pycharm爬取网页数据
1 python环境的配置
1.1 安装python文件包,放到可以找到的位置
1.2 右键计算机->属性->高级环境设置->系统变量->Path->编辑->复制python路径位置
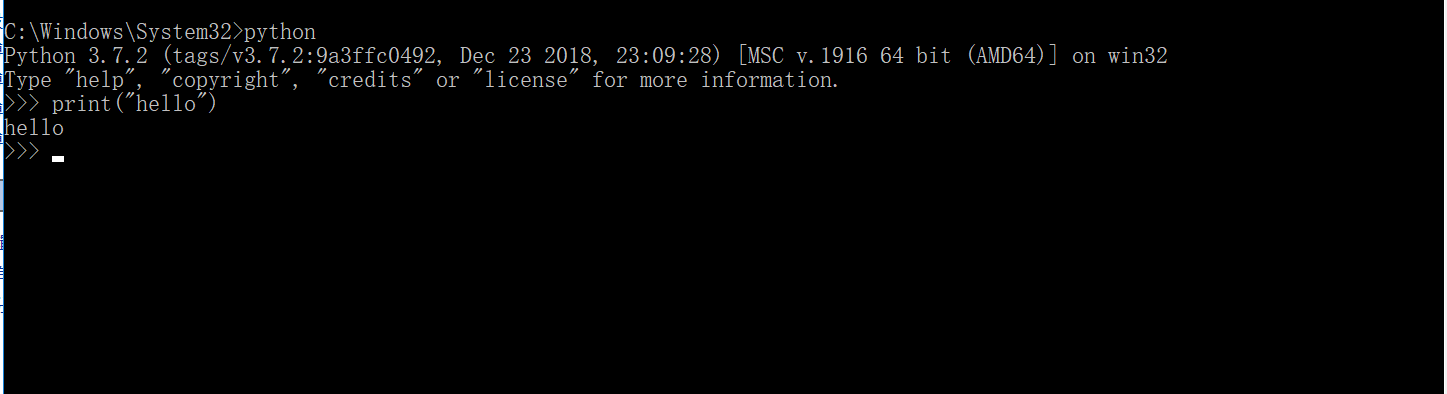
1.3 管理员身份打开cmd,输入python,测试环境是否安装成功
2 安装pycharm
2.1 安装pycharm文件包,放到可以找到的位置
2.2 新建文件夹,需要设置环境
2.3 File->Setting->project ...->add->找到python.exe
2.4 爬虫需要的安装包
2.4.1 打开cmd(管理员身份)
2.4.2 python -m pip install requests
2.4.3 python -m pip install lxml
2.4.4 python -m pip install bs4
2.5爬取数据
2.5.1 打开cmd 输入scrapy startproject Demo(可以先进入存放文件的目录)
2.5.2 打开pycharm打开文件Demo,新建python文件
2.5.3 新建python文件begin.py输入以下命令,运行begin可以实现爬取数据
from scrapy import cmdline
cmdline.execute("scrapy crawl uestc".split())
2.5.4 打开settings.py设置输出文件格式和文件位置以及User_agent
FEED_URI = u'file:///C:/scrapy/test.csv'//输出目录
FEED_FORMAT='CSV'
FEED_EXPORT_ENCODING="gb18030"
3 以下为部分图片
pycharm爬取网页数据的更多相关文章
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 使用XPath爬取网页数据
我们以我的博客为例,来爬取我所有写过的博客的标题. 首先,打开我的博客页面,右键“检查”开始进行网页分析.我们选中博客标题,再次右键“检查”即可找到标题相应的位置,我们继续点击右键,选择Copy,再点 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- Selenium+Tesseract-OCR智能识别验证码爬取网页数据
1.项目需求描述 通过订单号获取某系统内订单的详细数据,不需要账号密码的登录验证,但有图片验证码的动态识别,将获取到的数据存到数据库. 2.整体思路 1.通过Selenium技术,无窗口模式打开浏览器 ...
- 使用puppeteer爬取网页数据实践小结
简单介绍Puppeteer Puppeteer是一个Node库,它通过DevTools协议提供高级API来控制Chrome或Chromium.Puppeteer默认以无头方式运行,但可以配置为有头方式 ...
- 【推荐】oc解析HTML数据的类库(爬取网页数据)
TFhpple是一个用于解析html数据的第三方库,本人感觉功能还算可以,只不过在使用前必须配置项目. 配置 1.导入libxml2.tbd 2.设置编译路径 使用 这里使用一个例子来说明 http: ...
随机推荐
- Selenium ChromeDriver与Chrome版本映射表(更新到v77)
ChromeDriver版本 支持的Chrome版本 v77.0.3865.40 v77 v76.0.3809.126 v76 v75.0.3770.140 v75 v74 v74 v73 v73 v ...
- intellij ide 激活(转发)
前期准备 文件下载:jetbrains-agent.jar 激活码:license.txt 3AGXEJXFK9-eyJsaWNlbnNlSWQiOiIzQUdYRUpYRks5IiwibGljZW5 ...
- Docker部署web项目-war包
一.部署springmvc(war包)项目 1.手工方式 ①搜索tomcat镜像 docker search tomcat ②拉取tomcat基础镜像至本地仓库 docker pull tomcat ...
- 转载:Base64编解码介绍
https://www.liaoxuefeng.com/wiki/897692888725344/949441536192576 Base64是一种用64个字符来表示任意二进制数据的方法. 用记事本打 ...
- odoo开发笔记--ValueError Expected singleton
异常处理参考:https://stackoverflow.com/questions/31070640/valueerror-expected-singleton-odoo8 报错: ValueErr ...
- Win10 LTSC 2019 安装和卸载 linux 子系统
一.开启 二.下载 https://docs.microsoft.com/zh-cn/windows/wsl/install-manual 手动下载适用于 Linux 的 Windows 子系统发 ...
- 持久化机器学习模型(joblib方式)
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression ...
- [LeetCode] 651. 4 Keys Keyboard 四键的键盘
Imagine you have a special keyboard with the following keys: Key 1: (A): Print one 'A' on screen. Ke ...
- Eclipse安装Properties Editor插件
安装步骤 1.打开eclispe编辑器help-->install new soft 2.输入软件地址 name:properties editor Location:http://proped ...
- 【Java语言特性学习之一】设计模式
设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了可重用代码.让代码更容易被他人理解.保证代码可靠性. 毫无疑问,设计模式于 ...