hadoop分布式集群搭建(2.9.1)
1、环境
操作系统:ubuntu16
jdk:1.8
hadoop:2.9.1
机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.168.199.90
2、搭建步骤
2.1 修改主机名hostname,三台机器分别执行如下命令,依次填入master,node1,node2
sudo vim /etc/hostname

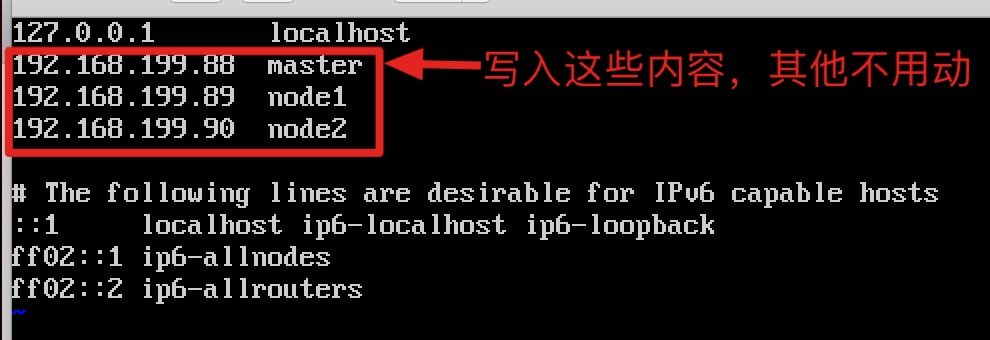
2.2 修改hosts文件,三台机器依次执行
sudo vim /etc/hosts
2.3 修改环境变量,三台依次执行
vim /etc/profile,然后source /etc/profile使之生效

JAVA_HOME是java的安装路径,如果不知道自己的java安装路径,请参考如下操作:

which java定位到的是java程序的执行路径,而不是安装路径,经过两次-lrt最后的输出才是安装路径
2.3 配置master对node1和node2的免密登陆
效果就是在master上输入ssh node1即可登陆node1,否则开启集群服务时,master与node无法连接,会报出connection refused
2.3.1 配置前,先确保安装了openssh-server,默认是不安装的
输入dpkg --list | grep ssh,如果没有openssh-server,执行以下命令安装:
sudo apt-get install openssh-server
2.3.2 每台机器执行ssh-keygen -t rsa,然后回车
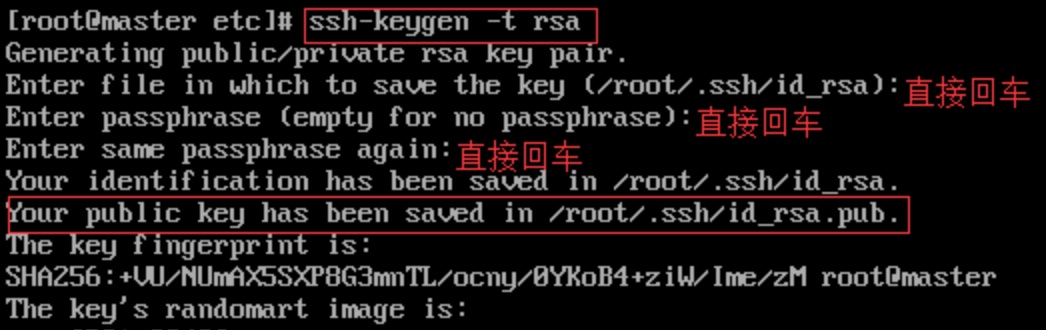
生成的公钥私钥都保存在~/.ssh下
2.3.3、在master上将公钥放入authorized_keys,命令如下:
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
2.3.4、将master上的authorized_keys放到其它机器上
scp ~/.ssh/authorized_keys root@node1:~/.ssh/
scp ~/.ssh/authorized_keys root@node2:~/.ssh
2.3.5、测试是否成功
2.4 下载hadoop及修改配置文件在master上执行即可,修改完再复制到其他机器上
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-2.9.1.tar.gz (我下载时这里的稳定版是2.9.1,如果更新了,下载相应的tar.gz包即可)
解压:tar zxf hadoop-2.9.1.tar.gz
2.5 创建HDFS存储目录
进入解压后的文件夹: cd hadoop2.9.1
mkdir hdfs
cd hdfs
mkdir name data tmp
./hdfs/name --存储namenode文件
./hdfs/data --存储数据
./hdfs/tmp --存储临时文件
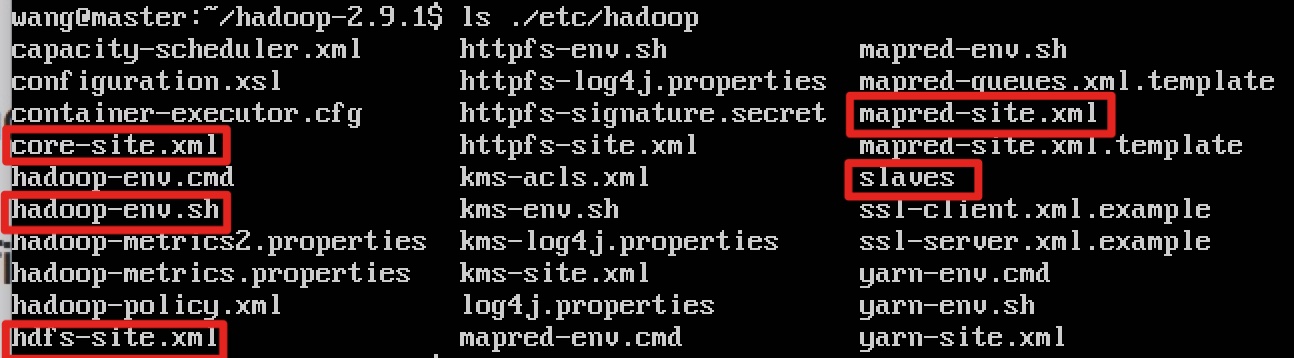
2.6 修改xml配置文件
需要修改的xml文件在hadoop2.9.1/etc/hadoop/下
主要有5个文件要修改:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
2.6.1、vim hadoop-env.sh,填写的是java的安装路径

2.6.2、vim core-site.xml,configuration标签中插入如下内容

2.6.3、vim hdfs-site.xml
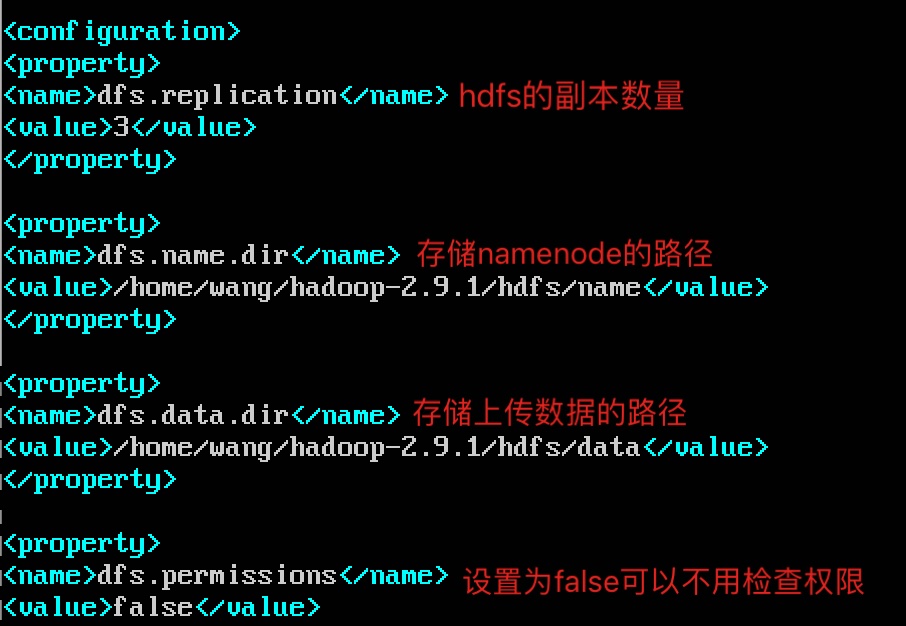
2.6.4、vim mapred-site.xml

2.6.5、vim yarn-site.xml

2.6.6、vim slaves,将里面的localhost删掉,写入从节点主机名
2.7 将hadoop文件夹远程拷贝到node节点上
scp -r hadoop-2.9.1 wang@node1:/home/wang/
scp -r hadoop-2.9.1 wang@node2:/home/wang/
2.8 启动hadoop
2.8.1 启动之前要先格式化,格式化命令:hadoop namenode -format
因为master是namenode,node1和node2都是datanode,所以只在master上执行
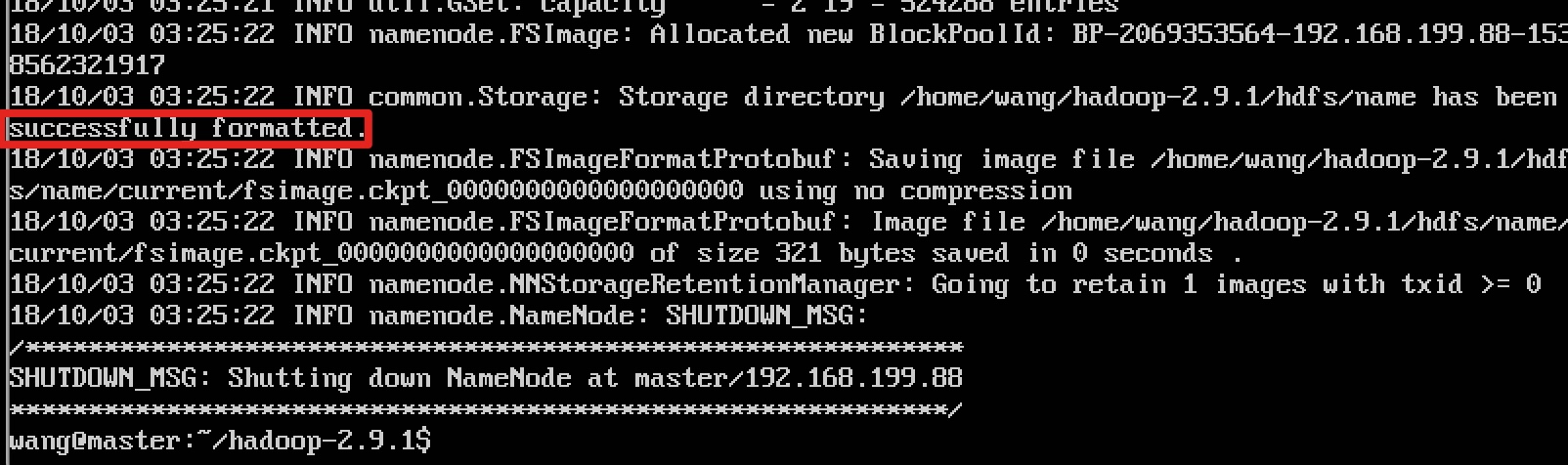
如果出现successfully formatted,即表示格式化成功,会看到name下多出current文件夹

2.8.2 格式化成功后,在master上执行命令:start-all.sh,启动后可用jps命令查看开启的进程,master上有四个进程,node上是三个

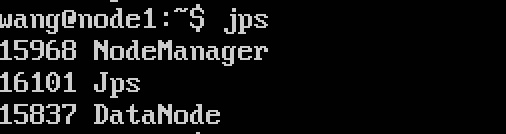
如果不是,请从头到尾再检查一下配置文件,看是否有拼错的地方
另外还可以在浏览器查看:192.168.199.88:50070
(masterIP,50070固定端口)
hadoop分布式集群搭建(2.9.1)的更多相关文章
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- [过程记录]Centos7 下 Hadoop分布式集群搭建
过程如下: 配置hosts vim /etc/hosts 格式: ip hostname ip hostname 设置免密登陆 首先:每台主机使用ssh命令连接其余主机 ssh 用户名@主机名 提示是 ...
- Centos 7下Hadoop分布式集群搭建
一.关闭防火墙(直接用root用户) #关闭防火墙 sudo systemctl stop firewalld.service #关闭开机启动 sudo systemctl disable firew ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
随机推荐
- Mac 下配置Lua环境
1.下载LUA源码包 curl -R -O http://www.lua.org/ftp/lua-5.3.1.tar.gz 2.解压并进入目录 tar -xvf lua-.tar.gz cd lua- ...
- method&interface
method Go中虽没有class,但依旧有method 通过显示说明receiver来实现与某个类型组合 只能为同一个包的类型定义方法 Receiver可以是类型的值或指针 不存在方法重载 可以使 ...
- css后代选择器
后代选择器: <p><em>CSS</em>层叠样式</p> 使用后代选择器设置,之间用空格隔开: p em{font-size:40px;} 例子: ...
- js 关于定时器的知识点。
Js的同步和异步 同步:代码从上到下执行. 异步:每个模块执行自己的,同时执行. js本身就是同步的,但是需要记住四个地方是异步. Js的异步 1.定时器 2.ajax 3事件的绑定 4. ...
- (26)基于cookie的登陆认证(写入cookie、删除cookie、登陆后所有域下的网页都可访问、登陆成功跳转至用户开始访问的页面、使用装饰器完成所有页面的登陆认证)
获取cookie request.COOKIES['key'] request.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age ...
- react-router 父子路由同时要接收 params 的写法
<Route path="/profile/:companyId/:companyName" component={Profile} onEnter={(nextState, ...
- range的新发现
正向打印的时候 for i in range(2): print(i) 打印的结果 0 1 反向的时候 for i in range(2,-1,-1): print(i) 2 1 0 for i in ...
- Intellij中部署Tomcat(详细版本-介绍了部署完之后的详细路径)
https://blog.csdn.net/HughGilbert/article/details/56424137 要点如下: 1. CATALINA_HOME即Tomcat的安装目录 2. CAT ...
- Innodb中MySQL如何快速删除2T的大表
转自:http://database.51cto.com/art/201808/582324.htm OK,这里就说了.假设,你有一个表erp,如果你直接进行下面的命令: drop table erp ...
- 解决Kubelet Pod启动CreatePodSandbox或RunPodSandbox异常方法
新装Kubernetes,创建一个新Pod,启动Pod遇到CreatePodSandbox或RunPodSandbox异常.查看日志 # journalctl --since :: -u kubele ...