大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接

Hive主要分为以下几个部分
⽤户接口
1.包括CLI,JDBC/ODBC,WebUI
元数据存储(metastore)
1.默认存储在⾃带的数据库derby中,线上使⽤时⼀般换为MySQL
驱动器(Driver)
1.解释器、编译器、优化器、执⾏器
Hadoop
1.⽤MapReduce 进⾏计算,⽤HDFS 进⾏存储
前提部分:Hive的安装需要在Hadoop已经成功安装且成功启动的基础上进行安装。若没有安装请移步至大数据系列之Hadoop分布式集群部署。
使用包: apache-hive-2.1.1-bin.tar.gz, mysql-connector-java-5.1.27-bin.jar
云盘,密码:seni
本文将Hive安装在Hadoop Master节点上,以下操作仅在master服务器上进行操作。
1. 切换至普通用户 su mfz
2. 将gz包上传至目录下
/home/mfz
3.解压
tar -xzvf apache-hive-2.1.1-bin.tar.gz
4.目录:

5.创建hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>ThriftURIfor theremotemetastore. Usedbymetastoreclientto connectto remotemetastore.</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_13?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>locationofdefault databasefor thewarehouse</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>datanucleus.schema.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>beeline.hs2.connection.user</name>
<value>mfz</value>
</property>
<property>
<name>beeline.hs2.connection.password</name>
<value>111111</value>
</property>
</configuration>
5.1由配置文件可看出,我们需要mysql的数据库hive_13,数据库用户名为hadoop,数据库密码为hadoop.
6.安装mysql
6.1 安装参考文章:Linux学习之CentOS(十三)--CentOS6.4下Mysql数据库的安装与配置
6.2 建立mysql数据库、用户、权限 参考文章:使用MySQL命令行新建用户并授予权限的方法
7.启动验证Mysql是否安装配置成功 :使用hadoop用户登录
mysql -u hadoop -p

8.配置hive环境变量:
vi /home/mfz/.bash_profile
#Hive CONFIG
export HIVE_HOME=/home/mfz/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin #wq .bash_profile
#生效配置
source /home/mfz/.bash_profile
#验证是否生效
echo $HIVE_HOME [mfz@master apache-hive-2.1.1-bin]$ echo $HIVE_HOME
/home/mfz/apache-hive-2.1.1-bin
9. 将mysql的java connector复制到依赖库中
cp resources/msyql/mysql-connector-java-5.1.27-bin.jar apache-hive-2.1.1-bin/bin/
10.启动hive,命令: hive; 若出现如下几种错误请参照对应解决方案;
错误1:
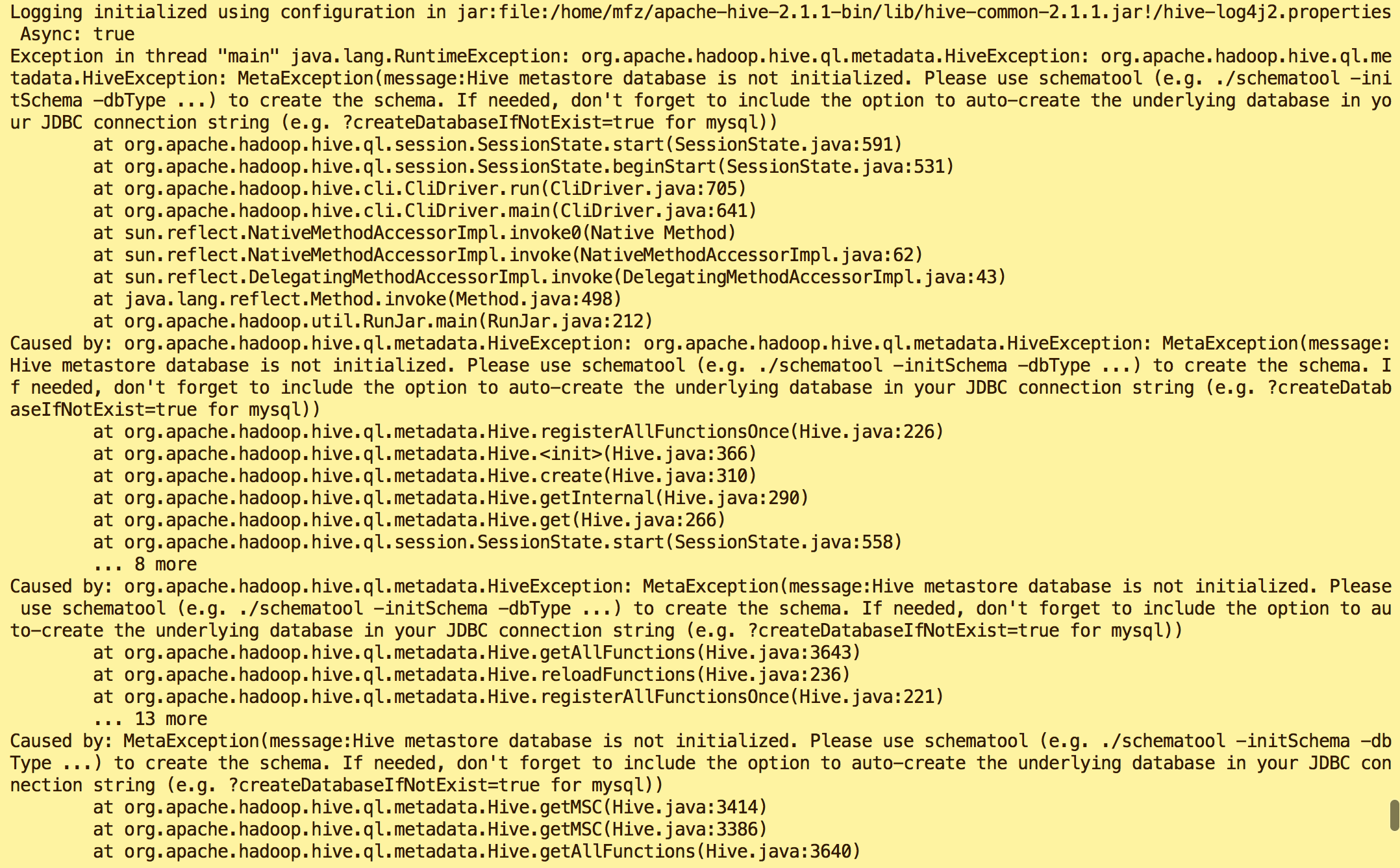
原因:Hive metastore database is not initialized
解决方案:执行命令
schematool -dbType mysql -initSchema
错误2:
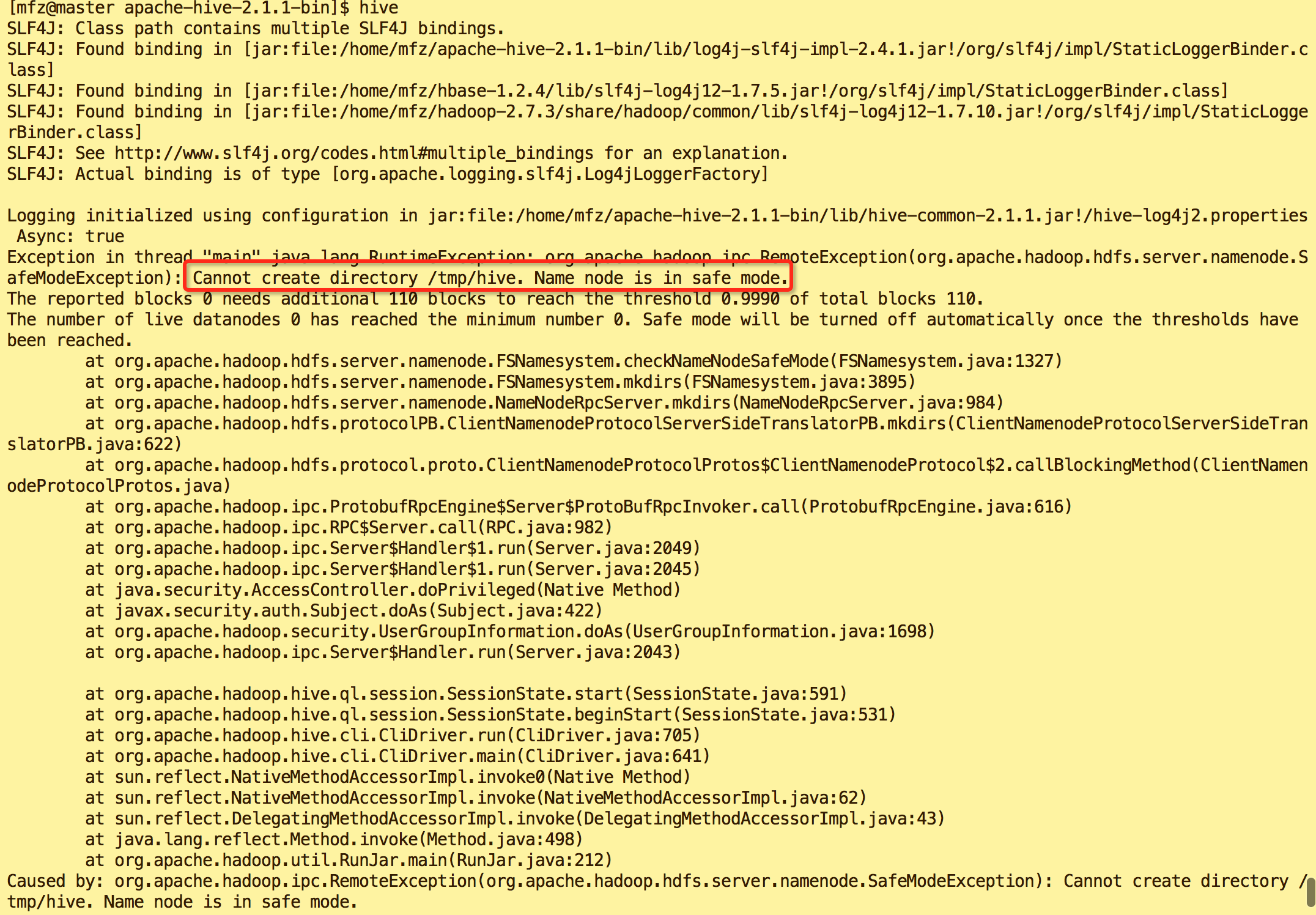
原因:hadoop 安全模式打开导致
解决方案:执行命令
#关闭hadoop安全模式
hadoop dfsadmin -safemode leave
11.启动hive.
A.方式1: hive命令

B.方式2(重要):
beeline
!connect jdbc:hive2://master:10000/default mfz 111111
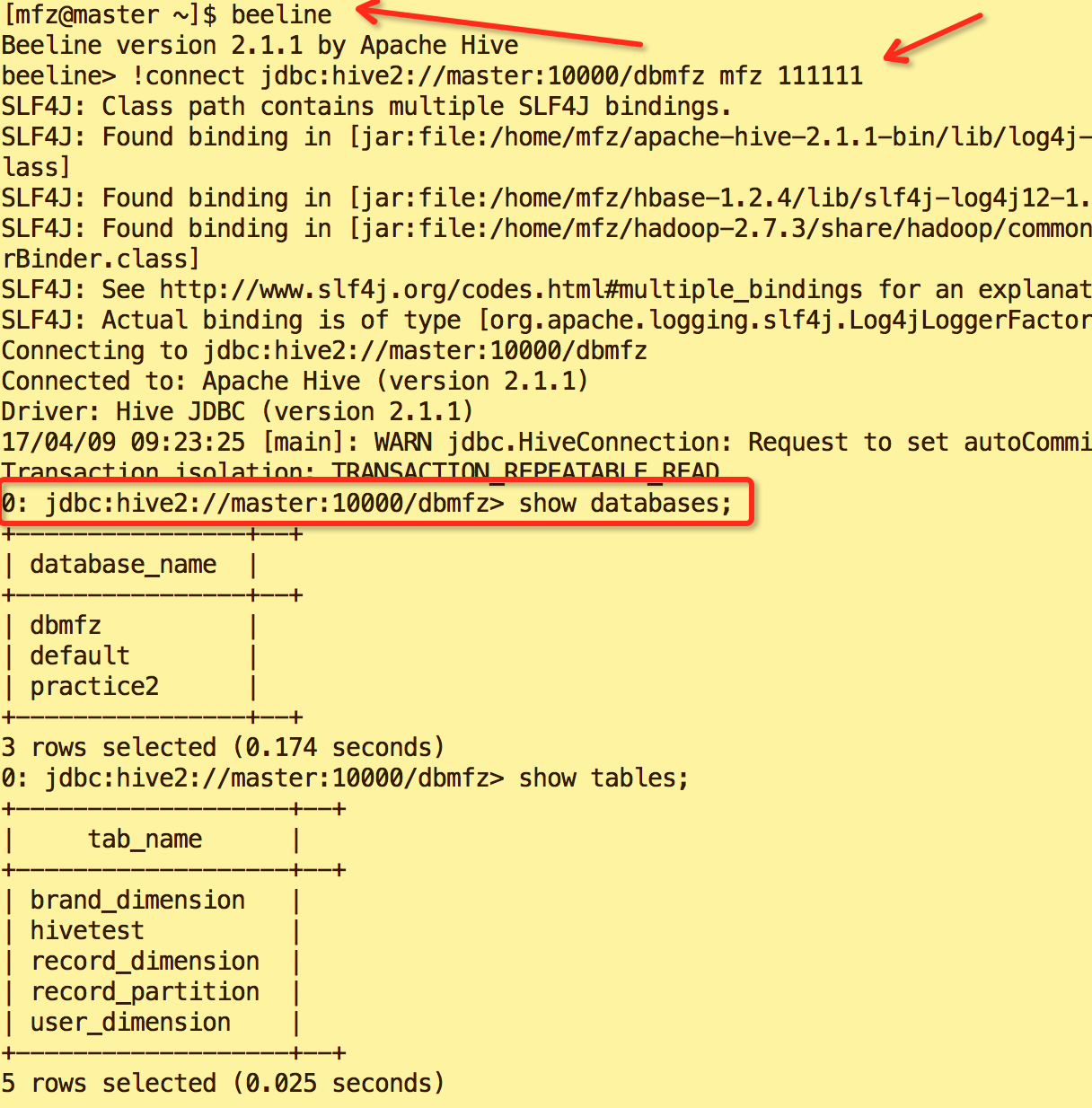
说明default是database名称,mfz是master服务器用户,111111是用户的登录密码.
因为beeline是取代hive客户端的新客户端,它访问HS2来发起hive操作,但是别急着敲下命令,继续往下看:这里涉及一个hadoop.proxy的概念:默认HS2是以user=anonymous身份访问Hdfs的,我们称HS2是hadoop的一个代理服务。但是,我们实际上希望以mfz身份去访问hdfs,因为此前创建的hive数据目录都是属于mfz用户的,anonymous是无法访问的,那么此时就需要给hadoop配置一个proxyuser,意思是HS2代理可以支持用户以mfz身份访问hdfs,而不是anonymous用户。
为了实现这个能力,需要修改hadoop项目的core-site.xml配置来实现(记得重启namenode和datanode):
<property>
<name>hadoop.proxyuser.mfz.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mfz.hosts</name>
<value>*</value>
</property>
10.hive 使用命令.
数据定义语句DDL
Create/Drop/Alter Database
Create/Drop/Truncate Table
Alter Table/Partition/Column
Create/Drop/Alter View
Create/Drop/Alter Index
Create/Drop Function
Create/Drop/Grant/Revoke Roles and Privileges
Show
Describe
完~ 关于Hive的Nosql操作命令与Jdbc访问Hive方式见博文 大数据系列之数据仓库Hive使用
转载请注明出处:
作者:mengfanzhu
原文链接:http://www.cnblogs.com/cnmenglang/p/6661488.html
大数据系列之数据仓库Hive安装的更多相关文章
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- 【大数据系列】win10上安装hadoop开发环境
为了方便采用了Cygwin模拟linux环境的方法 一.安装JDK以及下载hadoop hadoop官网下载hadoop http://hadoop.apache.org/releases.html ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
随机推荐
- RabbitMQ-从基础到实战(3)— 消息的交换(上)
转载请注明出处 0.目录 RabbitMQ-从基础到实战(1)— Hello RabbitMQ RabbitMQ-从基础到实战(2)— 防止消息丢失 RabbitMQ-从基础到实战(4)— 消息的交换 ...
- Rendertron:谷歌 Chrome 新的 headless 模式又贡献了一个新的技巧
摘自:https://zhuanlan.zhihu.com/p/31670033 Rendertron:JavaScript Web 富应用的一个老问题是如何使这些页面的动态渲染部分可供搜索引擎检索. ...
- Servlet 生命周期、工作原理-是单实例多线程
Servelet是单实例多线程的 参考:servlet单实例多线程模式 一.Servlet生命周期 大致分为4部:Servlet类加载-->实例化-->服务-->销毁 1.Web C ...
- 【BZOJ1019】[SHOI2008]汉诺塔(数论,搜索)
[BZOJ1019][SHOI2008]汉诺塔(数论,搜索) 题面 BZOJ 洛谷 题解 首先汉诺塔问题的递推式我们大力猜想一下一定会是形如\(f_i=kf_{i-1}+b\)的形式. 这个鬼玩意不好 ...
- bzoj2817[ZJOI2012]波浪
题目链接: http://www.lydsy.com/JudgeOnline/problem.php?id=2817 波浪 [问题描述] 阿米巴和小强是好朋友. 阿米巴和小强在大海旁边看海水的波涛.小 ...
- 【转】Keil ARM开发 error L6236E错误解决
顺利创建了第一个Keil工程却发现不能完成链接,出现了一个下面这样的报错: .\Objects\demo_simple.sct(7): error: L6236E: No section matche ...
- 团队Git使用教程
团队git使用教程(不要使用IDE自带版本控制功能) 角色分配:项目观察者.项目拥有者.项目开发人员 场景:项目拥有者创建项目 1. 在当前目录新建一个git代码库 git init "te ...
- 【UVA514】铁轨
题目大意:给定 N 个数,编号从 1 到 N,现需要判断,利用一个无限大的栈结构,能否实现到给定序列的转换. 题解:本题一共涉及三个部分的交互,分别是目标序列,栈和初始序列,由栈的顶端进入,顶端弹出性 ...
- 【洛谷P1471】方差
题目大意:维护一个有 N 个元素的序列,支持以下操作:区间加,区间询问均值,区间询问方差. 题解:可知区间均值和区间和有关,即:维护区间和就等于维护了区间均值.区间方差表达式为 \(\frac{\Si ...
- C# 分析 IIS 日志(Log)
由于最近又要对 IIS日志 (Log) 分析,以便得出各个搜索引擎每日抓取的频率,所以这两天一直在尝试各个办法来分析 IIS 日志 (Log),其中尝试过:导入数据库.Log parser.Powse ...