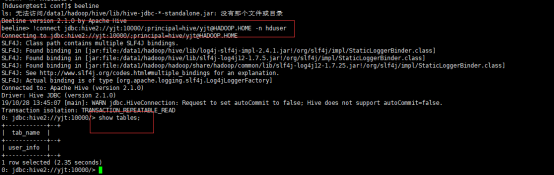
3.4、测试hive shell
(1)、mr引擎
select count(*) from user_info;
(2)、tez引擎
从集群拷贝tez软件目录到客户端
#scp -r /data1/hadoop/tez 192.168.0.9:/data1/hadoop
hive> set hive.execution.engine=tez;
hive> select count(*) from user_info;
注:上述在客户端的测试全部都是使用hduser用户,这个用户与集群内部启动集群进程的用户是一样的,接下来在客户端使用其他的用户测试。
3.5 测试其他用户
客户端创建yujt用户
# useradd yjt
# echo ‘123456’ |passwd --stdin ‘yujt’
修改hive.keytab权限(在一开始设置的权限为400)
# chmod 404 /data1/hadoop/hive/conf/hive.keytab
#su - yujt
获取认证用户
$ kinit -kt /data1/hadoop/hive/conf/hive.keytab hive/yjt
$hive shell
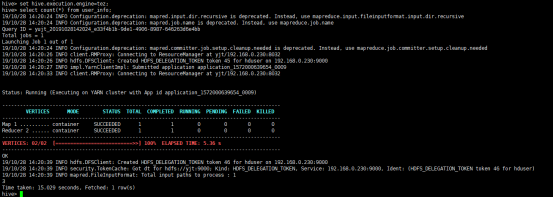
hive> select count(*) from user_info;
如果配置正确,上述任务执行状态ok
切换到tez引擎
hive集成kerberos的更多相关文章
- 挖坑:hive集成kerberos
集成hive+kerberos前,hadoop已经支持kerberos,所以基础安装略去: https://www.cnblogs.com/garfieldcgf/p/10077331.html 直接 ...
- HDP安全之集成kerberos/LDAP、ranger(knox自带LDAP)
----------------------目录导航见左上角------------------------------- 环境 HDP 3.0.1.0 (已有) JDK 1.8.0_91 (已有 ...
- Hive集成HBase;安装pig
Hive集成HBase 配置 将hive的lib/中的HBase.jar包用实际安装的Hbase的jar包替换掉 cd /opt/hive/lib/ ls hbase-0.94.2* rm -rf ...
- Hive集成HBase详解
摘要 Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询 插入操作以及进行Join和Union等复杂查询 应用场景 1. 将ETL操作的数据存入HBase 2. HB ...
- Ambari集成Kerberos报错汇总
Ambari集成Kerberos报错汇总 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看报错的配置信息步骤 1>.点击Test Kerberos Client,查看相 ...
- hbase与hive集成:hive读取hbase中数据
1.创建hbase jar包到hive lib目录软连接 hive需要jar包: hive-hbase-handler-0.13.1-cdh5.3.6.jar zookeeper-3.4.5-cdh5 ...
- Hive集成Mysql作为元数据时,提示错误:Specified key was too long; max key length is 767 bytes
在进行Hive集成Mysql作为元数据过程中.做全然部安装配置工作后.进入到hive模式,运行show databases.运行正常,接着运行show tables:时却报错. 关键错误信息例如以下: ...
- 大数据技术之_11_HBase学习_02_HBase API 操作 + HBase 与 Hive 集成 + HBase 优化
第6章 HBase API 操作6.1 环境准备6.2 HBase API6.2.1 判断表是否存在6.2.2 抽取获取 Configuration.Connection.Admin 对象的方法以及关 ...
- Hbase与hive集成与对比
HBase与Hive的对比 1.Hive (1) 数据仓库 Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询. (2) 用于数据分析.清洗 ...
随机推荐
- Source roots (or source folders) Test source roots (or test source folders; shown as rootTest)Resource rootsTest resource roots
idea中Mark Directory As里的Sources Root.ReSources Root等的区别 1.Source roots (or source folders) 通过这个类指定一个 ...
- c笔试题
以下程序的输出是(). struct st { int x; int *y; } *p; ] = { ,,, }; ] = { ,&dt[],,&dt[],,&dt[],,&a ...
- Content Security Policy (CSP)内容安全策略
CSP简介 Content Security Policy(CSP),内容(网页)安全策略,为了缓解潜在的跨站脚本问题(XSS攻击),浏览器的扩展程序系统引入了内容安全策略(CSP)这个概念. CSP ...
- 【面试突击】-RabbitMQ常见面试题(二)
问题一:RabbitMQ 中的 broker 是指什么?cluster 又是指什么? 答:broker 是指一个或多个 erlang node 的逻辑分组,且 node 上运行着 RabbitMQ 应 ...
- CSS 之 圣杯布局&双飞翼布局
圣杯布局 和 双飞翼布局 是重要布局方式.两者的功能相同,都是为了实现一个两侧宽度固定,中间宽度自适应的三栏布局. 遵循了以下要点: 两侧宽度固定,中间宽度自适应 中间部分在DOM结构上优先,以便先行 ...
- Swagger Liunx环境搭建(亲测百分百可用)
一.安装nodejs 下载编译好的nodejs安装包,下载地址: https://nodejs.org/dist/v10.10.0/ (作者下载的10.10.0,可根据自己需要下载不同版本) 将下载好 ...
- 【书评:Oracle查询优化改写】第四章
[书评:Oracle查询优化改写]第四章 BLOG文档结构图 一.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩)O~: ① check的 ...
- day 09 预科
目录 函数 定义函数 函数定义的三种形式 空函数 有参函数(有参数()的函数) 无参函数 函数的返回值 函数的参数 形参 位置形参 实参 位置实参 关键字实参 函数 def twoSum(nums,t ...
- Gitlab创建一个项目
1.安装git yum install git 2.生成密钥文件:使用ssh-keygen生成密钥文件.ssh/id_rsa.pub ssh-keygen 执行过程中输入密码,以及确认密码,并可设置密 ...
- NULLIF(EXPR1,EXPR2)
--NULLIF(EXPR1,EXPR2):给定两个参数EXPR1和EXPR2,如果两个参数相等,则返回NULL:否则就返回第一个参数.