Python:基于MD5的文件监听程序
前述
写了一个基于MD5算法的文件监听程序,通过不同的文件能够生成不同的哈希函数,来实现实现判断文件夹中的文件的增加、修改、删除和过滤含有特定字符的文件名的文件。
需求说明
需要实现对一个文件夹下的文件的增加、修改和删除的监控, 一旦发生上述操作,则进行提示。可以选择过滤掉文件名中的特定字符和只监听文件名中含有特定字符的文件。
简述
- 首先,关于文件的增加、修改、删除的反馈,可以想到利用MD5等类似的加密算法,因为文件本身可以生成哈希值,只要文件内容或者文件名被修改过,就会生成和修改之前的哈希值不同的值,因此可以利用dict来存储,一个文件名对应一个哈希值来存储。其中增加和删除就对应一个新增加的键值对和一个减少的键值对,而修改则可以理解为删除了旧的文件、增加了一个新的文件。
MD5算法可以直接利用第三方的 hashlib 库来实现
m = hashlib.md5()
myFile = open(full_path, 'rb')
for line in myFile.readlines(): #以行为单位不断更新哈希值,避免文件过大导致一次产生大量开销
m.update(line) #最后可以得到整个文件的哈希值
- 第二,关于滤掉文件名中的特定字符和只监听文件名中含有特定字符的文件的功能,这个其实非常简单,只需要用 list 分别对需要过滤和必须存在字符串进行存储, 然后利用标志位和字符串的子串包含性进行判断就可以了,只有满足条件的文件可以产生哈希值,产生哈希值也就意味着被监听了。
判断字符串中是否含有字串最常用的方法是 in 和 string 中的 find 方法,这里就不再赘述,可以直接看下面的代码
- 第三,因为要同时监控多个文件夹,所以必须要利用到线程来处理,创建一个线程池来存储线程, 线程利用了 threading 库,并且实现一个线程类来处理线程的操作
class myListener(threading.Thread):
thread1 = myListener(mydir, json_list_include, json_list_exclude) #生成线程
说明
需要额外说明的一点是,在传输需要监听的文件夹、必须包含的字段以及过滤字段的时候,我这里是利用配置文件的形式来存储的。说到底,是利用 toml 格式的数据进行的传输,toml格式和 json格式相比,用户的可读性更强一些,为了便于博客展示,因此利用了 toml 格式
首先利用代码生成了一下toml格式的文件,以后再想用的话,程序打包之后,可以直接修改配置文件来实现对程序的控制。
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: JYRoooy
4 import collections
5 import json
6 import toml
7 if __name__ == '__main__':
8 myOrderDict = collections.OrderedDict
9 myOrderDict = {'dict':[{'path':'E:/testing', 'include':['log_'], 'exclude': ['.swp', '.swx', 'tmp']},{'path':'E:/tmp', 'include':['.record'], 'exclude': ['.tmp']}]}
10 myToml = toml.dump(myOrderDict, open('E:/python/code/PythonProject/tomlConfig.txt','w+'))
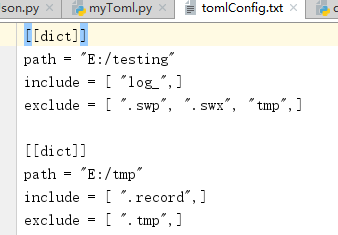
toml文件
格式说明, 一个 dict 对应一个监听的文件夹和需要 过滤(exculde) 和 含有(include) 的字段,解释一下,这里的字段只是文件名的字段,监控 E:/testing 目录下的文件,要包含 log_ 字段的文件,且不包含 .swp .swx .tmp 字段的文件, 并且监控 E:/tmp 目录下的文件,要包含 .record 字段的文件,且不包含 .tmp 的文件。
代码
完整程序的代码,具体解释可以看注释
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: JYRoooy
import toml
import hashlib
import os
import sys
import time
import importlib
import threading
importlib.reload(sys) class myListener(threading.Thread):
'''
监听类
'''
def __init__(self, input_dir, filt_in, filt_ex): #文件夹路径,必须包含的字符,必须过滤的字符
threading.Thread.__init__(self)
self.input_dir = input_dir
self.filt_in = filt_in
self.filt_ex = filt_ex
self.dict = {} #用来存储文件名和对应的哈希值
self.file_list = [] #存储每一次扫描时的文件的文件名
self.pop_list = [] #存储需要删除的文件名 def run(self):
while (1): #保证文件夹一直处于被监听的状态
for cur_dir, dirs, files in os.walk(self.input_dir):
if files != []:
self.file_list = []
for each_file_1 in files:
each_file = each_file_1
if self.filt_in: #判断文件名中是否有必须存在的字段
flagone = 0
for i in range(len(self.filt_in)):
if self.filt_in[i] in each_file:
flagone += 1
if flagone == 0:
continue if self.filt_ex: #判断文件名中是否有必须过滤掉的字段
flagtwo = 0
for i in range(len(self.filt_ex)):
if self.filt_ex[i] in each_file:
flagtwo = 1
if flagtwo==1:
continue self.file_list.append(each_file)
full_path = os.path.join(cur_dir, each_file)
m = hashlib.md5() #实例化md5算法 myFile = open(full_path, 'rb') for line in myFile.readlines():
m.update(line)
if each_file not in self.dict.keys(): #如果当前的dict中没有这个文件,那么就添加进去
self.dict[each_file] = m.hexdigest() #生成哈希值
print('文件夹:' +cur_dir+ "中的文件名为:" + each_file + "的文件为新文件" + time.strftime('%Y-%m-%d %H:%M:%S',
time.localtime(time.time())))
if each_file in self.dict.keys() and self.dict[each_file] != m.hexdigest(): #如果当前dict中有这个文件,但是哈希值不同,说明文件被修改过,则需要对字典进行更新
print('文件夹:' +cur_dir+ "中的文件名为:" + each_file + "的文件被修改于" + time.strftime('%Y-%m-%d %H:%M:%S',
time.localtime(time.time())))
self.dict[each_file] = m.hexdigest()
myFile.close()
pop_list = []
for i in self.dict.keys():
if i not in self.file_list: #当字典中有不在当前文件名列表中时,说明文件已经被删除
print('文件夹:' +cur_dir+ '中的文件名为:' + i + "的文件已被删除!!!" + time.strftime('%Y-%m-%d %H:%M:%S',
time.localtime(time.time())))
pop_list.append(i)
for i in pop_list:
self.dict.pop(i) time.sleep(2) if __name__ == '__main__':
threads = [] #用来存储线程的线程池
with open('E:/python/code/PythonProject/tomlConfig.txt','r+') as f: #读取toml格式的文件,并分解格式
mytoml = toml.load(f)
myList = mytoml['dict']
for i in range(len(myList)): #因为可能同时需要监听多个文件夹,所以利用线程池处理多线程
json_list_include = []
json_list_exclude = []
mydir = myList[i]['path']
for sublist in range(len(myList[i]['include'])):
json_list_include.append(myList[i]['include'][sublist])
for sublist in range(len(myList[i]['exclude'])):
json_list_exclude.append(myList[i]['exclude'][sublist])
thread1 = myListener(mydir, json_list_include, json_list_exclude) #生成线程
threads.append(thread1) for t in threads: #开启所有线程
t.start();
运行结果
两个文件夹中的文件
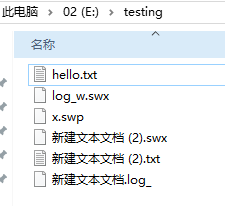
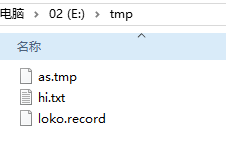
第一次运行程序, 可以看到已经按照过滤规则完成了过滤和监听

修改 loko.record 文件为 loko.re,再来看结果

可以看到已经完成了监听,因为 loko.re 文件,并符合监听的规则,所以不做出监听,而我们前面说过,一个修改相当于一个删除和一个新建操作,所以监听程序提示原文件被删除了
写在后面
其他的效果我就不一一展示了。
程序也没有实现很复杂的效果,代码已经上传 github -- https://github.com/JYRoy/MyFileListener
已经更新了Java版本的代码 https://www.cnblogs.com/jyroy/p/10575190.html
欢迎大佬们交流~
Python:基于MD5的文件监听程序的更多相关文章
- Java:基于MD5的文件监听程序
前述和需求说明 和之前写的 Python:基于MD5的文件监听程序 是同样的功能,就不啰嗦了,就是又写了一个java版本的,可以移步 python 版本去看一下,整个的核心思路是一样的.代码已上传Gi ...
- 一个基于Socket的http请求监听程序实现
首先来看以下我们的需求: 用java编写一个监听程序,监听指定的端口,通过浏览器如http://localhost:7777来访问时,可以把请求到的内容记录下来,记录可以存文件,sqlit,mysql ...
- (转)ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务 的解决方法
早上同事用PL/SQL连接虚拟机中的Oracle数据库,发现又报了"ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务"错误,帮其解决后,发现很多人遇到过这样的问 ...
- (转)解决 ORA-12514: TNS: 监听程序当前无法识别连接描述符中请求的服务
下面操作默认在安装Oralce数据库的服务器上运行. 1)确保Oracle 基本服务都已启动 OracleDBConsoleorcl OracleOraDb11g_home1TNSListener O ...
- ORA-12523: TNS: 监听程序无法找到适用于客户机连接的例程
今天使用PL/SQL Developer连接到一台新的测试服务器时,遇到ORA错误:ORA-12523: TNS: 监听程序无法找到适用于客户机连接的例程.对应的监听日志文件里面错误为TNS-1252 ...
- Oracle几个基础配置问题:ORA-12154: TNS: 无法解析指定的连接标识符、ORA-12514: TNS: 监听程序当前无法识别连接描述符中请求的服务、ORA-12516 TNS监听程序找不到符合协议堆栈要求的可用处理程序
问题1:ORA-12154: TNS: 无法解析指定的连接标识符 在一台服务器上部署了Oracle客户端,使用IP/SID的方式访问,老是报ORA-12154错误,而使用tnsnames访问却没有问题 ...
- oracle 11g ORA-12541: TNS: 无监听程序 (DBD ERROR: OCIServerAttach)
From :http://www.cnblogs.com/wangyt223/archive/2012/12/11/2812931.html em无法浏览,同时监听起不来.同时他的监听服务还是正常的, ...
- oracle 11g 一直提示 严重: 监听程序未启动或数据库服务未注册到该监听程序
From:http://blog.sina.com.cn/s/blog_6734ea6d0102v6sn.html 增加操作系统环境变量:ORACLE_HOSTNAME=localhost 然后在cm ...
- TNS-12541: TNS: 无监听程序 TNS-12560: TNS: 协议适配器错误 TNS-00511: 无监听程序
文章转自:http://www.luocs.com/archives/464.html 此文版权归作者 – yaogang所有,转载请注明yaogang©www.luocs.com. Luocs说:这 ...
随机推荐
- 源码安装xadmin及使用
xadmin是django的第三方后台 我们也可以使用pip来安装,但是推荐使用源码安装. 因为有些新功能以及发布在GitHub上,但是还未发布到pypi上,我们就可以提取使用这些功能. 一.安装 1 ...
- 解密TTY
本文内容来自The TTY demystified ,讲述了*NIX系统中TTY的历史与工作原理,看完后解决了我很多疑惑,于是做此翻译,与大家分享. 译者:李秋豪 江家伟 审校: V1.0 Sun M ...
- Java (六、String类和StringBuffer)
Java String 类 字符串广泛应用 在Java 编程中,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串. 创建字符串 // ==比较的是字符串在栈中存放的 ...
- 并发库应用之七 & 信号灯Semaphore应用
Semaphore可以维护当前访问自身的线程个数,并且提供了同步机制. Semaphore实现的功能类似于厕所里有5个坑,有10个人要上厕所,同时就只能有5个人占用,当5个人中 的任何一个让开后,其中 ...
- PAT1043:Is It a Binary Search Tree
1043. Is It a Binary Search Tree (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN ...
- ehcache与redis的比较与应用场景分析(转)
ehcache直接在jvm虚拟机中缓存,速度快,效率高:但是缓存共享麻烦,集群分布式应用不方便.redis是通过socket访问到缓存服务,效率比ecache低,比数据库要快很多,处理集群和分布式缓存 ...
- 二十六、Hadoop学习笔记————Hadoop Yarn的简介复习
1. 介绍 YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度. 之前有提到过,Yarn主要是为了减轻Hadoop ...
- spring boot -Properties & configuration
72. Properties & configuration72.1 Automatically expand properties at build timeRather than hard ...
- 玩转Web之SSH--Heibernate (一)---第一个demo
最近在学heibernate,是看马士兵老师的视频学的,在这里总结一下,做点笔记.关于heibernate的优点,大家可以在网上 百度,这里不做赘述,直接讲怎么使用heibernate 步骤一:新建项 ...
- linux下怎么样上传下载文件夹
Linux下目录复制:本机->远程服务器 scp -r /home/shaoxiaohu/test1 zhidao@192.168.0.1:/home/test2 test1为源目录,test2 ...