Pyspider的基本使用 -- 入门
简介
- 一个国人编写的强大的网络爬虫系统并带有强大的WebUI
- 采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器
- 官方文档:http://docs.pyspider.org/en/latest/
安装
- pip install pyspider
- 安装失败的解决方法
启动服务
- 命令窗口输入pyspider
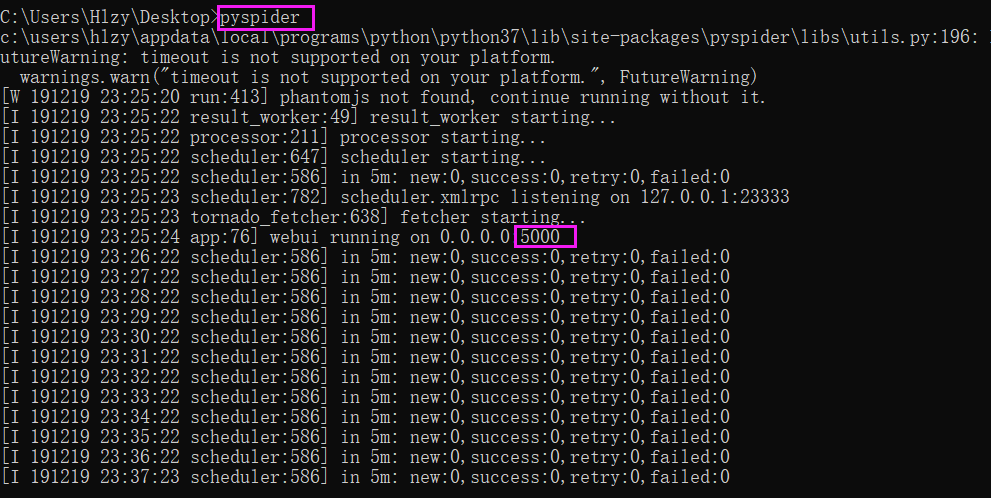
打开Web界面
- 浏览器输入localhost:5000

创建项目

删除项目
- 删除某个:设置 group 为 delete ,status 为 stop ,24小时之后自动删除

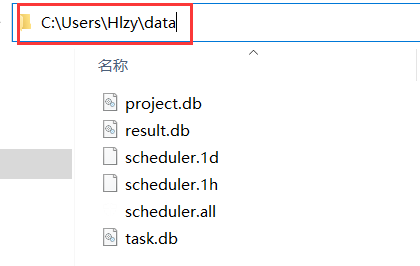
- 删除全部:在启动服务的路径下,找到它自己生成的data目录,直接删除目录里的所有文件
禁止证书验证

- 加上参数 validate_cert = False
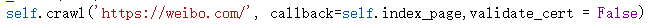
使用方法
- on_start(self)
- 入口方法,run的时候,默认会调用
- crawl()
- 生成一个新的爬取请求,类似于scrapy.Request,接受的参数是ur1和callback
- @every(minutes=2, seconds=30)
- 告诉scheduler两分30秒执行一次
- @config(age=10 * 24 * 60 * 60)
- 告诉调度器(单位:秒)、这个请求过期时间是10天、10天之内不会再次请求
- @config(priority=2)
- 优先级、数字越大越先执行
- age写在函数里面跟写在装饰器上的区别
- 写在函数里面的后执行,下图实际过期时间为5秒,若函数里没有age,则为装饰器里定义的20秒

- 写在函数里面的后执行,下图实际过期时间为5秒,若函数里没有age,则为装饰器里定义的20秒
执行任务
- 完成脚本编写,调试无误后,先save脚本,然后返回到控制台首页
- 直接点击项目状态status那栏,把状态由TODO改成DEBUG或RUNNING
- 最后点击项目最右边的Run按钮启动项目
对接phantomjs
- 将phantomjs.exe放在Python环境根目录下,或者将所在目录添加到系统的环境变量
- 添加成功,启动服务时,会显示如下信息
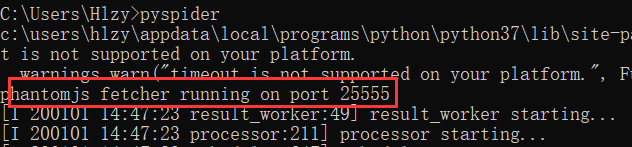
没使用js渲染
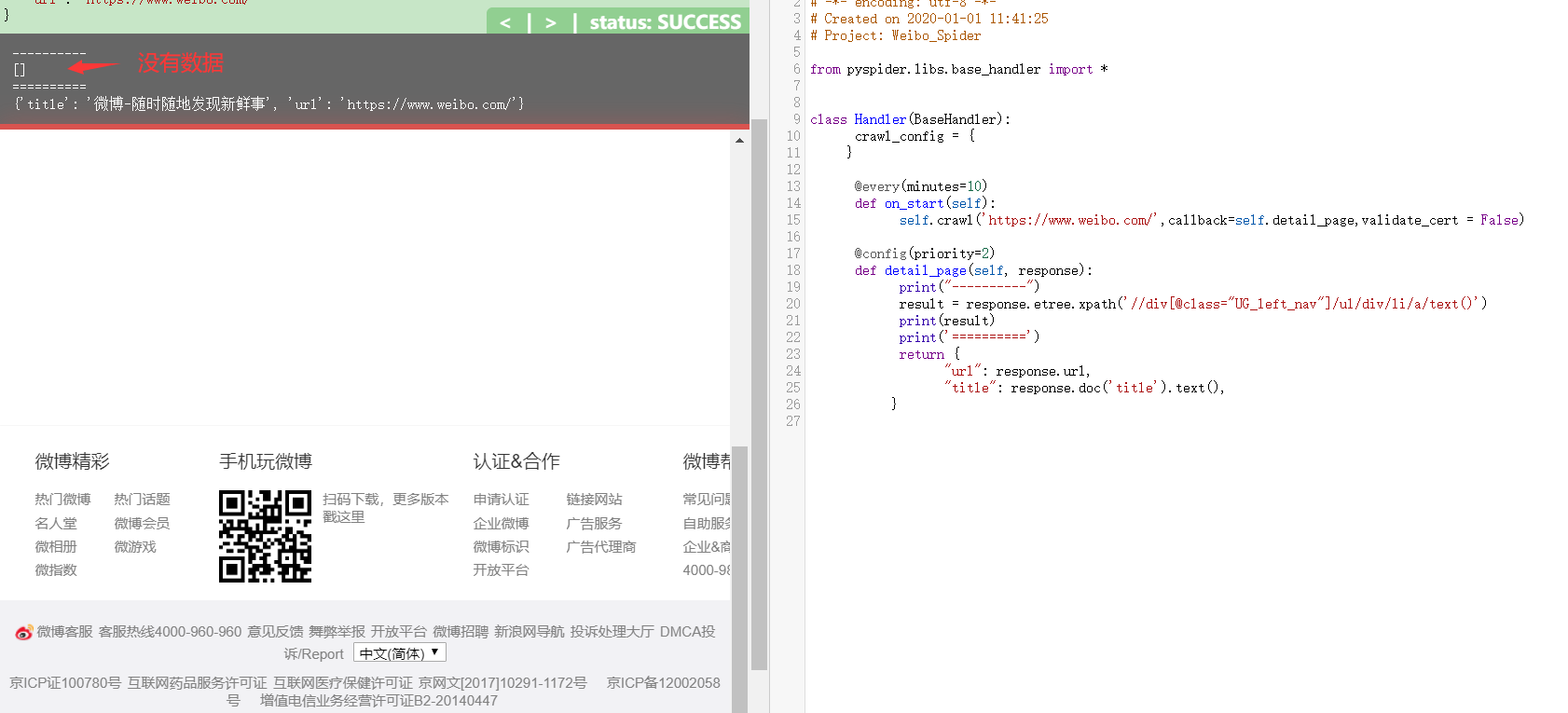
使用js渲染
- 添加参数 fetch_type = 'js'
其它
- rate/burst
- rate:一秒钟执行的请求个数
- burst:并发的数量
- 例如:2/5、每秒两个请求,并发数量为5,即每秒10个请求
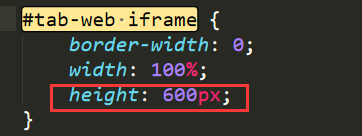
- 设置渲染的web页面的高度

- 在源代码里修改css样式即可(#tab-web iframe)
- css文件路径:python安装目录下 Lib\site-packages\pyspider\webui\static 里的 debug.min.css
Pyspider的基本使用 -- 入门的更多相关文章
- Python爬虫入门教程 27-100 微医挂号网专家团队数据抓取pyspider
1. 微医挂号网专家团队数据----写在前面 今天尝试使用一个新的爬虫库进行数据的爬取,这个库叫做pyspider,国人开发的,当然支持一下. github地址: https://github.com ...
- 爬虫入门【10】Pyspider框架简介及安装说明
Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下: 1.可以在Python环境下写脚本 2.具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看. 3.支持多 ...
- Python爬虫入门教程 29-100 手机APP数据抓取 pyspider
1. 手机APP数据----写在前面 继续练习pyspider的使用,最近搜索了一些这个框架的一些使用技巧,发现文档竟然挺难理解的,不过使用起来暂时没有障碍,估摸着,要在写个5篇左右关于这个框架的教程 ...
- Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流 ...
- pyspider入门
1.http://www.pyspider.cn/jiaocheng/pyspider-webui-12.html 2.https://blog.csdn.net/weixin_37947156/ar ...
- 2、Pyspider使用入门
1.接上一篇,在webui页面,点击右侧[Create]按钮,创建爬虫任务 2.输入[Project Name],[Start Urls]为爬取的起始地址,可以先不输入,点击[Create]进入: 3 ...
- 爬虫入门【11】Pyspider框架入门—使用HTML和CSS选择器下载小说
开始之前 首先我们要安装好pyspider,可以参考上一篇文章. 从一个web页面抓取信息的过程包括: 1.找到页面上包含的URL信息,这个url包含我们想要的信息 2.通过HTTP来获取页面内容 3 ...
- 【Hawk】入门教程(1)——从URL开始
入门教程(1)--从URL开始 首先感谢辛苦的沙漠君 先把沙漠君的教程载过来:)可以先看一遍 Hawk-数据抓取工具:简明教程 Hawk 数据抓取工具 使用说明(二) 20分钟无编程抓取大众点评17万 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
随机推荐
- 实现简单HttpServer案例
<html> <head> <title>第一个表单</title> </head> <body> <pre> me ...
- 利用graphviz软件和pycallgraph库自动生成Python代码函数调用关系图
参考博文:https://blog.csdn.net/qq_36408085/article/details/82952846 https://blog.csdn.net/fondax/article ...
- 加密设备NAT对IPSec的影响
加密设备NAT对IPSec VPN的影响:我们先配置好经典的IPSec VPN,然后在R3上做PAT看会对IPSec VPN产生什么影响(不会对有隧道的IPSec VPN技术产生影响). 现在默认配置 ...
- 【原】linux两台服务器之间免密登录方法
搭建集群机器192.168.0.100和192.168.0.200里,需要两台机器中间相互拷贝文件: 方式一:下载192.168.0.100机器文件到本地,再将本地文件拷贝到B机器 方式二:192.1 ...
- ypACM社团年终赛暨实验室选拔赛题解
记得补题,题目两小时半还是挺困难ak的,毕竟我验题也验了几天的时间,题目基本没有锅.题目基本属于简单题 我的三道题都是很基本的题目,希望大家补题 这些题解都是我写的,如果有疑问可以qq问我 所有的核心 ...
- 【JQuery 选择器】 案例
1.查找以id的某个字段开头的元素 setTimeout(function () { $("a[id^='menu_']").each(function () { $(this). ...
- AS布局篇
LinearLayout 线性布局 RelativeLayout 相对布局 FrameLayout 帧布局 AbsoluteLayout绝对布局 TableLayout 表格布局 GridLayout ...
- HTML、HTML5重难点
一.XHTML与HTML的区别 文档结构 XHTML DOCTYPE 是强制性的 <html>中的 XML namespace 属性是强制性的 <html>.<head& ...
- python中模块的制作
1.import 模块名 2.from 模块名 import 类名(或方法名或全局变量) 3.from 模块名 import * 导入模块名下的所有类名,方法,全局变量 4.from 模块名 im ...
- 算法-leetcode-65-Valid Number
算法-leetcode-65-Valid Number 上代码: # coding:utf-8 __author__ = "sn" """Valida ...