ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路
ItemCF_基于物品的协同过滤
1. 概念

2. 原理
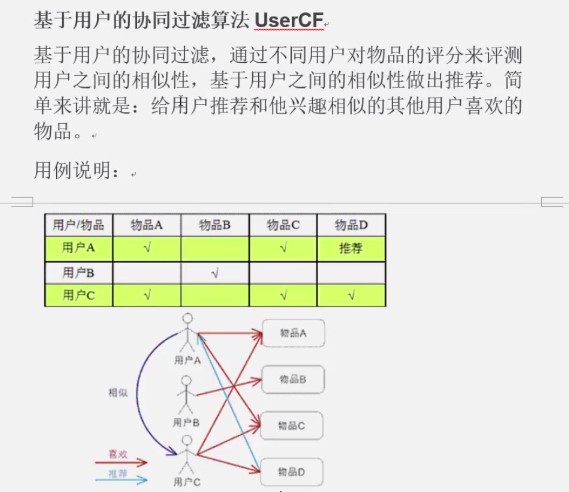
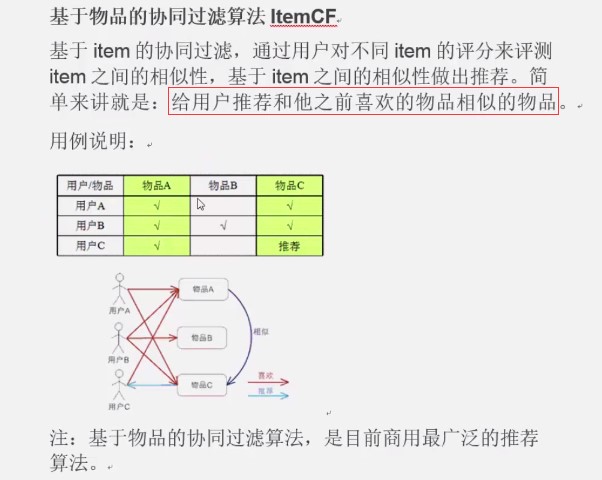
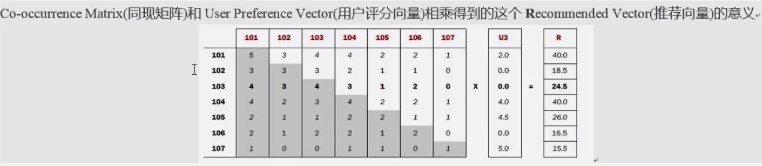

3. java代码实现思路
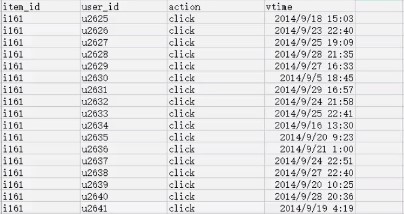
六个MapReduce
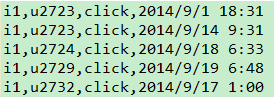
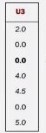
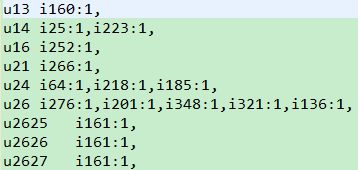
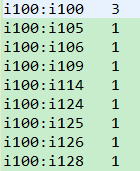
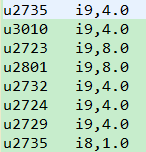


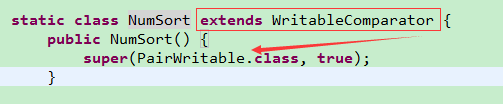
PairWritable,

ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路的更多相关文章
- ItemCF_基于物品的协同过滤
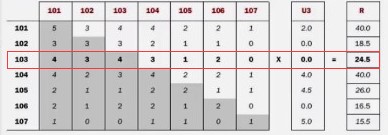
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
随机推荐
- HTTPS加密流程超详解(二)
2.进入正题 上篇文章介绍了如何简单搭建一个环境帮助我们分析,今天我们就进入正题,开始在这个环境下分析. 我们使用IE浏览器访问Web服务器根目录的test.txt文件并抓包,可以抓到如下6个包(前面 ...
- 正确使用volatile场景--状态标志
同步机制:volatile 特点:可见性:不具备原子性 每个线程有自己单独的内存:如果线程1和线程2公用一个变量name:如果两个线程并发进行,并且需要访问变量name:如果这个变量具有了可见性,线程 ...
- Q:javax.comm 2.0 windows下Eclipse的配置
@转自http://blog.csdn.net/zhuanghe_xing/article/details/7523744处 要在Windows下,对计算机的串口或并口等进行编程,可以选择使用Java ...
- 三:Redis连接池、JedisPool详解、Redisi分布式
单机模式: package com.ljq.utils; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; ...
- 解决SVN造成的桌面图标问号
之前不小心直接将版本库 的内容检出 到桌面,后才发现桌面上的文件 都变成了问号,本来也以为没有多大问题,删除.svn 即可,可是删除所有的.svn后,桌面上还是显示问号,刷新了很多次,还重启电脑 了, ...
- Django_调查问卷
1.问卷的保存按钮 前端通过ajax把数据发过来后端处理数据,然后返回给前端2.对问卷做答 首先用户进行登录,验证 条件:1.只有本班的学生才能对问卷做答 2.已经参加过的不能再次访问 ...
- UWP 手绘视频创作工具技术分享系列 - 文字的解析和绘制
本篇作为技术分享系列的第二篇,详细讲一下文字的解析和绘制,这部分功能的研究和最终实现由团队共同完成,目前还在寻找更理想的实现方式. 首先看一下文字绘制在手绘视频中的应用场景 文字是手绘视频中很重要的表 ...
- How It Works: CMemThread and Debugging Them
The wait type of CMemThread shows up in outputs such as sys.dm_exec_requests. This post is intended ...
- vue2.0 如何在hash模式下实现微信分享
最近又把vue的demo拿出来整理下,正好要做"微信分享"功能,于是遇到新的问题: 由于hash模式下,带有"#",导致微信分享的签证无效:当改成history ...
- js生成word中图片处理
首先功能是要求前台导出word,但是前后台是分离的,图片存在后台,所以就存在跨域问题. 导出文字都是没有问题的(jquery.wordexport.js),但是导出图片就存在问题了: 图片是以链接形式 ...