ItemCF_基于物品的协同过滤
ItemCF_基于物品的协同过滤
1. 概念

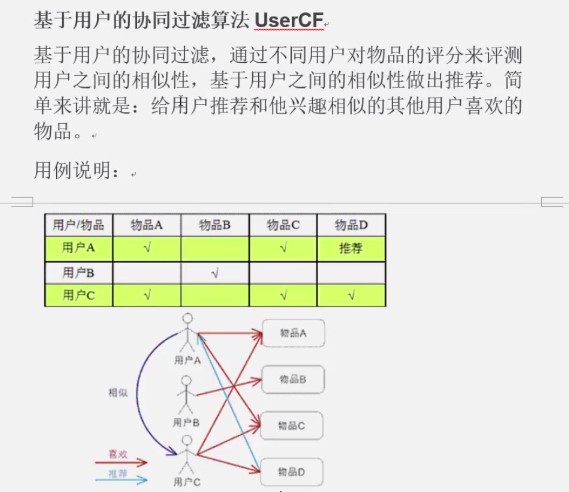
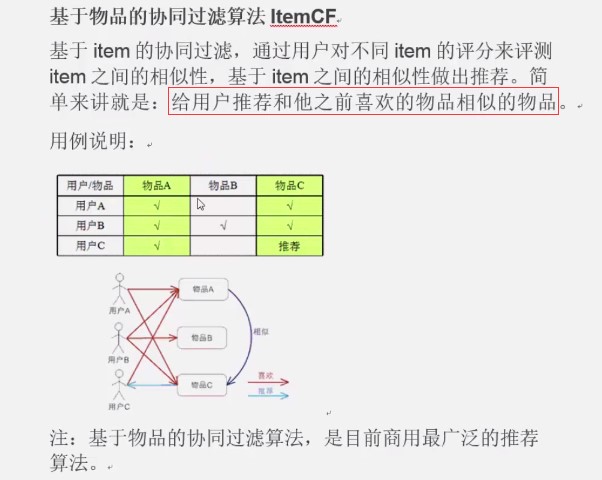
2. 原理
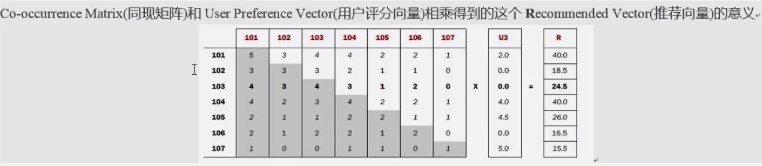

3. java代码实现思路
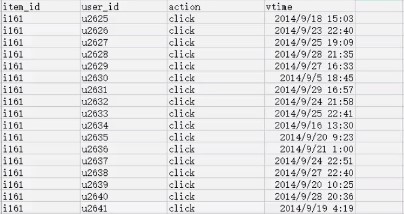
六个MapReduce



ItemCF_基于物品的协同过滤的更多相关文章
- ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路
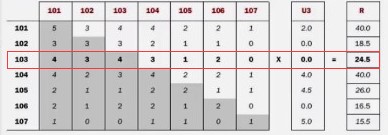
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
随机推荐
- 【Linux】- 简明Vim练习攻略
vim的学习曲线相当的大(参看各种文本编辑器的学习曲线),所以,如果你一开始看到的是一大堆VIM的命令分类,你一定会对这个编辑器失去兴趣的.下面的文章翻译自<Learn Vim Progress ...
- 第146天:移动H5前端性能优化
移动H5前端性能优化 一.概述 1. PC优化手段在Mobile侧同样适用 2. 在Mobile侧我们提出三秒种渲染完成首屏指标 3. 基于第二点,首屏加载3秒完成或使用Loading 4. 基于联通 ...
- 在mvc4中上传、导入和导出excel表方法总结
通过excel的导入导出练习,使用NPOI组件还是方便一点,所有下面就以NPOI下的导入导出给出实例,通过网页导入excel表,首先上传,再导入数据到库,这里为了方便就不导入到库中了,直接拿到数据.导 ...
- SPOJ3713——Primitive Root
终于有一个SPOJ题目是我自己独立做出来的,ORZ,太感动了. 题目意思是给你一个素数,问你一个数r是否满足,r,r^2,r^3,……,r^p-1,全不相同. 以前做过这种类型的题目额.是这样的. 根 ...
- 方法调用时候 传入this 谁调用 传入谁
方法调用时候 传入this 谁调用 传入谁
- canvas - 炫酷的3D星空
1.国际惯例,先上效果 (⊙o⊙)… 效果图看上去效果并不很炫酷啊,直接戳 这里 看效果吧! 2代码部分 html: <canvas id="canvas" width=&q ...
- HTTP摘要认证原理以及HttpClient4.3实现
基本认证便捷灵活,但极不安全.用户名和密码都是以明文形式传送的,也没有采取任何措施防止对报文的篡改.安全使用基本认证的唯一方式就是将其与 SSL 配合使用. 摘要认证是另一种HTTP认证协议,它试图修 ...
- 解题:APIO 2008 免费道路
题面 我们发现我们可以很容易知道最终完成的生成树中有多少鹅卵石路,但是我们不好得到这棵生成树的结构,所以我们尽量“谨慎”地完成生成树·,最好是一点点加到我们要达到的标准而不是通过删掉一些东西来完成 我 ...
- 【bzoj4543】Hotel加强版(thr)
Portal --> bzoj4543 Solution 一年前的题== 然而一年前我大概是在划水qwq 其实感觉好像关键是..设一个好的状态?然后..你要用一种十分优秀的方式快乐转移 ...
- 【CF113D】Museum
Portal --> cf113D Solution 额题意的话大概就是给一个无向图然后两个人给两个出发点,每个点每分钟有\(p[i]\)的概率停留,问这两个人在每个点相遇的概率是多少 如果说我 ...