[过程记录]Centos7 下 Hadoop分布式集群搭建
过程如下:
配置hosts
vim /etc/hosts
格式:
ip hostname
ip hostname
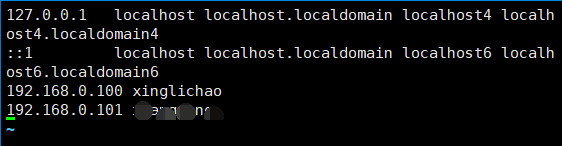
设置免密登陆
首先:每台主机使用ssh命令连接其余主机
ssh 用户名@主机名
提示是否连接:输入yes
提示输入密码:输入被请求连接主机的密码
成功过后
就会在本机的~目录下生成 .ssh文件夹
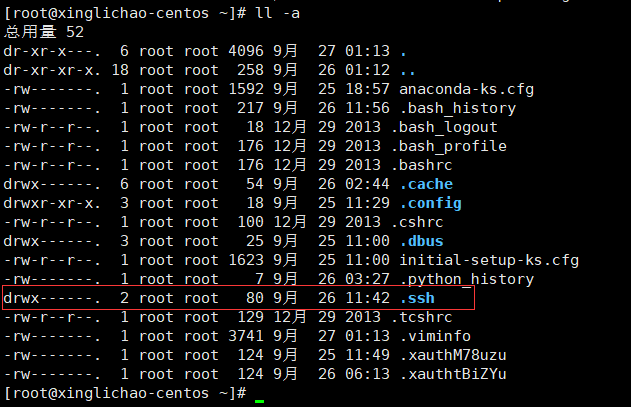
然后在master的主机上进入 ~/.ssh 目录
执行:
ssh-keygen -t rsa
回车回车再回车
得到 id_rsa id_rsa.pub 两个文件
复制一份 id_rsa.pub
cp id_rsa.pub authorized_keys
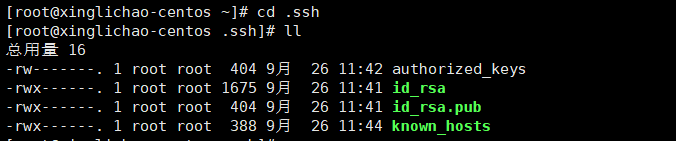
修改权限
修改.ssh权限
chmod -R 700 .ssh
修改quthorized_keys权限
chmod 600 authorized_keys
尝试ssh连接本机
ssh root@xinglichao

成功免密登陆
然后将 authorized_keys 分发到其他主机
scp ~/.ssh/authorized_keys root@****:~/.ssh
同样尝试ssh连接其余主机,全部可以免密登陆

下载好hadoop并解压到指定文件夹下

master以及其余主机上配置 /etc/profile
首先找到java的安装路径
[root@xinglichao-centos ~]# which java
/usr/bin/java
[root@xinglichao-centos ~]# ls -lrt /usr/bin/java
lrwxrwxrwx. 1 root root 22 9月 25 18:42 /usr/bin/java -> /etc/alternatives/java
[root@xinglichao-centos ~]# ls -lrt /etc/alternatives/java
lrwxrwxrwx. 1 root root 71 9月 25 18:42 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java

然后编辑profile
vim /etc/profile
添加JAVA_HOME以及HADOOP_HOME

source一下使配置文件生效
source /etc/profile
master上修改hadoop的配置文件:hadoop-env.sh
vim /usr/apache/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
增加内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
export HADOOP_HOME=/usr/apache/hadoop-2.7.5

测试hadoop
hadoop
master上修改hadoop中的slaves文件,指定为另外主机名(此处不贴截图了)
vim /etc/hadoop/hadoop-2.7.5/etc/hadoop/slaves
master主机创建name节点文件夹,slaves节点创建data文件夹
master:
mkdir -p hadoop/hadoop-2.7.5/node/dfs/name
slaves:
mkdir -p hadoop/hadoop-2.7.5/node/dfs/data
master中修改与hadoop-env.sh同文件夹下的core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://xinglichao:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.5/node</value>
</property>
</configuration>
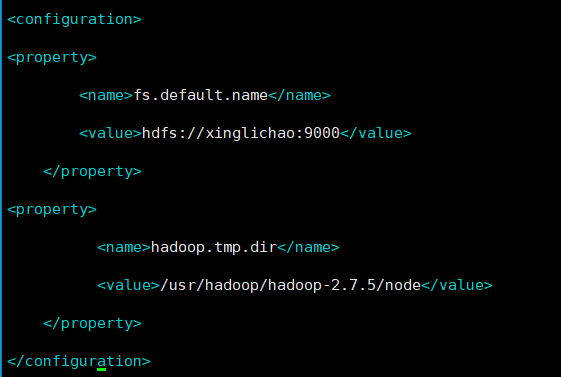
master中修改与hadoop-env.sh同文件夹下的修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hadoop-2.7.5/node/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hadoop-2.7.5/node/dfs/data</value>
</property>
</configuration>
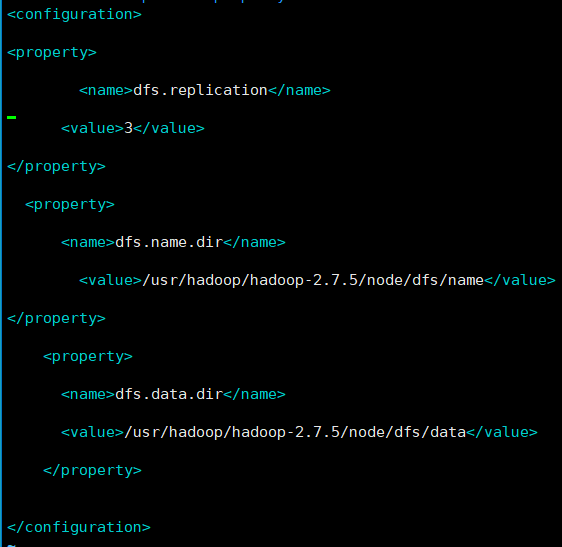
复制mapred-site.xml.template一份为mapred-site.xml,并修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
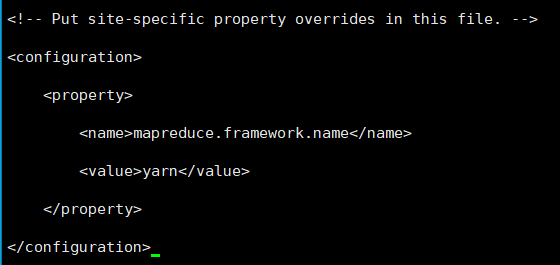
master中修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xinglichao</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
分发hadoop到其他slaves主机
scp -r /etc/hadoop/hadoop-2.7.5 root@****:/etc/hadoop/
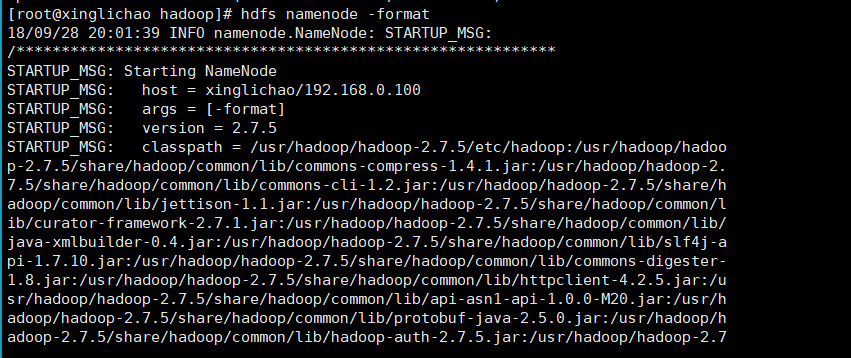
在master上格式化文件系统
hdfs namenode -format
此时出现问题:找不到java
/usr/hadoop/hadoop-2.7.5/bin/hdfs:行304: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/bin/java: 没有那个文件或目录
再查看下java的安装路径
发现:原来是在上一路径下的jre文件夹下
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java
修改hadoop中hadoop-env.sh
在JAVA_HOME后添加 /jre (注:此处的路径与上面的不同,理由在下面)

另外:
当我执行 jps命令查看节点运行状态时发现jps不是内部命令,于是更新了java
yum install java-1.8.0-openjdk-devel.x86_64
上图的路径是已经配置了新版本的java路径后的文件
再次格式化文件系统:hdfs namenode -formate
jps一下,至此算是成功了

后续的使用就是创建工程文件夹,上传文件到HDFS,写MapReduce,执行代码(参考:hadoop单机伪分布式与真分布式系统下运行MR代码)
本节完......
[过程记录]Centos7 下 Hadoop分布式集群搭建的更多相关文章
- Centos 7下Hadoop分布式集群搭建
一.关闭防火墙(直接用root用户) #关闭防火墙 sudo systemctl stop firewalld.service #关闭开机启动 sudo systemctl disable firew ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- Hadoop框架:单服务下伪分布式集群搭建
本文源码:GitHub·点这里 || GitEE·点这里 一.基础环境 1.环境版本 环境:centos7 hadoop版本:2.7.2 jdk版本:1.8 2.Hadoop目录结构 bin目录:存放 ...
- hadoop分布式集群搭建(2.9.1)
1.环境 操作系统:ubuntu16 jdk:1.8 hadoop:2.9.1 机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.1 ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- kettle在centos7下部署分布式集群
首先安装三台centos7 ,分别配置好静态ip ssh免密码登录 关闭防火墙 具体步骤这里不多说了 关于centos7配置静态ip大家可以参考:https://www.cnblogs. ...
- centos7下Zookeeper+sheepdog集群搭建
zookeeper 安装命令 yum install zookeeper -y (版本:zookeeper.x86_64 3.4.6-1) yum install zo ...
随机推荐
- BZOJ1185 [HNOI2007]最小矩形覆盖 【旋转卡壳】
题目链接 BZOJ1185 题解 最小矩形一定有一条边在凸包上,枚举这条边,然后旋转卡壳维护另外三个端点即可 计算几何细节极多 维护另外三个端点尽量不在这条边上,意味着左端点尽量靠后,右端点尽量靠前, ...
- 【CF706D】Vasiliy's Multiset Trie+贪心
题目大意:需要维护一种数据结构,支持以下三种操作:插入一个数,删除一个数,查询该数据结构中的数异或给定数的最大值. 题解:如果没有删除操作就是一个标准的 Trie 上贪心求最大异或和问题.现在需要支持 ...
- 【CF771A】Bear and Friendship Condition
题目大意:给定一张无向图,要求如果 A 与 B 之间有边,B 与 C 之间有边,那么 A 与 C 之间也需要有边.问这张图是否满足要求. 题解:根据以上性质,即:A 与 B 有关系,B 与 C 有关系 ...
- 【洛谷P1214】等差数列
题目大意:列出从一个给定上界的双平方数集合中选出若干个数,组成长度为 N 的等差数列的首项和公差. 题解:首先,因为是在双平方数集合上的等差数列,而且根据题目范围可知,上界不超过 2e5,可以先打表, ...
- MathExam V2.0
# 隔壁村小学的小朋友都羡慕哭了2.0版 一.预估与实际 PSP2.1 Personal Software Process Stages 预估耗时(分钟) 实际耗时(分钟) Planning 计划 1 ...
- plsql批量导入sql文件
背景:有时候在两个数据库之间导入导出数据,不可避免的需要进行sql文件的批量导入,一个个导入效率太低,所以可以考虑批量导入的办法进行导入. 操作步骤 1.假设有三个sql脚本,分别为aa.sql,bb ...
- 百度钱包、百付宝、baifubao接入支付的常见问题
[5004:参数非法,请检查输入参数后重试.]:检查是否缺少了其它必要的参数,我当时是缺少了order_no [5804,抱歉,订单创建失败,请联系客服处理]:即验证签名失败,这个只能参考文档进行处理 ...
- SQL语句(六)成批导入导出数据
(六) 成批导入导出数据 假设已经存在teaching数据库, 存在一张Student表,如图: 右键teaching->任务->导入数据 下一步->数据源(Microsoft Ex ...
- Spring Mvc 一个接口多个继承; (八)
在 spring 注解实现里,一个接口一般是不能多继承的! 除非在 bean 配置文件里有 针对这个 实现类的配置: <beans:bean id="icService" c ...
- CF989C A Mist of Florescence (构造)
CF989C A Mist of Florescence solution: 作为一道构造题,这题确实十分符合构造的一些通性----(我们需要找到一些规律,然后无脑循环).个人认为这题规律很巧妙也很典 ...