正则化--Lambda
模型开发者通过以下方式来调整正则化项的整体影响:用正则化项的值乘以名为 lambda(又称为正则化率)的标量。也就是说,模型开发者会执行以下运算:
执行 L2 正则化对模型具有以下影响:
- 使权重值接近于 0(但并非正好为 0)
- 使权重的平均值接近于 0,且呈正态(钟形曲线或高斯曲线)分布。
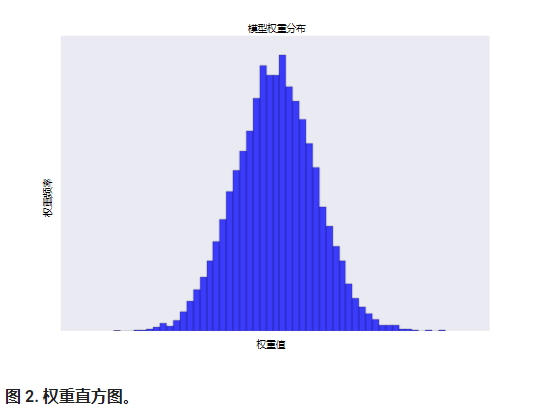
增加 lambda 值将增强正则化效果。 例如,lambda 值较高的权重直方图可能会如图 2 所示。
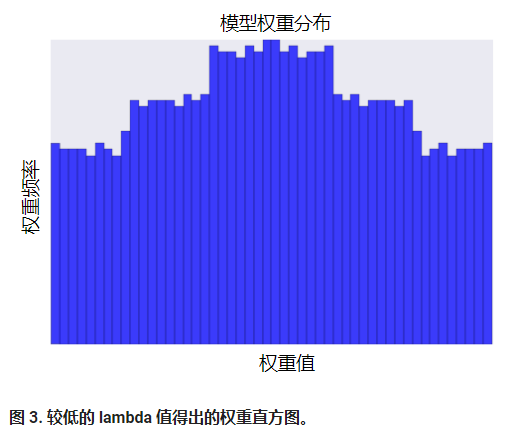
降低 lambda 的值往往会得出比较平缓的直方图,如图 3 所示。
在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡:
- 如果您的 lambda 值过高,则模型会非常简单,但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测。
- 如果您的 lambda 值过低,则模型会比较复杂,并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。
- 将 lambda 设为 0 可彻底取消正则化。 在这种情况下,训练的唯一目的将是最小化损失,而这样做会使过拟合的风险达到最高。
理想的 lambda 值生成的模型可以很好地泛化到以前未见过的新数据。 遗憾的是,理想的 lambda 值取决于数据,因此您需要手动或自动进行一些调整。
了解 L2 正则化和学习速率
学习速率和 lambda 之间存在密切关联。强 L2 正则化值往往会使特征权重更接近于 0。较低的学习速率(使用早停法)通常会产生相同的效果,因为与 0 的距离并不是很远。 因此,同时调整学习速率和 lambda 可能会产生令人混淆的效果。
早停法指的是在模块完全收敛之前就结束训练。在实际操作中,我们经常在以在线(连续)方式进行训练时采取一些隐式早停法。也就是说,一些新趋势的数据尚不足以收敛。
如上所述,更改正则化参数产生的效果可能会与更改学习速率或迭代次数产生的效果相混淆。一种有用的做法(在训练一批固定的数据时)是执行足够多次迭代,这样早停法便不会起作用。
引用
简化正则化 (Regularization for Simplicity):Lambda
正则化--Lambda的更多相关文章
- 论XGBOOST科学调参
XGBOOST的威力不用赘述,反正我是离不开它了. 具体XGBOOST的原理可以参见之前的文章<比XGBOOST更快--LightGBM介绍> 今天说下如何调参. bias-varianc ...
- 【原】Coursera—Andrew Ng机器学习—编程作业 Programming Exercise 4—反向传播神经网络
课程笔记 Coursera—Andrew Ng机器学习—课程笔记 Lecture 9_Neural Networks learning 作业说明 Exercise 4,Week 5,实现反向传播 ba ...
- Andrew Ng机器学习总结(自用)
监督学习: 线性回归,逻辑回归,神经网络,支持向量机. 非监督学习: K-means,PCA,异常检测 应用: 推荐系统,大规模机器学习 机器学习系统优化: 偏差/方差,正则化,下一步要进行的工作:评 ...
- XGBoost和LightGBM的参数以及调参
一.XGBoost参数解释 XGBoost的参数一共分为三类: 通用参数:宏观函数控制. Booster参数:控制每一步的booster(tree/regression).booster参数一般可以调 ...
- lambda正则化参数的大小影响
当lambda的值很小时,其惩罚项值不大,还是会出现过拟合现象,当时lambda的值逐渐调大的时候,过拟合现象的程度越来越低,但是当labmda的值超过一个阈值时,就会出现欠拟合现象,因为其惩罚项太大 ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
- stanford coursera 机器学习编程作业 exercise 5(正则化线性回归及偏差和方差)
本文根据水库中蓄水标线(water level) 使用正则化的线性回归模型预 水流量(water flowing out of dam),然后 debug 学习算法 以及 讨论偏差和方差对 该线性回归 ...
- 正则化(Regularization)
正则化(Regularization)是机器学习中抑制过拟合问题的常用算法,常用的正则化方法是在损失函数(Cost Function)中添加一个系数的\(l1 - norm\)或\(l2 - norm ...
- 深度神经网络(DNN)的正则化
和普通的机器学习算法一样,DNN也会遇到过拟合的问题,需要考虑泛化,这里我们就对DNN的正则化方法做一个总结. 1. DNN的L1&L2正则化 想到正则化,我们首先想到的就是L1正则化和L2正 ...
随机推荐
- 13.OpenStack常用命令
常用的命令 使用trove create创建数据库 trove create name --size= --databases DBNAME \ --users USER:PASSWORD --dat ...
- centos7 挂载exfat格式的u盘
下载 两个包 rpm -ivh http://download1.rpmfusion.org/free/el/updates/7/x86_64/f/fuse-exfat-1.2.8-1.el7.x86 ...
- java的unity单元测试
import org.junit.After; import org.junit.Before; import org.junit.Test; public class TestUnit { publ ...
- 鸭子-策略模式(Strategy)
前言 万事开头难,最近对这句话体会深刻!这篇文章是这个系列正式开始介绍设计模式的第一篇,所以肩负着确定这个系列风格的历史重任,它在我脑袋里默默地酝酿了好多天,却只搜刮出了一点儿不太清晰的轮廓,可是时间 ...
- Laravel中setAttribute和queryScope的用法
setAttribute使用场景: 数据在存入数据库的时候需要进行预先处理,每次都会写很多重复代码,使用 setAttribute之后就可以在数据填充时自动完成. setAttribute的写法:se ...
- Linux下配置APUE的编译环境
APUE即Unix环境高级编程,本书中几乎所有的程序都包含一个apue.h的头文件,那如何配置这个apue.h呢? 1.我们可以在http://pan.baidu.com/s/1dDxmtbF中下载, ...
- springboot静态资源映射
springboot静态资源映射 WebMvcAutoConfiguration @Override public void addResourceHandlers(ResourceHandlerRe ...
- 树链剖分【p4315】月下"毛景树"
Description 毛毛虫经过及时的变形,最终逃过的一劫,离开了菜妈的菜园. 毛毛虫经过千山万水,历尽千辛万苦,最后来到了小小的绍兴一中的校园里. 爬啊爬~爬啊爬毛毛虫爬到了一颗小小的" ...
- JQuery里面的知识
JQuery是一个javaScript库 JQuery极大的简化了javaScript编程 通过点击 "TIY" 按钮来看看它是如何运行的. 演示JQuery的hide函数,隐藏了 ...
- 内连接(INNER JOIN)
内连接组合两张表,并且基于两张表中的关联关系来连接它们.使用内连接需要指定表中哪些字段组成关联关系,并且需要指定基于什么条件进行连接.内连接的语法如下: INNER JOIN table_name O ...