HBase 笔记2
Hadoop 服务启动顺序: zookeeper -》journalnode-》namenode -> zkfc -> datanode
HBase Master WEB控制台: <Master>:60010
如果RegionServer正常启动,但是连接不上Master自己又停止,而Master/Region Server之间网络连接,端口可见性正常,多半是/etc/hosts内映射不正确或/etc/sysconfig/network内hostname设置有问题
HBase自带一个命令行工具 hbase shell
进入hbase 命令行: $HBASE_HOME/bin/hbase shell
创建表: create 'test','cf' ====>创建表test,包含一个列族cf
查看库中有哪些表: list
查看表的属性:describe 'test'
建新列族: alter 'test','cf2' ====>新增列族cf2
插入数据:put 'test','row1','cf:name','jack' 向表test的行键为row1的行的cf列族下的name列插入数据,值为Jack
修改HBase保留的版本数:alter 'test',{NAME=>'cf',VERSION=>5} ===>设置表test的cf列族保留版本数为5,默认为1(即使单元格插入多个版本数据,也只会保留最新版本)
查看数据:get 'test','row2',{COLUMN=>'cf:name',VERSION=>3} ====>获取表test,row2行,cf列族下name列的最近3个版本数据
get 'test','row7','cf:name' ===》显示某个单元格的全部数据
遍历表的全部数据: scan '表名'
遍历表的部分数据:scan 'test',{STARTROW=>'row3'} ===>显示所有rowkey大于且等于row3的数据
scan 'test',{ENDROW=>'row4'} ====>显示所有rowkey小于row4的数据
删除数据: delete 'test','row4','cf:name' ====>删除表test中的row4行中的cf:name单元格数据
根据版本删除数据:delete 'test','row1','cf:name',ts ====>删除ts版本之前的所有版本数据(包含这个版本)
HBase删除数据并不是真正删除数据,而是放置了一个墓碑标记,导致这个版本+之前的版本都不可见
删除整行数据: deleteall 'test','row3' ===>删除test表的row3的整行数据
查看打上墓碑标记的数据:scan 'test',{RAW=>true,VERSION=>5} ===>查询最近的5个版本的数据,墓碑隐藏数据也显示
停用表: disable 'test'
删除表: 删除表之前需要停用表
drop 'test'
通用命令:
查看集群状态 status 'summary' | 'simple' | 'detailed'
查看HBase版本: version
查看当前用户: whoami
查看表操作信息: table_help
表操作:
list 列出所有的表名
alter 更改表/列族的定义
1)建立/修改列族
列族属性 BLOOMFILTER REPLICATION_SCOPE MIN_VERSIONS COMPRESSION TTL BLOCKSIZE IN_MEMORY IN_MEMORY_COMPACTION BLOCKCACHE KEEP_DELETED_CELLS DATA_BLOCK_ENCODING
CACHE_DATA_ON_WRITE CACHE_DATA_IN_L1 CACHE_BLOOMS_ON_WRITE CACHE_INDEX_ON_WRITE EVICT_BLOCKS_ON_CLOSE PREFETCH_BLOCKS_ON_OPEN ENCRYPTION ENCRYPTION_KEY IS_MOB_BYTES
MOB_THRESHOLD_BYTES
格式: alter '表名',NAME=>'列族',属性名1=>属性值1,....
2)修改/建立多个列族
格式:alter '表名',{NAME=>'列族',属性名1=>属性值1,....},{NAME=>'列族',属性名1=>属性值1,....}
3)删除列族:
格式: alter '表名',‘delete’=>‘列族名’
4)修改表级别的属性
格式:alter '表名',属性名1=>属性值1,......
5)设置表的配置
格式 : alter '表名',CONFIGURATION => {'配置名' => '配置值'}
alter '表名',{NAME=> '列族名',CONFIGURATION => {'配置名' => '配置值'}}
例: alter 'test',{NAME=>'cf1',CONFIGURATION => {'hbase.hstore.blockingStoreFiles' => '15'}}
6) 删除表级别的属性
格式:alter '表名',METHOD=>'table_att_unset',NAME=>'属性名'
7)同时执行多个命令
格式:alter '表名‘,command1,command2,command3,....

create 建立新表
格式:create '表名','列族1',’列族2‘,....
create '表名’,{NAME=>'列族1',属性名=>属性值},{NAME=>'列族2',属性名=>属性值},....
alter_status 查看表的各个Region的更新状况
alter_async 异步更新表
格式:alter_async '表名',参数列表
describe 输出表的描述信息
格式:describe '表名‘ 或 desc '表名'
dsiable 停用指定表
格式:disable '表名'
disable_all 使用正则表达式来停用多个表
格式:disable_all '正则表达式'
is_disabled 检测指定表是否被停用
格式: is_disabled ’表名‘
drop 删除指定表
格式 drop '表名'
drop_all 通过正则表达式删除多个表
格式:drop_all 正则表达式
enable 启动指定表
格式:enable '表名'
enable_all 通过正则表达式启动指定表
格式:enable_all '正则表达式'
is_enabled 判断表是否启用
格式: is_enabled '表名'
exists 判断表是否存在
格式:exists ’表名‘
show_filters 列出所有过滤器
get_table 把表名转换成一个对象
格式: 变量 = get_table '表名'
locate_region 定位传入的行键对应的行在哪个Region里面
格式:locate_region '表名',’行键‘
数据操作:
scan 按照字典排序遍历表的数据
格式:scan '表名'
scan '表名',{COLUMNS => ['列1 ',....]} 遍历指定列
scan ‘表名' {STARTROW => '起始行键',END_ROW =》 ’结束行键‘}
scan '表名',{LIMIT => 行数量} 指定返回的行数量
scan '表名',{TIMERANGE => [最小时间戳,最大时间戳]} ===》包含最小时间戳,最大不包含
scan '表名',{VERSIONS => 版本数} 显示多个版本值
scan '表名',{RAW =》 true ,VERSIONS => 版本数} 显示原始单元格记录
scan '表名',{FILTER => '过滤器'}
get 通过行键获取某行记录
格式: get '表名',’行键‘
count 计算表的行数
格式: count ’表名‘
1)指定计算步长
格式:count '表名',INTERVAL => 行数计算步长
2)指定缓存加速计算过程
格式: count '表名',cache => 缓存条数
INTERVAL 和CACHE可以同时使用
delete 删除某列数据
格式:delete ’表名‘,’行键‘,’列名‘ 【,时间戳】
deleteall 删除整行数据
格式:deleteall ’表名‘ ,’行键‘
deleteall '表名',’行键‘,‘列名’
deleteall '表名',‘行键’,‘列明’,时间戳
incr 为计数器单元格的值加一,若单元格不存在则创建
格式: incr '表名',‘行键’,‘列名’【,加减值】
put 新增记录 or 设置属性
格式:put '表名',‘行键’,‘列名’,‘值’【,时间戳】
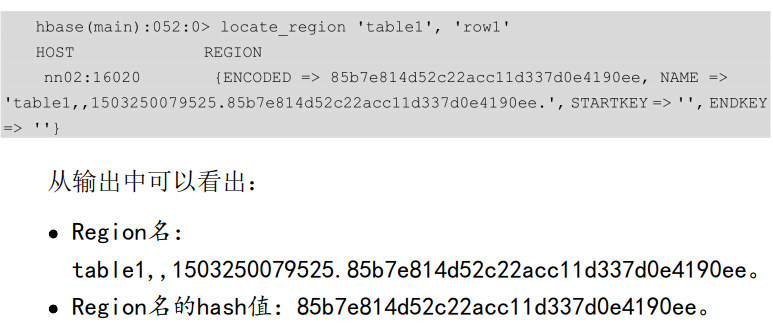
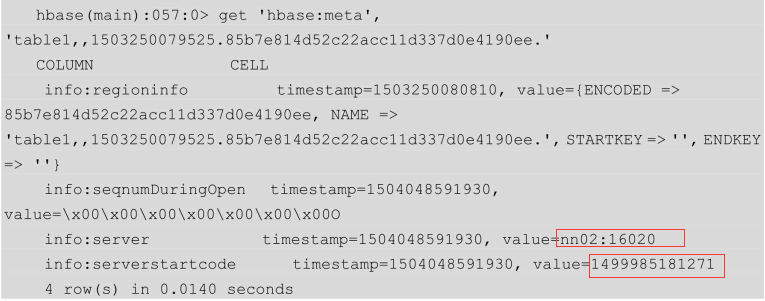
通过查询hbase:meta获取某个region的信息,如服务器的标识码
HBase 笔记2的更多相关文章
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase笔记——RowKey设计
一).什么情况下使用Hbase 1)传统数据库无法承载高速插入.大量读取. 2)Hbase适合海量,但同时也是简单的操作. 3)成熟的数据分析主题,查询模式确立不轻易改变. 二).现实场景 1.电商浏 ...
- HBase笔记--自定义filter
自定义filter需要继承的类:FilterBase 类里面的方法调用顺序 方法名 作用 1 boolean filterRowKey(Cell cell) 根据row key过滤row.如果需要 ...
- HBase笔记--filter的使用
HBASE过滤器介绍: 所有的过滤器都在服务端生效,叫做谓语下推(predicate push down),这样可以保证被过滤掉的数据不会被传送到客户端. 注意: 基于字符串的比较器,如 ...
- HBase笔记--编程实战
HBase总结:http://blog.csdn.net/lifuxiangcaohui/article/details/39997205 (very good) Spark使用Java读取hbas ...
- HBase笔记--安装及启动过程中的问题
1.使用hbase shell的时候运行命令执行失败 例如:在shell下执行 status,失败. 可能的原因:节点之间的时间差距过大 解决方法调整两个节点的时间,使二者一致,这里用了个比较笨的方法 ...
- HBase笔记6 过滤器
过滤器 过滤器是GET或者SCAN时过滤结果用的,相当于SQL的where语句 HBase中的过滤器创建后会被序列化,然后分发到各个region server中,region server会还原过滤器 ...
- HBase笔记5(诊断)
阻塞急救: RegionServer内存设置太小: 解决方案: 设置Region Server的内存要在conf/hbase-env.sh中添加export HBASE_REGIONSERVER_OP ...
- HBase笔记4(调优)
Master/Region Server调优 JVM调优 默认的RegionServer内存是1G,而Memstore默认占40%,即400M,实在是太小了,可以通过HBASE_HEAPSIZE参数修 ...
- HBase 笔记3
数据模型 Namespace 表命名空间: 多个表分到一个组进行统一的管理,需要用到表命名空间 表命名空间主要是对表分组,对不同组进行不同环境设定,如配额管理 安全管理 保留表空间: HBase中有 ...
随机推荐
- sqoop导入数据到hive中元数据问题
简单配置了sqoop之后开始使用,之前用的时候很好用,也不记得有没有启动hivemetastore,今天用的时候没有启动,结果导入数据时,如果使用了db.tablename,就会出现找不到数据库的错, ...
- python 读取大文件,按照字节读取
def read_bigFile(): f = open("123.dat",'r') cont = f.read() : print(cont) cont = f.read() ...
- SparkStreaming:关于checkpoint的弊端
当使用sparkstreaming处理流式数据的时候,它的数据源搭档大部分都是Kafka,尤其是在互联网公司颇为常见. 当他们集成的时候我们需要重点考虑就是如果程序发生故障,或者升级重启,或者集群宕机 ...
- Altium designer软件如何设计原理图库封装图库以及交互式布局
欢迎大家关注http://www.raymontec.com(个人专博) Altium Designer学习—认识界面以及PCB设计整体要求 http://www.raymontec.com/alti ...
- Direct3D 11 Tutorial 7:Texture Mapping and Constant Buffers_Direct3D 11 教程7:纹理映射和常量缓冲区
概述 在上一个教程中,我们为项目引入了照明. 现在我们将通过向我们的立方体添加纹理来构建它. 此外,我们将介绍常量缓冲区的概念,并解释如何使用缓冲区通过最小化带宽使用来加速处理. 本教程的目的是修改中 ...
- list add对象踩的坑
list 添加对象时,没有把new object写到循环体里,导致最后添加了相同的一个对象: public List<goods> find(String goodsname) { Lis ...
- 告别GOPATH,快速使用 go mod(Golang包管理工具)
https://studygolang.com/articles/17508?fr=sidebar 文中的wserver为module名,route为本地的包名,go.mod所在的目录名不一定非要和m ...
- KafkaManager对offset的两种管理方式
OffsetManager主要提供对offset的保存和读取,每个broker都有一个OffsetManager实例,kafka管理topic的偏移量有2种方式: 1.ZookeeperOffsetM ...
- PHP 数组转XML 格式
function buildXml( $data, $wrap= 'xml' ){ $str = "<{$wrap}>"; if( is_array( $data ) ...
- C# TreeView 拖拽节点到另一个容器Panel中简单实现
C# TreeView 拖拽节点到另一个容器Panel中简单实现 用了这么久C#拖拽功能一直没有用到也就没用过,今天因为项目需要,领导特地给我简单讲解了下拖拽功能,真是的大师讲解一点通啊.特地写一篇博 ...