Hadoop化繁为简(一)-从安装Linux到搭建集群环境
简介与环境准备
hadoop的核心是分布式文件系统HDFS以及批处理计算MapReduce。近年,随着大数据、云计算、物联网的兴起,也极大的吸引了我的兴趣,看了网上很多文章,感觉还是云里雾里,很多不必要的配置都在入门教程出现。通过思考总结与相关教程,我想通过简单的方式传递给同样想入门hadoop的同学。其实,如果你有很好的Java基础,当你入门以后,你会感觉到hadoop其实也是很简单的,大数据无非就是数据量大,需要很多机器共同来完成存储工作,云计算无非就是多台机器一起运算。
操作建议:理论先了解三分,先实践操作完毕,再回头看理论,在后续文章我将对理论进行分析,最后用思维导图总结了解它的hadoop的整体面貌。
环境准备:https://pan.baidu.com/s/10Fd-dfeP0Ozk3pXmXb9n9Q 密码:bciy(建议自己去官网下环境,要原生原味的,不要二手货)
CentOS-Linux系统:CentOS-7-x86_64-DVD-1511.iso
VirtualBox虚拟机:VirtualBox-5.1.18-114002-Win.exe
xshell远程登录工具:xshell.exe
xftp远程文件传输:xftp.exe
hadoop:hadoop-2.7.3.tar.gz
jdk8:jdk-8u91-linux-x64.rpm
hadoop的物理架构
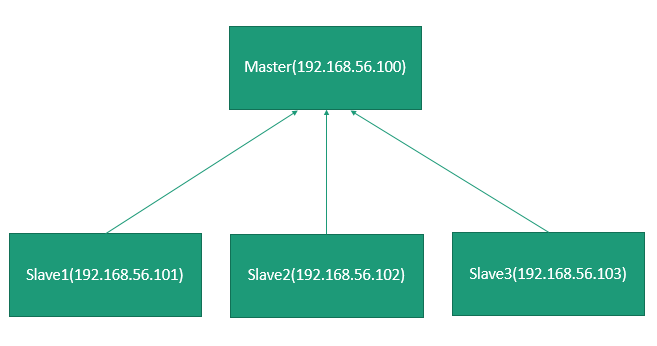
物理架构:假设机房有四台机器搭建一个集群环境,Master(ip:192.168.56.100)、Slave1(ip:192.168.56.101)、Slave2(ip:192.168.56.102)、Slave3(ip:192.168.56.103)。在这里简要介绍一下,至于具体内容,我将在Hadoop的Hdfs文章详细介绍。
分布式:将不同地点,不同功能的,用于不同数据的多态计算机通过通信网络连接其他,统一控制,协调完成大规模信息处理的计算机系统。简单说,一块硬盘可以分成两部分:文件索引和文件数据,那么文件索引部署在单独一台服务器上我们称为Master根节点(NameNode),文件数据部署在Master结点管理的孩子结点被称为Slave结点(DataNode)。
利用VirtulBox安装Linux
参考:http://www.cnblogs.com/qiuyong/p/6815903.html
配置集群在同一虚拟局域网下通信
说明:通过上述操作,已经搭建好master(192.168.56.100)这台机器,开始配置虚拟网络环境在同一虚拟机下。
- vim /etc/sysconfig/network
- NETWORKING=yes GATEWAY=192.168.56.1(说明:配置意思是,连上VirtualBox这块网卡)
- vim /etc/sysconfig/network-sripts/ifcfg-enp0s3
- TYPE=Ethernet IPADDR=192.168.56.100 NETMASK=255.255.255.0(说明:配置意思是,设置自己ip)
- 修改主机名:hostnamectl set-hostname master
- 重启网络:service network restart
- 查看ip:ifconfig
- 与windows能否ping通、若ping不同,关闭防火墙。master:ping 192.168.56.1 windows:ping 192.168.56.100
- systemctl stop firewalld -->system disable firewalld
利用Xshell、Xftp进行远程登录与文件传输
利用VirtualBox登录,上传文件会比较麻烦,采用Xshell远程登录。
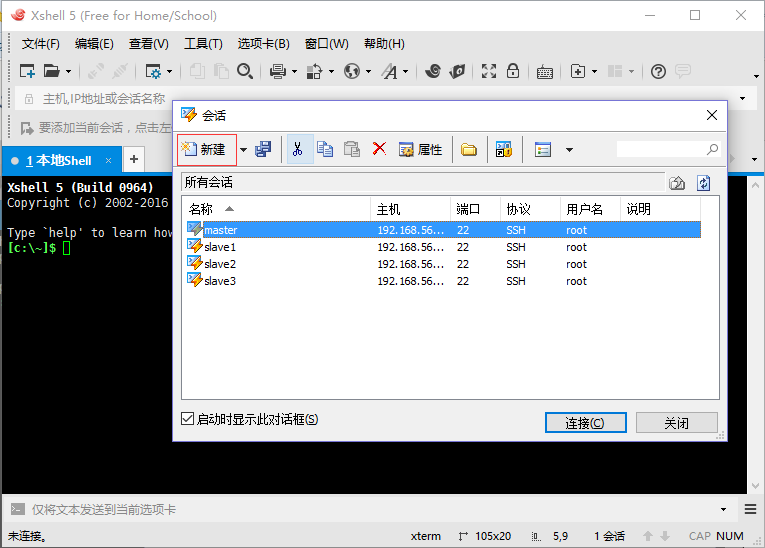
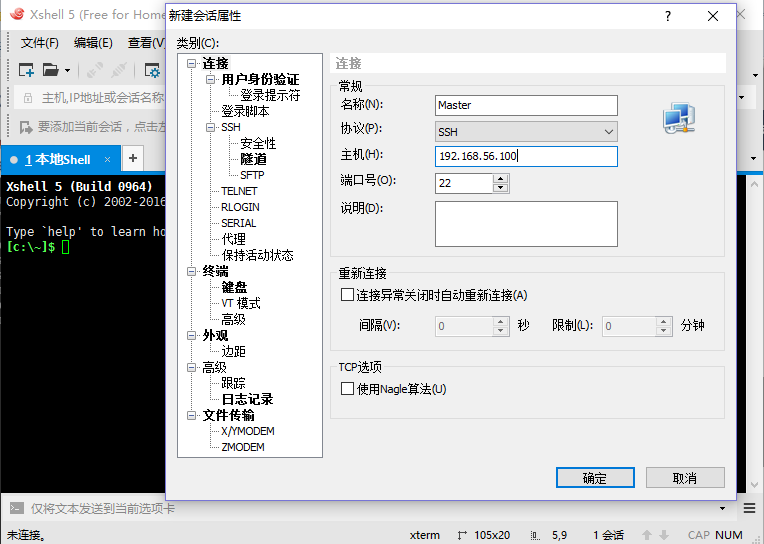
采用Xftp上传文件。
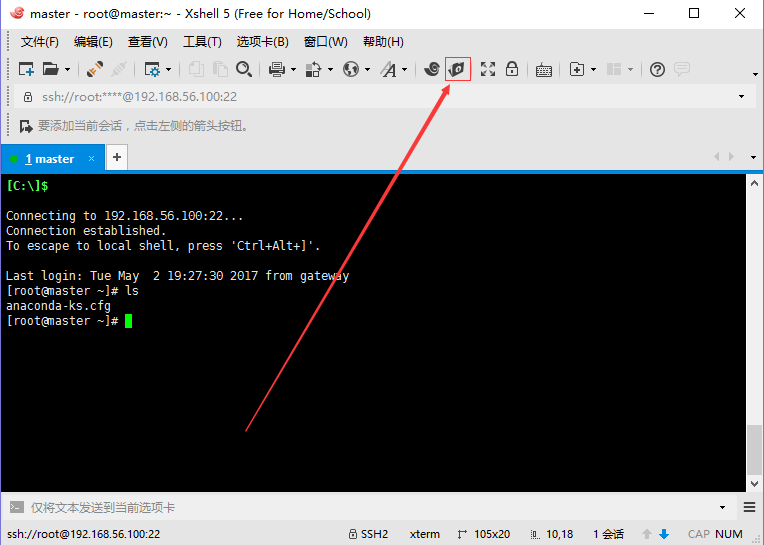
上传hadoop-2.7.3.tar.gz、jdk-8u91-linux-x64.rpm到/usr/local目录下。新手提示:在右边窗口选中/usr/local目录,左边双击压缩包就上传成功了。
配置hadoop环境
- 解压jdk-8u91-linux-x64.rpm:rpm -ivh /usr/local/jdk-8u91-linux-x64.rpm-->默认安装目录到/usr/java
- 确认jdk是否安装成功。 rpm -qa | grep jdk,java -version查看是否安装成功。
- 解压hadoop-2.7.3.tar.gz:tar -vhf /usr/local/hadoop-2.7.3.tar.gz。
- 修改目录名为hadoop:mv /usr/local/hadoop-2.7.3 hadoop
- 切换目录到hadoop配置文件目录:cd /usr/local/hadoop/etc/hadoop
- vim hadoop-env.sh
- 修改export JAVA_HOME 语句为 export JAVA_HOME=/usr/java/default
- 退出编辑页面:按esc键 输入:wq
- vim /etc/profile
- 在文件最后追加 export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin
- source /etc/profile
发散思考-更进一步
问题1:现在只是配置了一台master?那slave1、slave2、slave3也这样一台一台配置吗?
答:潜意识里面,肯定有解决办法避免。当然,VirtualBox也提供了,复制机器的功能。选中master,右键复制。这样的话,就一台跟master一模一样的机器就搞定了。我们只需要修改网络的相关配置即可。注意:搭建集群环境需要自己复制三台。
问题2:如何查看这些linux机器是否在同一个环境下?
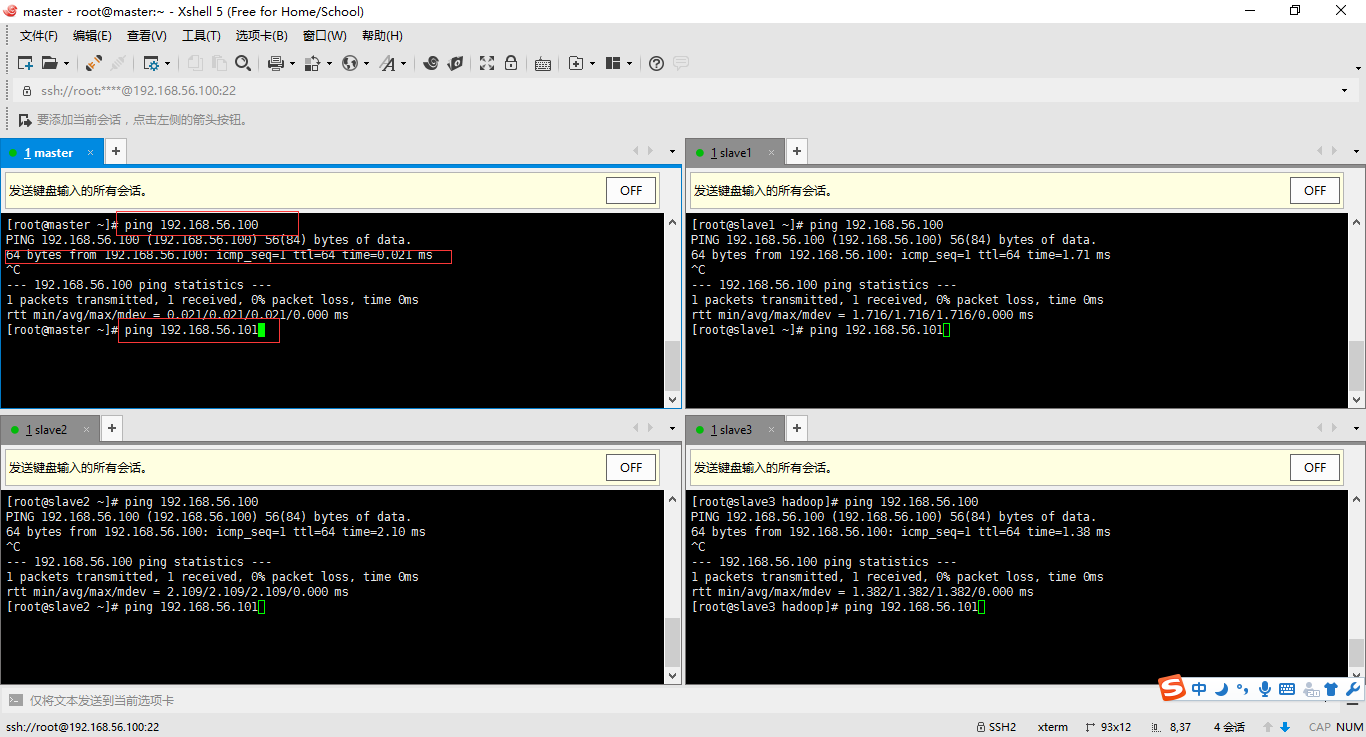
答:我重新捋一遍内容。启动四台linux机器(可以右键选择无界面启动)-->利用xshell远程登录-->选择工具(发送键到所用界面)。依次输入ping 192.168.56.100、192.168.56.101、192.168.56.102、192.168.56.103。
配置与启动hadoop
1、为四台机器配置域名。vim /etc/hosts
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3
2、切换到hadoop配置文件目录 /usr/local/hadoop/etc/hadoop vim core-site.xml
3、修改四台linux机器的core-site.xml,指名四台机器谁是master(NameNode)。
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
4、在master结点机器指名它的子节点有哪些:vim /usr/local/hadoop/etc/hadoop/slaves(其实就是指名子节点的ip)
slave1
slave2
slave3
5、初始化一下master配置:hdfs namenode -format
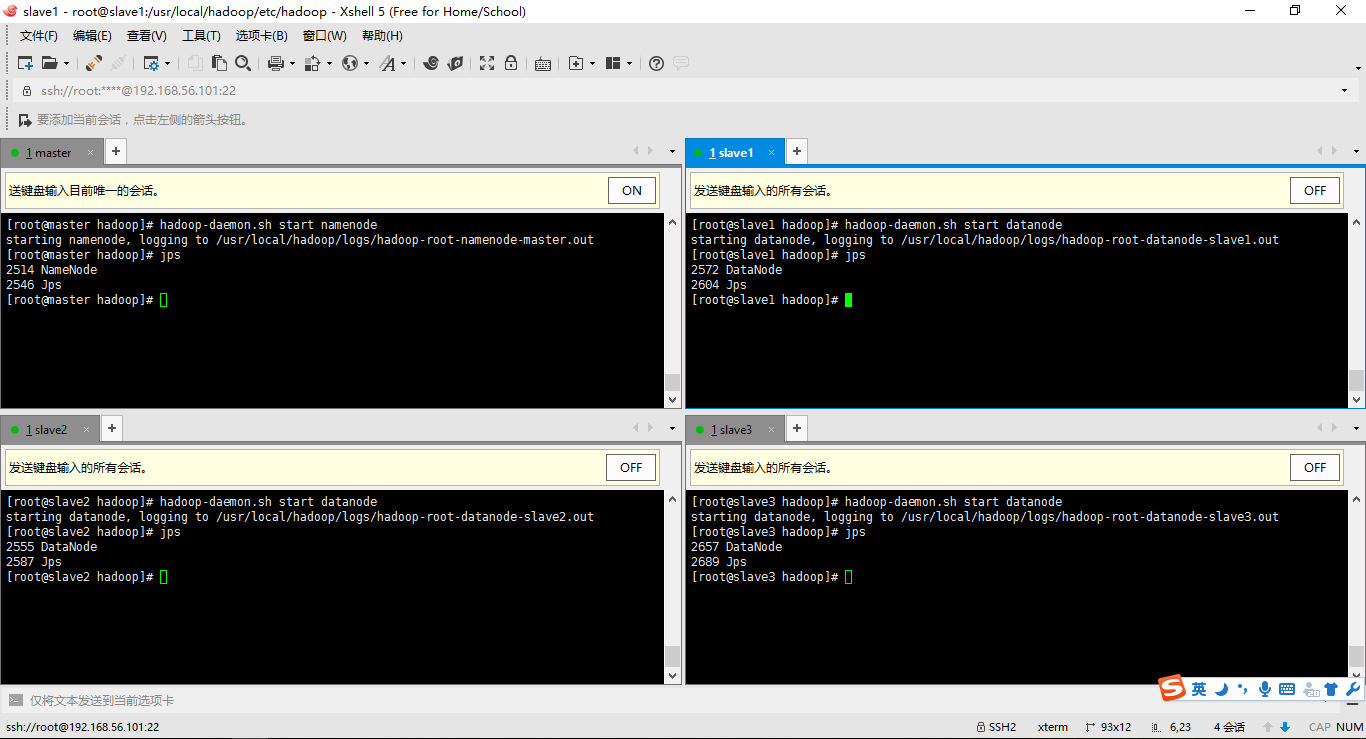
6、启动hadoop集群并且用jps查看结点的启动情况
启动master:hadoop-daemon.sh start namenode
启动slave:hadoop-daemon.sh start datanode
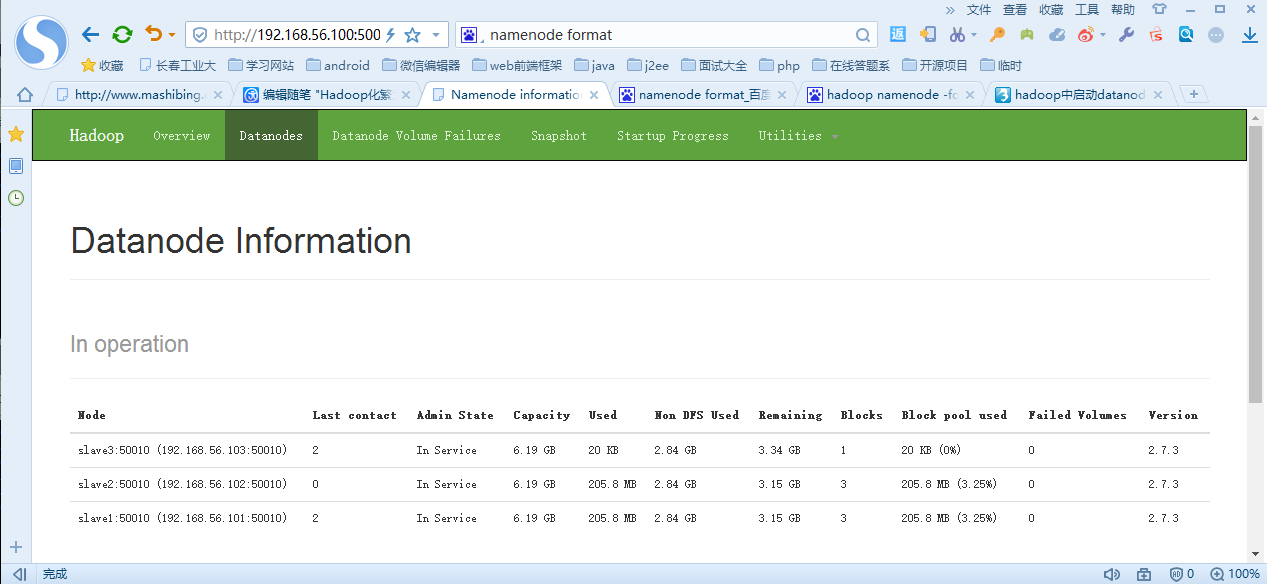
7、查看集群启动情况:hdfs dfsadmin -report或者利用网页http://192.168.56.100:50070/
版权声明
作者:邱勇Aaron
出处:http://www.cnblogs.com/qiuyong/
您的支持是对博主深入思考总结的最大鼓励。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,尊重作者的劳动成果。
Hadoop化繁为简(一)-从安装Linux到搭建集群环境的更多相关文章
- Hadoop化繁为简-从安装Linux到搭建集群环境
简介与环境准备 hadoop的核心是分布式文件系统HDFS以及批处理计算MapReduce.近年,随着大数据.云计算.物联网的兴起,也极大的吸引了我的兴趣,看了网上很多文章,感觉还是云里雾里,很多不必 ...
- linux下安装 zookeeper-3.4.9并搭建集群环境
本文主要记录作者在实践过程中实现在centos7环境下安装zookeeper并搭建集群的详细步骤,关于zookeeper本文将不做详细介绍,安装步骤详情如下: 前提准备:3台linux服务器(因为zo ...
- 使用Nginx在windows和linux上搭建集群
Nginx Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器 特点:反向代理 负载均衡 动静分离… 反向代理(Reverse Pro ...
- 【Nutch2.3基础教程】集成Nutch/Hadoop/Hbase/Solr构建搜索引擎:安装及运行【集群环境】
1.下载相关软件,并解压 版本号如下: (1)apache-nutch-2.3 (2) hadoop-1.2.1 (3)hbase-0.92.1 (4)solr-4.9.0 并解压至/opt/jedi ...
- 【redis】 linux 下redis 集群环境搭建
Redis集群 (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下) 127.0.0.1:63791 ...
- Nginx --Windows下和Linux下搭建集群小记
nginx: Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器 特点: 反向代理 负载均衡 动静分离... 反向代理 : 先来了解正向代理:需要我们用户 ...
- 基于redis 3.x搭建集群环境
由于我团队开发的在线坐席系统,即将面对线上每周3000W的下行投放客户,产品的咨询量可能会很大,基于前期,200W的投放时,前10分钟,大概800问题量,平均一个客户大概8个问题,也就是说每分钟10个 ...
- druid 搭建集群环境
下载druid 下载地址 http://static.druid.io/artifacts/releases/druid-services-0.6.145-bin.tar.gz 解压 tar -zxv ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
随机推荐
- 菜鸟学习Spring Web MVC之一
---恢复内容开始--- 当当当!!沉寂两日,学习Spring Web MVC去了.吐槽:近日跟同行探讨了下,前端攻城师,左肩担着设计师绘图,右肩担着JAVA代码?!我虽设计过UI,但这只算是PS技巧 ...
- js基础知识:闭包,事件处理,原型
闭包:其实就是js代码在执行的时候会创建变量对象的一个作用域链,标识符解析的时候会沿着作用域链一级一级的网上搜索,最后到达全局变量停止.所以某个函数可以访问外层的局部变量和全局变量,但是访问不了里层的 ...
- Anaconda+django写出第一个web app(十一)
今天我们来学习给页面添加一个Sidebar,根据Sidebar跳转到相应的tutorial. 打开views.py,编辑single_slug函数: def single_slug(request, ...
- flask_sqlalchemy的使用
第一配置文件 # coding:utf-8 DIALECT = 'mysql' DRIVER = 'pymysql' USERNAME = 'root' PASSWORD = ' HOST = '12 ...
- 数链剖分(Aragorn's Story )
题目链接:https://vjudge.net/contest/279350#problem/A 题目大意:n个点,m条边,然后q次询问,因为在树上,两个点能确定一条直线,我们可以对这条直线上的所有值 ...
- Redis的五大数据类型
1.String(字符串) String是Redis最基本的类型,一个Key对应一个Value. String类型是二进制安全的,意思是Redis的String可以包含任何数据,比如jpg图片或者序列 ...
- 【算法】Huffman编码(数据结构+算法)
1.描述 Huffman编码,将字符串利用C++编码输出该字符串的Huffman编码. Huffman树是一种特殊结构的二叉树,由Huffman树设计的二进制前缀编码,也称为Huffman编码在通信领 ...
- 【Python】CVE-2017-10271批量自查POC(Weblogic RCE)
1.说明 看到大家对weblogic漏洞这么热衷,于是也看看这个漏洞的测试方式. 找了几个安全研究员的博客分析,经过几天的摸索大体清楚漏洞由XMLDecoder的反序列化产生. 漏洞最早4月份被发现, ...
- python psutil监控系统资源【转】
通过 运用 Python 第三方 系统 基础 模块, 可以 轻松 获取 服务 关键 运营 指标 数据,包括 Linux 基本 性能. 块 设备. 网卡 接口. 系统 信息. 网络 地址 库 等 信息. ...
- day25作业
1.阻塞 2.就绪 3.阻塞 4.Runnable 5.join() 6.synchronized 7.notify()和notifyAll() 8.Object 1.A 2.D ...