爬虫入门【11】Pyspider框架入门—使用HTML和CSS选择器下载小说
开始之前
首先我们要安装好pyspider,可以参考上一篇文章。
从一个web页面抓取信息的过程包括:
1、找到页面上包含的URL信息,这个url包含我们想要的信息
2、通过HTTP来获取页面内容
3、从HTML中提取出信息来
4、然后找到更多的URL,回到第2步继续执行~
选择一个开始的URL
我推荐一部小说给大家《恶魔法则》。
今天我们从网上将这部小说的内容按照章节下载下来。
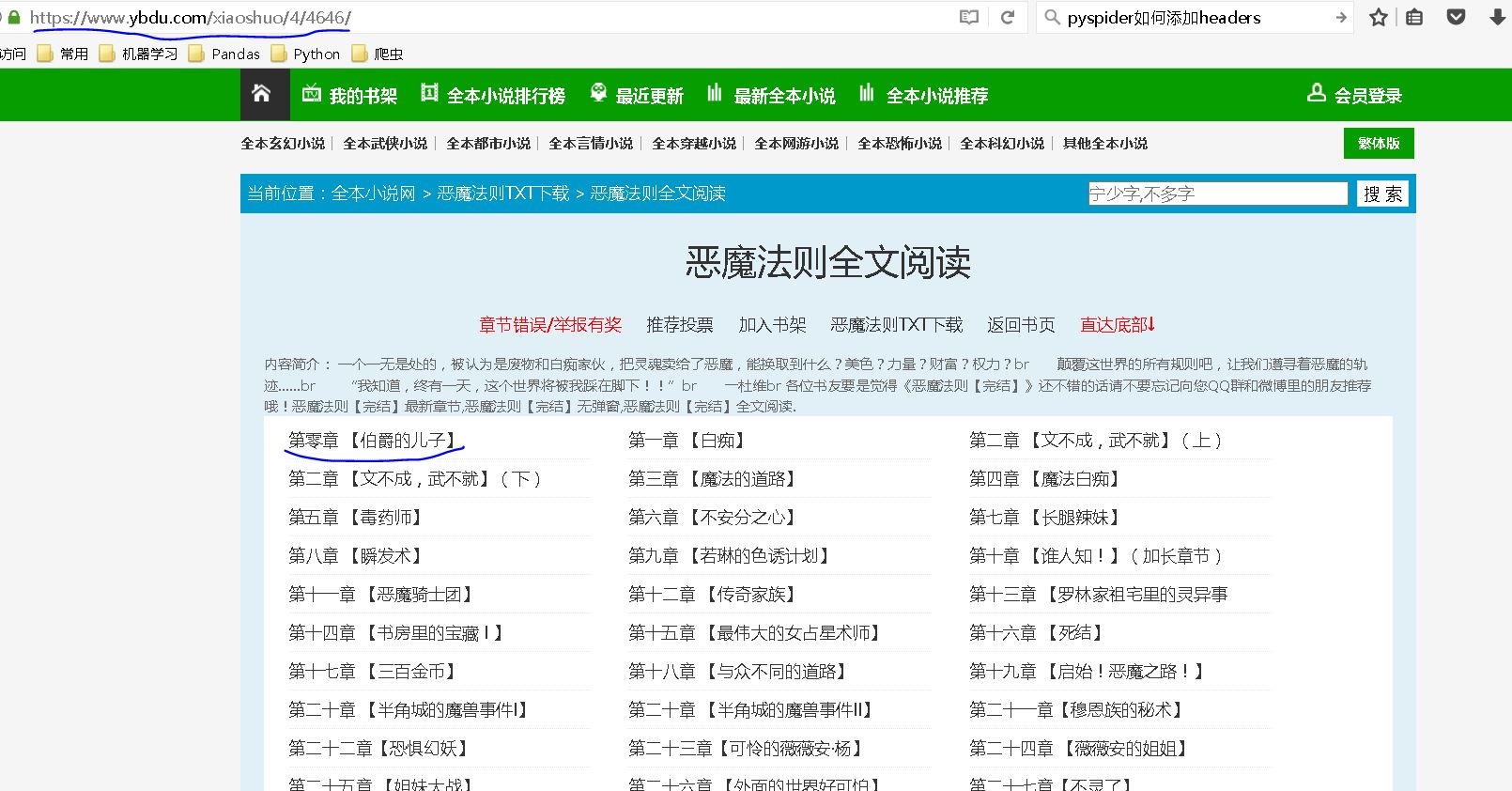
小说目录的url为https://www.ybdu.com/xiaoshuo/4/4646/
创建一个Pyspider项目
我们现在控制台命令行中输入pyspider all,命令,然后打开浏览器,输入http://localhost:5000/。
点击右面的Create按钮,输入项目名称,点击创建即可。
【插入图片,创建项目】

项目内容编辑
创建项目之后,在浏览器出现一个框架,左面是结果显示区,最主要的是一个run命令。
右面是我们输入代码的内容。由于这个代码编辑界面不太友好,建议我们将代码拷贝到pycharm中,编辑好或者修改好之后再复制回来运行。
【插入图片,空白项目内容】

我们如果访问https页面,一定要添加validate_cert=False,否则会报SSL错误。
第一步:on_start()函数
这一步主要是获取目录页。
这个方法会获取url的页面,并且调用callback方法去解析相应内容,产生一个response对象。
【插入图片,小说目录】
@every(minutes=24 * 60)
def on_start(self):
self.crawl(url, callback=self.index_page,validate_cert=False)
第二步:index_page()函数
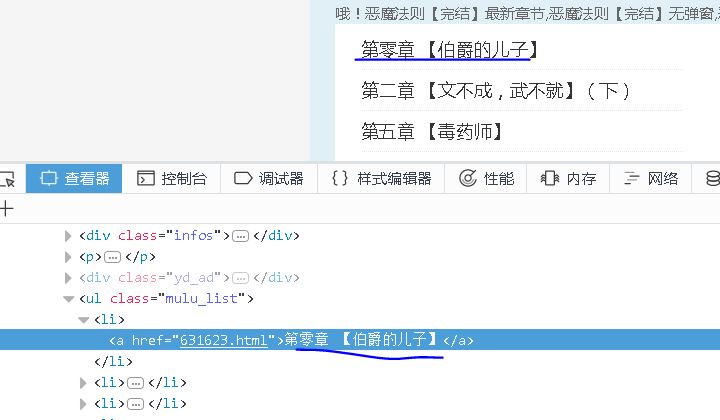
当我们第一次点击run按钮的时候,会对目录页进行解析,返回所有章节的url。
【插入图片,章节标签】
【插入图片,pyspider目录】

@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('ul[class="mulu_list"]>li>a').items():
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
第三步:detail_page()函数
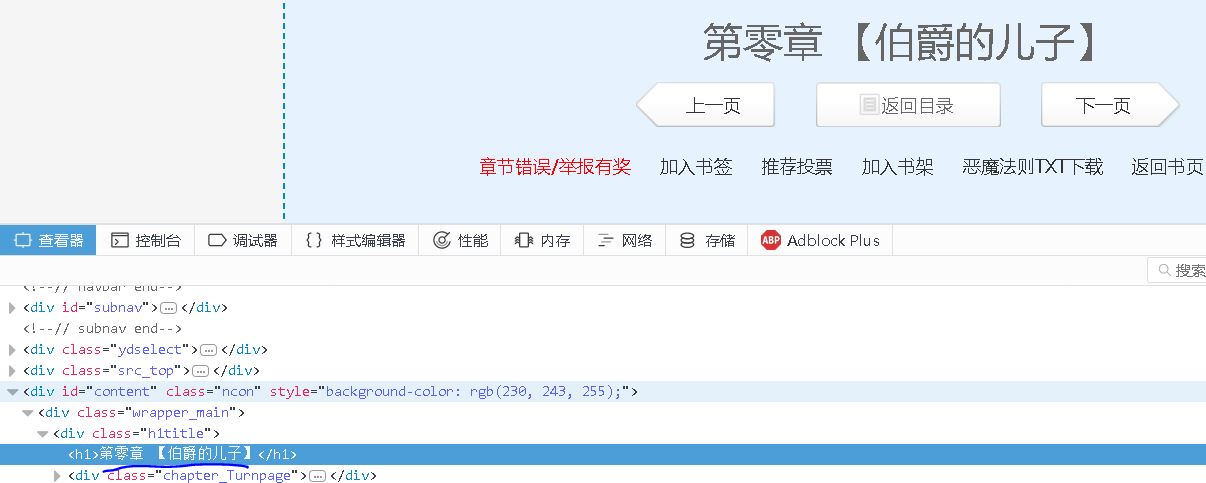
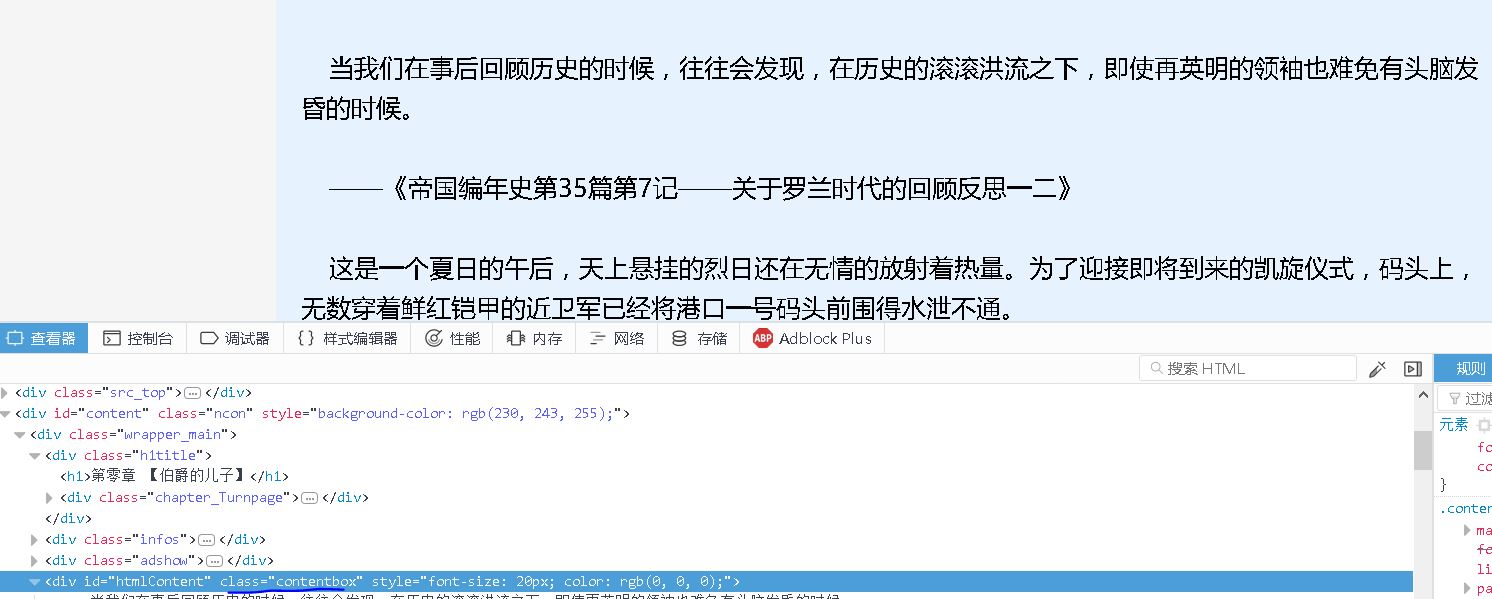
我们将分析每章节的url,获取标题和正文内容,保存成一个txt文件。
【插入图片,标题标签】
【插入图片,正文标签】
@config(priority=2)
def detail_page(self, response):
curPath = os.getcwd()
tempPath = '恶魔法则'
targetPath = curPath + os.path.sep + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
else:
print('路径已经存在!')
filename=response.doc('h1').text()+'.txt'
filePath = targetPath + os.path.sep + filename
with open(filePath, 'w',encoding='utf-8') as f:
content=response.doc('div[class="contentbox"]').text()
f.write(content)
print('写入成功!')
总结
通过以上三步,我们已经将小说的所有章节都能够保存下来。如果让项目自动运行呢?
【插入图片,开始运行】

我们回到Pyspider的控制台,将对应项目的状态调整为running或者debug,点击后面的运行,项目就能够自己动起来了。
【插入图片,结果所有章节】

所有代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-12-12 19:28:47
# Project: Nover_Fetch
import os
from pyspider.libs.base_handler import *
url='https://www.ybdu.com/xiaoshuo/4/4646/'
class Handler(BaseHandler):
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
}
crawl_config = {
'headers':headers,
'timeout':1000
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl(url, callback=self.index_page,validate_cert=False)
#这个方法会获取url的页面,并且调用callback方法去解析相应内容
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('ul[class="mulu_list"]>li>a').items():
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
@config(priority=2)
def detail_page(self, response):
curPath = os.getcwd()
tempPath = '恶魔法则'
targetPath = curPath + os.path.sep + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
else:
print('路径已经存在!')
filename=response.doc('h1').text()+'.txt'
filePath = targetPath + os.path.sep + filename
with open(filePath, 'w',encoding='utf-8') as f:
content=response.doc('div[class="contentbox"]').text()
f.write(content)
print('写入成功!')
爬虫入门【11】Pyspider框架入门—使用HTML和CSS选择器下载小说的更多相关文章
- JavaScript 基础入门11 - 运动框架的封装
目录 JavaScript 运动原理 运动基础 简单运动的封装 淡入淡出 不同属性的设置 多属性值同时运动 运动回调,链式运动 缓冲运动 加入缓冲的运动框架 案例1 多图片展开收缩 运动的留言本 Ja ...
- 爬虫开发11.scrapy框架之CrawlSpider操作
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二:基 ...
- 爬虫学习笔记(2)--创建scrapy项目&&css选择器
一.手动创建scrapy项目---------------- 安装scrapy: pip install -i https://pypi.douban.com/simple/ scrapy 1 ...
- 爬虫入门【10】Pyspider框架简介及安装说明
Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下: 1.可以在Python环境下写脚本 2.具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看. 3.支持多 ...
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- scrapy爬虫框架入门教程
scrapy安装请参考:安装指南. 我们将使用开放目录项目(dmoz)作为抓取的例子. 这篇入门教程将引导你完成如下任务: 创建一个新的Scrapy项目 定义提取的Item 写一个Spider用来爬行 ...
- Scrapy 爬虫框架入门案例详解
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者:崔庆才 Scrapy入门 本篇会通过介绍一个简单的项目,走一遍Scrapy抓取流程,通过这个过程,可以对 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 『Scrapy』爬虫框架入门
框架结构 引擎:处于中央位置协调工作的模块 spiders:生成需求url直接处理响应的单元 调度器:生成url队列(包括去重等) 下载器:直接和互联网打交道的单元 管道:持久化存储的单元 框架安装 ...
随机推荐
- 转: RabbitMQ实现中AMQP与MQTT消息收发异同
转自:http://www.cnblogs.com/lucifer1997/p/9438186.html 实现了AMQP与MQTT(至多一次)后,用多个队列以topic exchange的方式用相同交 ...
- mysql创建账号对应的数据库方法
增加一个用户mydb密码为123450, 让他只可以在(localhost/%)%表示可以支持远程上登录,并可以对数据库mydata5_db进行查询.插入.修改.删除的操作. grant select ...
- 如何在mysql下实现事务的提交与回滚
最近要对数据库的数据进行一个定时迁移,为了防止在执行过程sql语句因为某些原因报错而导致数据转移混乱,因此要对我们的脚本加以事务进行控制. 首先我们建一张tran_test表 CREATE TABLE ...
- SS不能在Win7中打开,出现停止运行
一次,在Win7上不能打开SS,经过搜索,好像SS的win客户端使用.net frame4.6.2开发,但是Win7根本安装不了该版本的.net,所以...,重新安装Win10.
- Sublime Text 编辑器 插件 之 "Sublime Alignment" 详解
作者:shede333主页:http://my.oschina.net/shede333版权声明:原创文章,版权声明:自由转载-非商用-非衍生-保持署名 | [Creative Commons BY- ...
- centos6.x 抓取ssh登录的用户名和密码
systemtap是一款非常强大内核调试工具,可以debug很多关于kernel层的问题.Linux是通过PAM模块检测用户信息和认证信息的,从而确定一个用户是否可以登录系统,利用这个知识点,使用sy ...
- make命令用法--转
转自:http://www.techug.com/make 代码变成可执行文件,叫做编译(compile):先编译这个,还是先编译那个(即编译的安排),叫做构建(build). Make是最常用的构建 ...
- jquery远程引用地址大全
jquery官方的引用地址,如图: <script typet="text/javascript" src="http://code.jquery.com/jque ...
- golang mongodb查找find demo
使用gopkg.in/mgo.v2库操作,插入操作主要使用mongodb中Collection对象的Find方法,函数原型: func (c *Collection) Find(query inter ...
- spring mvc 3.0 实现文件上传功能
http://club.jledu.gov.cn/?uid-5282-action-viewspace-itemid-188672 —————————————————————————————————— ...