ItemCF_基于物品的协同过滤
ItemCF_基于物品的协同过滤
1. 概念

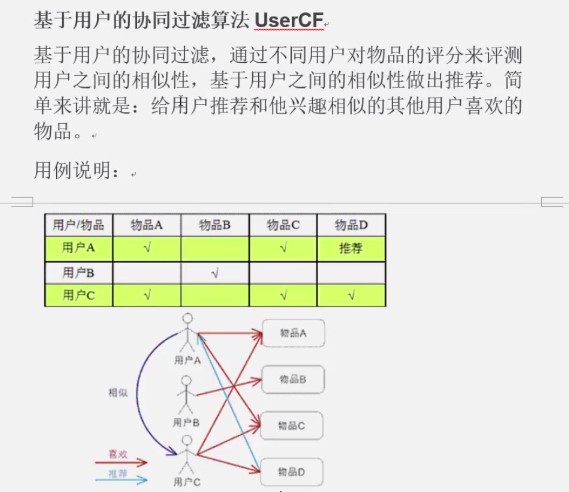
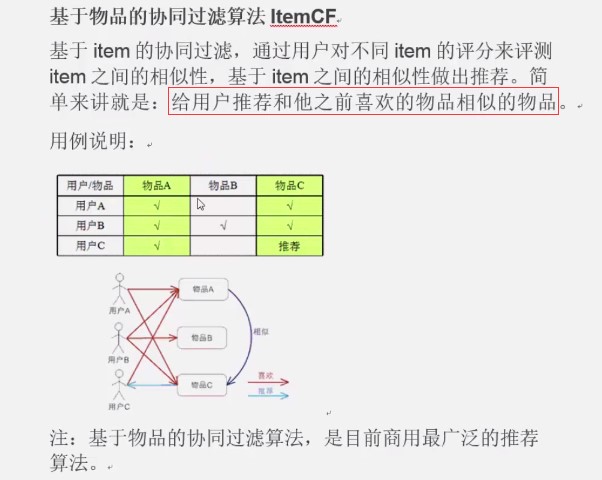
2. 原理
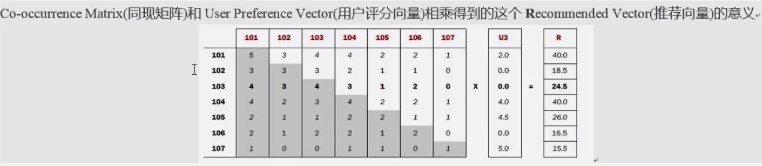

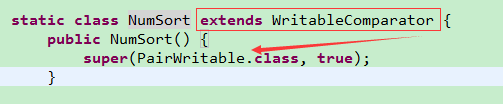
3. java代码实现思路
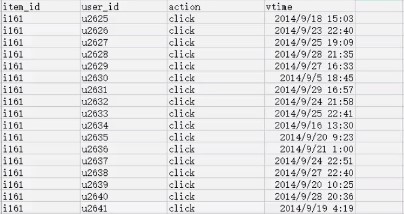
六个MapReduce
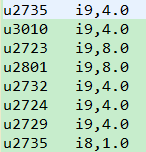



ItemCF_基于物品的协同过滤的更多相关文章
- ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路
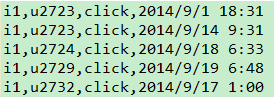
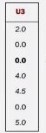
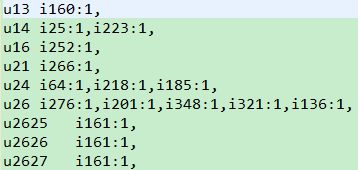
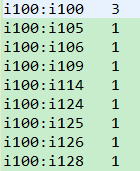
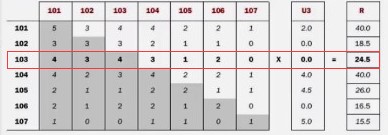
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
随机推荐
- 项目Beta冲刺(团队)第一天
1.今天解决的进度 成员 进度 陈家权 回复界面设计,由于成员变动加上和其他成员距离较远,服务器404 赖晓连 改进Alpha版本页面没能及时更新的问题 雷晶 获取提问问题时间更新到数据库 林巧娜 今 ...
- J2EE,J2SE,J2ME,JDK,SDK,JRE,JVM区别(转载)
转载地址:http://blog.csdn.net/alspwx/article/details/20799017 一.J2EE.J2SE.J2ME区别 J2EE——全称Java 2 Enterpri ...
- iOS- 关于AVAudioSession的使用——后台播放音乐
1.前言 •AVAudioSession是一个单例,无需实例化即可直接使用.AVAudioSession在各种音频环境中起着非常重要的作用 •针对不同的音频应用场景,需要设置不同的音频会话分类 1 ...
- Maven编译打包出错:找不到符号
项目中,使用的是maven管理,但是有几个jar不是通过maven引入的,是通过IDEA导入的,在使用maven插件编译的时候,会出现如下的一些错误: 解决方法: 在项目中创建一个目录lib,然后将j ...
- influxdb 命令
写入数据: curl -X POST -d '[{"name":"foo","columns":["val"],&quo ...
- KMP算法模板(pascal)
洛谷P3375: program rrr(input,output); var i,j,lena,lenb:longint; a,b:ansistring; next:..]of longint; b ...
- 洛谷 P2951 [USACO09OPEN]捉迷藏Hide and Seek
题目戳 题目描述 Bessie is playing hide and seek (a game in which a number of players hide and a single play ...
- window与linux查看端口被占用
本文摘写自: 百度经验 https://www.cnblogs.com/ieayoio/p/5757198.html 一.windows:开始---->运行---->cmd,或者是wind ...
- jQuery高度及位置操作
1. 获取滑轮位置,scrolltop:上下滚动的意思. <!DOCTYPE html> <html lang="en"> <head> < ...
- TortoiseSVN 和 VisualSVN Server 使用教程
TortoiseSVN 和 VisualSVN Server 使用教程 来源 https://blog.csdn.net/xgf415/article/details/75196360 目录: SVN ...