CVPR2018关键字分析生成词云图与查找
今日目标:爬取CVPR2018论文,进行分析总结出提到最多的关键字,生成wordCloud词云图展示,并且设置点击后出现对应的论文以及链接
对任务进行分解:
①爬取CVPR2018的标题,简介,关键字,论文链接
②将爬取的信息生成wordCloud词云图展示
③设置点击事件,展示对应关键字的论文以及链接
一、爬虫实现
由于文章中并没有找到关键字,于是将标题进行拆分成关键字,用逗号隔开
import re
import requests
from bs4 import BeautifulSoup
import demjson
import pymysql
import os headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息
url='http://openaccess.thecvf.com/CVPR2018.py'
r=requests.get(url,headers=headers)
content=r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
dts=soup.find_all('dt',class_='ptitle')
hts='http://openaccess.thecvf.com/'
#数据爬取
alllist=[]
for i in range(len(dts)):
print('这是第'+str(i)+'个')
title=dts[i].a.text.strip()
href=hts+dts[i].a['href']
r = requests.get(href, headers=headers)
content = r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
#print(title,href)
divabstract=soup.find(name='div',attrs={"id":"abstract"})
abstract=divabstract.text.strip()
#print('第'+str(i)+'个:',abstract)
alllink=soup.select('a')
link=hts+alllink[4]['href'][6:]
keyword=str(title).split(' ')
keywords=''
for k in range(len(keyword)):
if(k==0):
keywords+=keyword[k]
else:
keywords+=','+keyword[k]
value=(title,abstract,link,keywords)
alllist.append(value)
print(alllist)
tuplist=tuple(alllist)
#数据保存
db = pymysql.connect("localhost", "root", "fengge666", "yiqing", charset='utf8')
cursor = db.cursor()
sql_cvpr = "INSERT INTO cvpr values (%s,%s,%s,%s)"
try:
cursor.executemany(sql_cvpr,tuplist)
db.commit()
except:
print('执行失败,进入回调3')
db.rollback()
db.close()
二、将数据进行wordCloud展示
首先找到对应的包,来展示词云图
<script src='https://cdn.bootcss.com/echarts/3.7.0/echarts.simple.js'></script>
<script src='js/echarts-wordcloud.js'></script>
<script src='js/echarts-wordcloud.min.js'></script>
然后通过异步加载,将后台的json数据进行展示。
由于第一步我们获得的数据并没有对其进行分析,因此我们在dao层会对其进行数据分析,找出所有的关键字的次数并对其进行降序排序(用Map存储是最好的方式)
public Map<String,Integer> getallmax()
{
String sql="select * from cvpr";
Map<String, Integer>map=new HashMap<String, Integer>();
Map<String, Integer>sorted=new HashMap<String, Integer>();
Connection con=null;
Statement state=null;
ResultSet rs=null;
con=DBUtil.getConn();
try {
state=con.createStatement();
rs=state.executeQuery(sql);
while(rs.next())
{
String keywords=rs.getString("keywords");
String[] split = keywords.split(",");
for(int i=0;i<split.length;i++)
{
if(map.get(split[i])==null)
{
map.put(split[i],0);
}
else
{
map.replace(split[i], map.get(split[i])+1);
}
}
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
DBUtil.close(rs, state, con);
sorted = map
.entrySet()
.stream()
.sorted(Collections.reverseOrder(comparingByValue()))
.collect(
toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e2,
LinkedHashMap::new));
return sorted;
}
到servlet层后,我们还需对数据进行一定的筛选(介词,a,等词语应该去除掉,要不然会干扰我们分析关键字),取前30名关键字,在前台进行展示
request.setCharacterEncoding("utf-8");
Map<String, Integer>sortMap=dao.getallmax();
JSONArray json =new JSONArray();
int k=0;
for (Map.Entry<String, Integer> entry : sortMap.entrySet())
{
JSONObject ob=new JSONObject();
ob.put("name", entry.getKey());
ob.put("value", entry.getValue());
if(!(entry.getKey().equals("for")||entry.getKey().equals("and")||entry.getKey().equals("With")||entry.getKey().equals("of")||entry.getKey().equals("in")||entry.getKey().equals("From")||entry.getKey().equals("A")||entry.getKey().equals("to")||entry.getKey().equals("a")||entry.getKey().equals("the")||entry.getKey().equals("by")))
{
json.add(ob);
k++;
}
if(k==30)
break;
}
System.out.println(json.toString());
response.getWriter().write(json.toString());
三、设置点击事件,展示对应关键字的论文以及链接
//设置点击效果
var ecConfig = echarts.config;
myChart.on('click', eConsole);
用函数来实现点击事件的内容:通过点击的关键字,后台进行模糊查询,找到对应的论文题目以及链接,返回到前端页面
//点击事件
function eConsole(param) {
if (typeof param.seriesIndex == 'undefined') {
return;
}
if (param.type == 'click') {
var word=param.name;
var htmltext="<table class='table table-striped' style='text-align:center'><caption style='text-align:center'>论文题目与链接</caption>";
$.post(
'findkeytitle',
{'word':word},
function(result)
{
json=JSON.parse(result);
for(i=0;i<json.length;i++)
{
htmltext+="<tr><td><a target='_blank' href='"+json[i].Link+"'>"+json[i].Title+"</a></td></tr>";
}
htmltext+="</table>"
$("#show").html(htmltext);
}
)
}
}
成果展示:
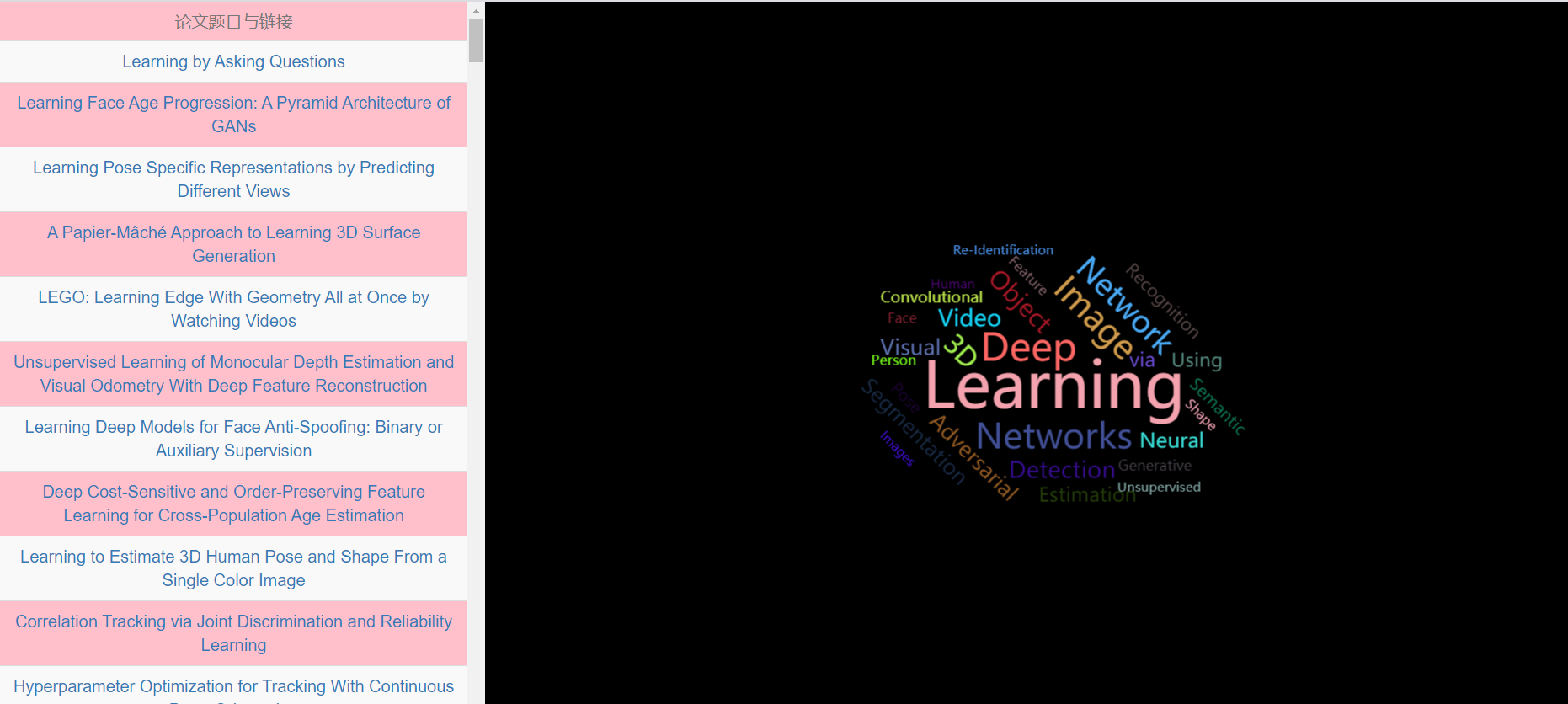
前台页面代码:
<html>
<head>
<meta charset="utf-8">
<link href="css/bootstrap.min.css" rel="stylesheet">
<!-- jQuery (Bootstrap 的所有 JavaScript 插件都依赖 jQuery,所以必须放在前边) -->
<script src="js/jquery-1.11.3.min.js"></script>
<!-- 加载 Bootstrap 的所有 JavaScript 插件。你也可以根据需要只加载单个插件。 -->
<script src="js/bootstrap.js"></script>
<script src='https://cdn.bootcss.com/echarts/3.7.0/echarts.simple.js'></script>
<script src='js/echarts-wordcloud.js'></script>
<script src='js/echarts-wordcloud.min.js'></script>
</head>
<body>
<style>
body{
background-color: black;
}
#main {
width: 70%;
height: 100%;
margin: 0;
float:right;
background: black;
}
#show{
overflow-x: auto;
overflow-y: auto;
width: 30%;
height: 100%;
float:left;
margin-top:100dp;
padding-top:100dp;
background: pink;
}
</style>
<div id='show'></div>
<div id='main'></div>
<script>
$(function(){
echartsCloud();
});
//点击事件
function eConsole(param) {
if (typeof param.seriesIndex == 'undefined') {
return;
}
if (param.type == 'click') {
var word=param.name;
var htmltext="<table class='table table-striped' style='text-align:center'><caption style='text-align:center'>论文题目与链接</caption>";
$.post(
'findkeytitle',
{'word':word},
function(result)
{
json=JSON.parse(result);
for(i=0;i<json.length;i++)
{
htmltext+="<tr><td><a target='_blank' href='"+json[i].Link+"'>"+json[i].Title+"</a></td></tr>";
}
htmltext+="</table>"
$("#show").html(htmltext);
}
)
}
}
function echartsCloud(){ $.ajax({
url:"getmax",
type:"POST",
dataType:"JSON",
async:true,
success:function(data)
{
var mydata = new Array(0); for(var i=0;i<data.length;i++)
{
var d = { };
d["name"] = data[i].name;//.substring(0, 2);
d["value"] = data[i].value;
mydata.push(d);
}
var myChart = echarts.init(document.getElementById('main'));
//设置点击效果
var ecConfig = echarts.config;
myChart.on('click', eConsole); myChart.setOption({
title: {
text: ''
},
tooltip: {},
series: [{
type : 'wordCloud', //类型为字符云
shape:'smooth', //平滑
gridSize : 8, //网格尺寸
size : ['50%','50%'],
//sizeRange : [ 50, 100 ],
rotationRange : [-45, 0, 45, 90], //旋转范围
textStyle : {
normal : {
fontFamily:'微软雅黑',
color: function() {
return 'rgb(' +
Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) + ')'
}
},
emphasis : {
shadowBlur : 5, //阴影距离
shadowColor : '#333' //阴影颜色
}
},
left: 'center',
top: 'center',
right: null,
bottom: null,
width:'100%',
height:'100%',
data:mydata
}]
});
}
});
}
</script>
</body>
</html>
CVPR2018关键字分析生成词云图与查找的更多相关文章
- Python模块---Wordcloud生成词云图
wordcloud是Python扩展库中一种将词语用图片表达出来的一种形式,通过词云生成的图片,我们可以更加直观的看出某篇文章的故事梗概. 首先贴出一张词云图(以哈利波特小说为例): 在生成词云图之前 ...
- python根据文本生成词云图
python根据文本生成词云图 效果 代码 from wordcloud import WordCloud import codecs import jieba #import jieba.analy ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- Excel催化剂开源第27波-Excel离线生成词云图
在数据分析领域,词云图已经成为在文本分析中装逼的首选图表,大家热烈地讨论如何在Python上做数据分析.做词云图. 数据分析从来都是Excel的主战场,能够让普通用户使用上的技术才是最有价值的技术,一 ...
- 已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小. 写在前面: 用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述. 但是对于根据generate_from_f ...
- 小白学Python(12)——pyecharts ,生成词云图 WordCloud
WordCloud(词云图) from pyecharts import options as opts from pyecharts.charts import Page, WordCloud fr ...
- Python爬虫b站视频弹幕并生成词云图分析
爬虫:requests,beautifulsoup 词云:wordcloud,jieba 代码加注释: # -*- coding: utf-8 -*- import xlrd#读取excel impo ...
- 微信聊天记录导出为csv,并生成词云图
微信聊天记录生成特定图片图云 首先贴上github地址 https://github.com/ghdefe/WechatRecordToWordCloud 来个效果图 提取聊天记录到csv参考教程 h ...
- 【爬虫+情感判定+Top10高频词+词云图】“谷爱凌”热门弹幕python舆情分析
一.背景介绍 最近几天,谷爱凌在冬奥会赛场上夺得一枚宝贵的金牌,为中国队贡献了自己的荣誉! 针对此热门事件,我用Python的爬虫和情感分析技术,针对小破站的弹幕数据,分析了众网友弹幕的舆论导向,下面 ...
随机推荐
- 测试必知必会系列- Linux常用命令 - cp
21篇测试必备的Linux常用命令,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1672457.html 复制文 ...
- echarts legend文字配置多个颜色(转)
困扰很久的问题终于解决了 oh yea! echarts legend文字配置多个颜色legend: {data: [{name:‘直接访问’,icon : ‘circle’,textStyle: { ...
- vue后台管理系统权限处理
vue后台管理系统权限 1.权限问题:用户和管理员进入管理系统看到的模块是不一样的,管理员看的的要比用户看到的多.需要用到动态加载路由,router.addRouters()来动态的挂载路由 // 1 ...
- 部署harbor以https模式和k8s对接
集群时间同步 我们在之前的kubeasz部署高可用kubernetes1.17.2 并实现traefik2.1.2部署篇已经实现了基于chrony的时间同步 [root@bs-k8s-master01 ...
- Javascript的document对象
对象属性 document.title //设置文档标题等价于HTML的<title>标签 document.bgColor / ...
- IE 跨域session丢失问题
在测试时发现session 取不到值,以为是session赋值除了问题,但是在Chrome中一切正常,故排除此原因.那问题肯定出在浏览器身上里.于是一步一步调试,发现在IE中,如果页面跳转,Sessi ...
- 后端开发使用pycharm的技巧
后端开发使用pycharm的技巧 目录 后端开发使用pycharm的技巧 1.使用说明 2.database 3.HTTP Client 1.使用说明 首先说明,本文所使用的功能为pycharm专业版 ...
- 非常详细的 Linux C/C++ 学习路线总结!已拿腾讯offer
创作不易,点赞关注支持一下吧,我的更多原创技术分享,关注公众号「后端技术学堂」第一时间看! 最近在知乎经常被邀请回答类似如何学习C++和C++后台开发应该具体储备哪些基础技能的问题. 本身我从事的的C ...
- 用java分组查elasticsearch
哎,编程路漫漫,一坑又一坑,爬完还会掉,何时是尽头! 今朝有酒今朝醉,程序不对不敢睡! 还是接口昂,今天还是接口有问题,我是很菜,很笨,但是我还是要努力!! 正文: 接口需求是这样的,根据车型查询在线 ...
- 采用vue编写的功能强大的swagger-ui页面
think-swagger-ui-vuele swagger-ui有非常多的版本,觉得不太好用,用postman,每个接口都要自己进行录入.所以在基于think-vuele进行了swagger格式js ...