2、Pyspider使用入门
1、接上一篇,在webui页面,点击右侧【Create】按钮,创建爬虫任务

2、输入【Project Name】,【Start Urls】为爬取的起始地址,可以先不输入,点击【Create】进入:

3、进入爬取操作的页面
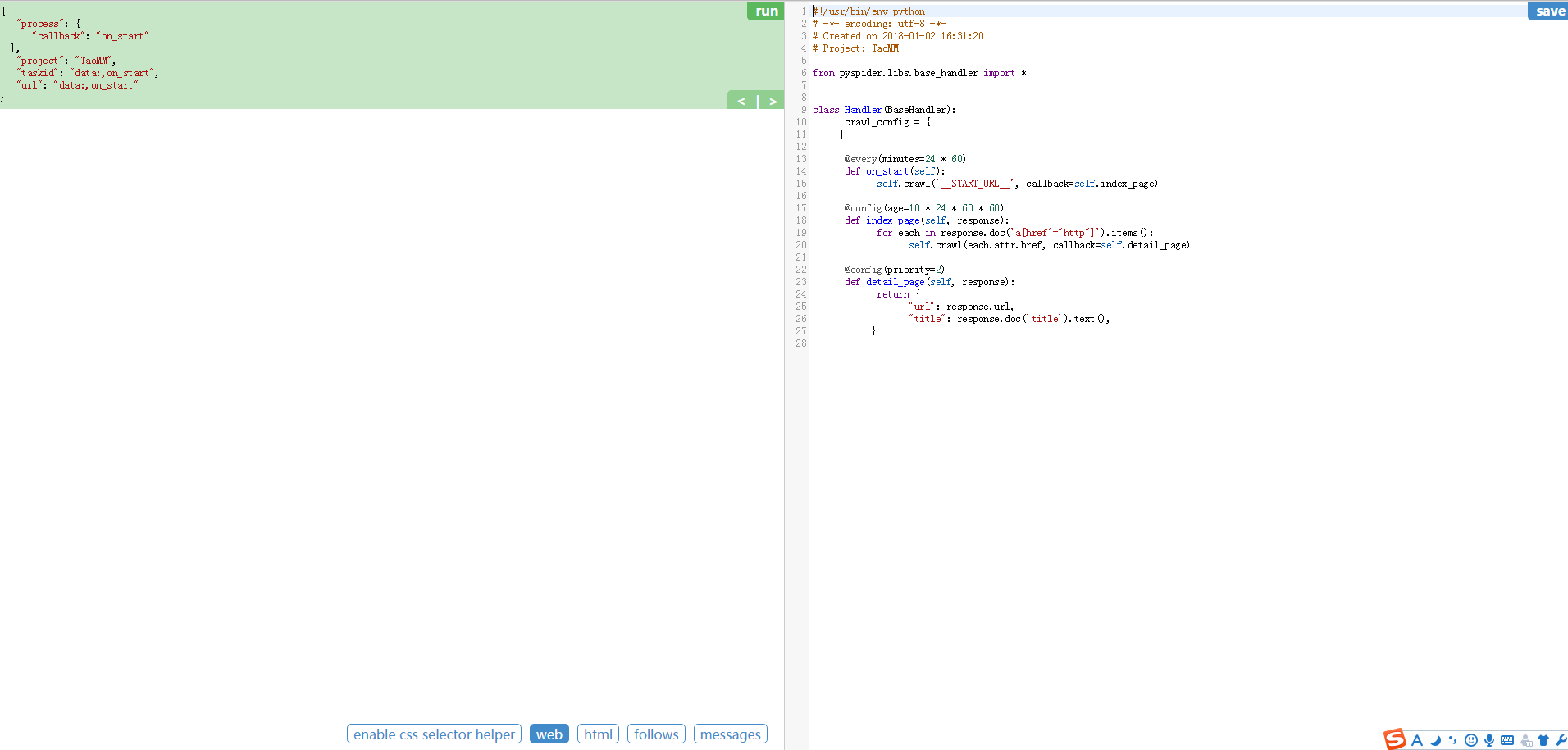
整个页面分为两栏,左边是爬取页面预览区域,右边是代码编写区域。下面对区块进行说明:
左侧绿色区域:这个请求对应的 JSON 变量,在 PySpider 中,其实每个请求都有与之对应的 JSON 变量,包括回调函数,方法名,请求链接,请求数据等等。
绿色区域右上角Run:点击右上角的 run 按钮,就会执行这个请求,可以在左边的白色区域出现请求的结果。
左侧 enable css selector helper: 抓取页面之后,点击此按钮,可以方便地获取页面中某个元素的 CSS 选择器。
左侧 web: 即抓取的页面的实时预览图。
左侧 html: 抓取页面的 HTML 代码。
左侧 follows: 如果当前抓取方法中又新建了爬取请求,那么接下来的请求就会出现在 follows 里。
左侧 messages: 爬取过程中输出的一些信息。
右侧代码区域: 你可以在右侧区域书写代码,并点击右上角的 Save 按钮保存。
右侧 WebDAV Mode: 打开调试模式,左侧最大化,便于观察调试。
4、代码编辑区
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2015-10-08 12:45:44
# Project: test from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} @every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page) @config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
代码简单分析:
def on_start(self) 方法是入口代码。当在web控制台点击run按钮时会执行此方法。
self.crawl(url, callback=self.index_page)这个方法是调用API生成一个新的爬取任务,这个任务被添加到待抓取队列。
def index_page(self, response) 这个方法获取一个Response对象。 response.doc是pyquery对象的一个扩展方法。pyquery是一个类似于jQuery的对象选择器。
def detail_page(self, response)返回一个结果集对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。你也可以重写on_result(self,result)方法来指定保存位置。
更多知识:
@every(minutes=24*60, seconds=0) 这个设置是告诉scheduler(调度器)on_start方法每天执行一次。
@config(age=10 * 24 * 60 * 60) 这个设置告诉scheduler(调度器)这个request(请求)过期时间是10天,10天内再遇到这个请求直接忽略。这个参数也可以在self.crawl(url, age=10*24*60*60) 和 crawl_config中设置。
@config(priority=2) 这个是优先级设置。数字越大越先执行。
2、Pyspider使用入门的更多相关文章
- 爬虫入门【11】Pyspider框架入门—使用HTML和CSS选择器下载小说
开始之前 首先我们要安装好pyspider,可以参考上一篇文章. 从一个web页面抓取信息的过程包括: 1.找到页面上包含的URL信息,这个url包含我们想要的信息 2.通过HTTP来获取页面内容 3 ...
- 爬虫入门【10】Pyspider框架简介及安装说明
Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下: 1.可以在Python环境下写脚本 2.具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看. 3.支持多 ...
- Python爬虫入门教程 27-100 微医挂号网专家团队数据抓取pyspider
1. 微医挂号网专家团队数据----写在前面 今天尝试使用一个新的爬虫库进行数据的爬取,这个库叫做pyspider,国人开发的,当然支持一下. github地址: https://github.com ...
- Python爬虫入门教程 29-100 手机APP数据抓取 pyspider
1. 手机APP数据----写在前面 继续练习pyspider的使用,最近搜索了一些这个框架的一些使用技巧,发现文档竟然挺难理解的,不过使用起来暂时没有障碍,估摸着,要在写个5篇左右关于这个框架的教程 ...
- Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流 ...
- pyspider入门
1.http://www.pyspider.cn/jiaocheng/pyspider-webui-12.html 2.https://blog.csdn.net/weixin_37947156/ar ...
- Pyspider的基本使用 -- 入门
简介 一个国人编写的强大的网络爬虫系统并带有强大的WebUI 采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器 官方文档: ...
- 【Hawk】入门教程(1)——从URL开始
入门教程(1)--从URL开始 首先感谢辛苦的沙漠君 先把沙漠君的教程载过来:)可以先看一遍 Hawk-数据抓取工具:简明教程 Hawk 数据抓取工具 使用说明(二) 20分钟无编程抓取大众点评17万 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
随机推荐
- 【Tomcat】tomcat配置文件详解
Tomcat Server的结构图 结构框架,如下 属性表格 元素名 属性 解释 server(它代表整个容器,是Tomcat实例的顶层元素.由org.apache.catalina.Server接口 ...
- POJ1458(KB12-L LCS)
Common Subsequence Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 51319 Accepted: 21 ...
- BZOJ3165: [Heoi2013]Segment(李超线段树)
题意 题目链接 Sol 李超线段树板子题.具体原理就不讲了. 一开始自己yy着写差点写自闭都快把叉积搬出来了... 后来看了下litble的写法才发现原来可以写的这么清晰简洁Orz #include& ...
- w3school前端教程合集
有关前端开发的w3c教程合集. http://caibaojian.com/w3school/ 地图 ajax教程 Canvas教程 CSS教程 CSS3教程 CSS3选择器 CSS参考手册 DHTM ...
- kafka-hadoop-consumer
写了一个工具,从kafka传输数据到hdfs,采用的api,可以消费指定的kafka topic 或者为了简便可以消费所有的topic中各个partition的数据. 地址:https://githu ...
- android 所有焦点问题
一. 主动获取焦点 setFocusable(true); // 是设置能否获得焦点而已.. requestFocus(); //是让控件得到焦点 requestFocusI ...
- 用例设计之API用例覆盖准则
基本原则 本文主要讨论API测试的用例/场景覆盖,基本原则如下: 用户场景闭环(从哪来到哪去) 遍历所有的实现逻辑路径 需求点覆盖 覆盖维度 API协议(参数&业务场景) 中间件检查 异常场景 ...
- Ionic命令大全
start [options] <PATH> [template] ............. Starts a new Ionic project in the specified P ...
- 转:queue
数据结构C#版笔记--队列(Quene) 队列(Quene)的特征就是“先进先出”,队列把所有操作限制在"只能在线性结构的两端"进行,更具体一点:添加元素必须在线性表尾部进行, ...
- easyui中日期格式化
<body> <div id="list"></div> <script type="text/javascrip ...