pycharm爬取网页数据
1 python环境的配置
1.1 安装python文件包,放到可以找到的位置
1.2 右键计算机->属性->高级环境设置->系统变量->Path->编辑->复制python路径位置
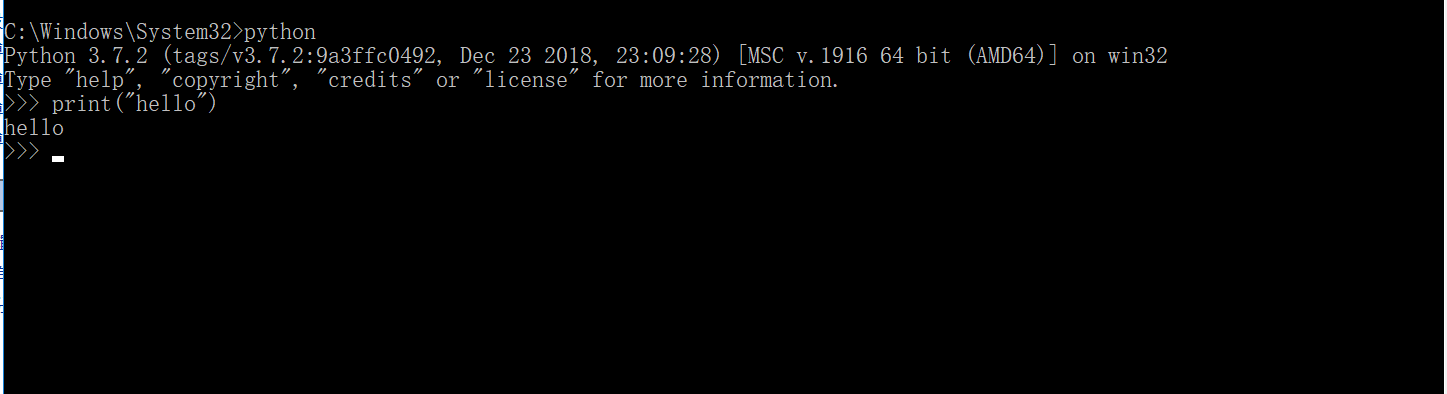
1.3 管理员身份打开cmd,输入python,测试环境是否安装成功
2 安装pycharm
2.1 安装pycharm文件包,放到可以找到的位置
2.2 新建文件夹,需要设置环境
2.3 File->Setting->project ...->add->找到python.exe
2.4 爬虫需要的安装包
2.4.1 打开cmd(管理员身份)
2.4.2 python -m pip install requests
2.4.3 python -m pip install lxml
2.4.4 python -m pip install bs4
2.5爬取数据
2.5.1 打开cmd 输入scrapy startproject Demo(可以先进入存放文件的目录)
2.5.2 打开pycharm打开文件Demo,新建python文件
2.5.3 新建python文件begin.py输入以下命令,运行begin可以实现爬取数据
from scrapy import cmdline
cmdline.execute("scrapy crawl uestc".split())
2.5.4 打开settings.py设置输出文件格式和文件位置以及User_agent
FEED_URI = u'file:///C:/scrapy/test.csv'//输出目录
FEED_FORMAT='CSV'
FEED_EXPORT_ENCODING="gb18030"
3 以下为部分图片
pycharm爬取网页数据的更多相关文章
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 使用XPath爬取网页数据
我们以我的博客为例,来爬取我所有写过的博客的标题. 首先,打开我的博客页面,右键“检查”开始进行网页分析.我们选中博客标题,再次右键“检查”即可找到标题相应的位置,我们继续点击右键,选择Copy,再点 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- Selenium+Tesseract-OCR智能识别验证码爬取网页数据
1.项目需求描述 通过订单号获取某系统内订单的详细数据,不需要账号密码的登录验证,但有图片验证码的动态识别,将获取到的数据存到数据库. 2.整体思路 1.通过Selenium技术,无窗口模式打开浏览器 ...
- 使用puppeteer爬取网页数据实践小结
简单介绍Puppeteer Puppeteer是一个Node库,它通过DevTools协议提供高级API来控制Chrome或Chromium.Puppeteer默认以无头方式运行,但可以配置为有头方式 ...
- 【推荐】oc解析HTML数据的类库(爬取网页数据)
TFhpple是一个用于解析html数据的第三方库,本人感觉功能还算可以,只不过在使用前必须配置项目. 配置 1.导入libxml2.tbd 2.设置编译路径 使用 这里使用一个例子来说明 http: ...
随机推荐
- 《OKR工作法》——打造一支专一的团队
<OKR工作法>在最开始讲了这样一个故事,阿塔兰忒是斯巴达跑的最快的人,她的父亲为了将她嫁出去举办了一场跑步比赛并许诺冠军可以娶自己的女儿,阿塔兰忒为了不结婚决定参加比赛自己拿冠军.然而在 ...
- 洛谷 P2947 [USACO09MAR]向右看齐Look Up
目录 题目 思路 \(Code\) 题目 戳 思路 单调栈裸题 \(Code\) #include<stack> #include<cstdio> #include<st ...
- [译]深度神经网络的多任务学习概览(An Overview of Multi-task Learning in Deep Neural Networks)
译自:http://sebastianruder.com/multi-task/ 1. 前言 在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI.为了达到这个目标,我 ...
- Bacteria(优先队列)
题目链接:http://codeforces.com/gym/101911/problem/C 问题简述:给定n个细胞以及每个细胞的大小,相同的细胞能进行融合,如果能融合到只剩1个细胞则输出需要额外增 ...
- kafka-python 1.4.6 版本触发的一个 rebalance 问题
在使用了最新版的 kafka-python 1.4.6 在 broker 对 topic 进行默认配置的情况下报出类似错误 CommitFailedError CommitFailedError: C ...
- Java-根据经纬度计算距离(百度地图距离)
最近碰到一个需求,需要根据两个点的经纬度查询两点的距离.感觉以后还会用到,所以小记一波. 第一步:添加Maven依赖. <dependency> <groupId>org.ga ...
- 【2019.12.04】SDN上机第6次作业
实验拓扑 通过图形化界面建立拓扑 先清除网络拓扑 sudo mn -c 生成Python语句 #!/usr/bin/python from mininet.net import Mininet fro ...
- 数据仓库DW、ODS、DM概念及其区别
整体结构 在具体分析数据仓库之前先看下一下数据中心的整体架构以及数据流向 数据中心整体架构.png DB 是现有的数据来源,可以为mysql.SQLserver.文件日志等,为数据仓库提供数据来源 ...
- deepin深度学习环境配置
deepin是一个精致优美的系统.最近因为工作需要在deepin上配置深度学习环境,话不多说,接下来记录下整个的配置过程. ×××本篇文章适合对深度学习环境配置有一定了解且对deepin系统感兴趣的同 ...
- 自定义设置jqGrid的标头居中加粗等
beforeRequest: function () { $("thead th").css("text-align", "center") ...