Hadoop分布式集群配置
硬件环境:
安装一个Hadoop集群时,需要专门指定一个服务器作为主节点。
三台虚拟机搭建的集群:(搭建集群时主机名不能一样,主机名在/etc/hostname修改)
master机器:集群的主节点,驻留NameNode和JobTracker守护进程)
dbrg1 192.168.0.102
slaves机器:(集群的从节点,驻留DataNode和TaskTracker守护进程)
dbrg2 192.168.0.112
dbrg3 192.168.0.113
这三台机器都安装好了hadoop-0.20.2,JDK和ssh。
安装方法参考上一篇博文。
共有3台机器,均使用的linux系统,Java使用的是sun
jdk1.7.0。
1. 修改主机名和IP地址
vi /etc/hostname(分别给每一台主机指定主机名)
vi /etc/hosts(分别给每一台主机指定主机名到IP地址的映射)
这里有一点需要强调的就是,务必要确保每台机器的主机名和IP地址之间能正确解析。一个很简单的测试办法就是ping一下主机名,比如在dbrg1上pingdbrg2,如果能ping通就OK!若不能正确解析,可以修改/etc/hosts文件,如果该台机器作Namenode用,则需要在hosts文件中加上集群中所有机器的IP地址及其对应的主机名;如果该台机器作Datanode用,则只需要在hosts文件中加上本机IP地址和Namenode机器的IP地址。
1. 三台机器都要修改/etc/hosts。
在dbrg1中添加:
192.168.0.102 dbrg1 dbrg1
192.168.0.112 dbrg2 dbrg2
192.168.0.113 dbrg3 dbrg3
在dbrg2中添加:
192.168.0.102 dbrg1 dbrg1
192.168.0.112 dbrg2 dbrg2
在dbrg3中添加:
192.168.0.102 dbrg1 dbrg1
192.168.0.113 dbrg3 dbrg3
2.免密码SSH设置
(1) 在三台机器上安装ssh,启动ssh-server。
sudo apt-get install openssh-server
sudo /etc/init.d/ssh start
ps -e|grep ssh //这个是检验命令
(2)在dbrg1上生成密钥对。
ssh-keygen -t -rsa //然后一直enter,按照默认的选项生成的密钥对保存在.ssh/id_rsa文件中
进入.ssh目录,输入
cp id_rsa.pub authorized_keys
执行 ssh localhost 看看需不需要输入命令
(3)远程拷贝
生成好后,需要将该文件传到dbrg2和3上
在dbrg1中的.ssh目录中,输入
scp authorized_keys dbrg2:/home/dbrg/.ssh/
scp authorized_keys dbrg3:/home/dbrg/.ssh/
说明:如果提示在dbrg2和3上没有此目录,记得创建。此处是需要输入密码的。
(4)修改权限。在dbrg2和dbrg3上对该文件进行权限修改
打开.ssh,输入
chmod 644 authorized_keys
(5)配置修改
在三台服务器上对sshd服务进行配置,都需要修改。在sudo vi /etc/ssh/sshd_config中
修改:PasswordAuthentictation no
AuthorizedKeyFile /home/dbrg/.ssh/authorized_keys
(6)检验
在dbrg1上,ssh dbrg2,输入yes,这样以后访问都不需要输入密码了
同样ssh dbrg3,输入yes。
之后再检验下,看看需不需要输入密码
3.Hadoop环境配置
在dbrg1中,打开hadoop目录,ls下,发现了conf文件夹,这个里面全是配置,打开
(1)修改hadoop_env.sh,输入:
export HADOOP_HOME=/home/dbrg/HadoopInstall/hadoop
export JAVA_HOME=/usr/java/jdk1.7.0
说明:根据实际的安装路径来,这是我机子上的
(2) 修改masters
删除localhost,改为dbrg1
(3)修改slaves
删除,改为dbrg2、dbrg3
(4)修改core-site.html //N啊么node IP地址及端口
在configuration之间加入:
<property>
<name>fs.default.name</name>
<value>hdfs://dbrg1:9000</value>
<description>The name and URI of the default FS.</description>
</property>
(5)修改mapred-site.html //Jobtracker 调度并记录任务的执行情况
在configuration之间加入:
<property>
<name>mapred.job.tracker</name>
<value>dbrg1:9001</value>
<description>Map Reduce jobtracker</description>
</property>
(6)修改hdfs-site.html //block的文件副本数
在configuration之间加入:
<property>
<name>dfs.replication</name>
<value>2</value>
<description>Default block replication</description>
</property>
(7)环境配置的拷贝
利用scp命令将上面修改的文件,替代dbrg2和dbrg3中的相应文件
4.HDFS的运行
在dbrg1中初始化namenode,在hadoop目录下,输入
bin/hadoop namenode -format
然后再三台机器上都要bin/start-all.sh下,启动了
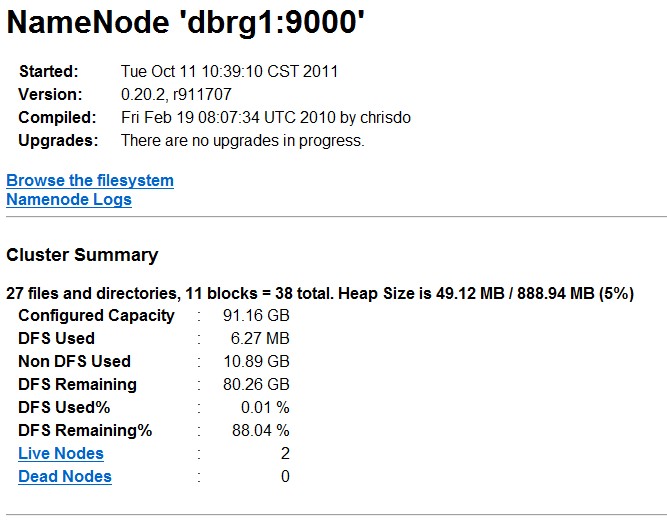
在dbrg1上可以查看,输入jps;或者可以通过http://dbrg1:50070查看

4. mapduce程序实例
参考网址:
http://blog.csdn.net/moodytong/article/details/6862020
http://www.cnblogs.com/welbeckxu/archive/2011/12/30/2306887.html
http://puxuanling.blog.163.com/blog/static/87476635201210704825265/
http://wenku.baidu.com/view/91e0240b52ea551811a68706.html
问题解决篇:
http://lwjlaser.iteye.com/blog/1443147
Hadoop分布式集群配置的更多相关文章
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- hadoop分布式集群的搭建
电脑如果是8G内存或者以下建议搭建3节点集群,如果是搭建5节点集群就要增加内存条了.当然实际开发中不会用虚拟机做,一些小公司刚刚起步的时候会采用云服务,因为开始数据量不大. 但随着数据量的增大才会考虑 ...
随机推荐
- TPYBoard开发板搭建与阿里云服务发送数据
今天给大家带来的是TPYBoard V202开发板的一次测试项目使用心得.而测试项目就是给服务端发送硬件底层数据,而数据有产品名称,WF模块MAC地址,温湿度数据. 什么是MicroP ...
- python-day2数据类型
内容介绍 数据类型 字符编码 文件处理 1.什么是数据? x=10 , 10是我们要存储的数据. 2.为何数据要分不同的类型 数据是用来表示状态的,不同的状态就应该用不同的类型的数据去表示 3.数据类 ...
- traffic server文件目录
功能: Trafficserver的主要功能是缓存,当然你也可以用它来做纯粹的反向代理(像通常用nginx那样).通常切入一个庞大的系统的最好方式是看如何使用,使用traffic server的主要入 ...
- 2018Pycharm激活方法
1.将"0.0.0.0 account.jetbrains.com"添加到hosts文件中 2.打开http://idea.lanyus.com/ 3.获取激活码,粘贴到第二个选项 ...
- 史上最全的JFinal源码分析(不间断更新)
打算 开始 写 这么 一个系列,希望 大家 喜欢,学习 本来就是 一个查漏补缺的过程,希望大家能提出建议.本篇 文章 是整个目录的向导,希望 大家 喜欢.本文 将以 包的形式跟大家做向导. Handl ...
- 史上最大的CPU Bug(幽灵和熔断的OS&SQLServer补丁)
背景 最近针对我们的处理器出现了一系列的严重的bug.这种bug导致了两个情况,就是熔断和幽灵. 这就是这几天闹得人心惶惶的CPU大Bug.消息显示,以英特尔处理器为代表的现代CPU中,存在可以导致数 ...
- zalenium 应用
zalenium是一个Selenium Grid扩展,用Docker容器动态扩展你的本地网格.它使用docker-selenium在本地运行Firefox和Chrome中的测试,如果需要不同的浏览器, ...
- php与web页面交互
一.web表单 web表单的功能是让浏览者和网站有一个互动的平台.web表单主要用来在网页中发送数据到服务器. 1.1 表单的创建 使用form标记,并在其中插入相关的表单元素,即可创建一个表单. & ...
- ionic2+Angular 使用HttpInterceptorService拦截器 统一处理数据请求
sstep1:新建http-Interceptor.ts文件 import { Injectable } from '@angular/core'; import { HttpInterceptorS ...
- 脚本实现centos7修改二块网卡名称并配置ip信息
#!/bin/bash interface1=`ls /sys/class/net|grep en|awk 'NR==1{print}'`interface2=`ls /sys/class/net|g ...