ES6快到碗里来---一个简单的爬虫指南
学习ES6的时候,没少看ES6入门,到现在也就明白了个大概(惭愧脸)。这里不谈ES6,只谈怎么把ES6的页面爬下来放到一起成为一个离线文档。
之前居然没注意过作者把这本书开源了。。瞎耽误功夫。。。地址
通俗易懂_小白friendly_
node 爬虫入门
如果你之前没有用node写过一个爬虫,可以从这篇文章开始。Node.JS 妹子图爬虫(1),除了核心模块外,文章中还用到cheerio这个库来分析访问的页面。cheerio是一个类似于jquery的库,但是运行在node上。而这里主要用到:
node的
http模块fs模块- ES6promise的一些知识。
show time!
分析要抓的页面路径
这里就放在浏览器上了,当然也可以用http放在后端,F12可以发现,所有链接在一个ol元素里,如图:
所以把所有链接地址存到数组里的代码如下:(在控制台输入)
var links=[];
Array.from($("[start='0'] a")).forEach(function(e){links.push(e.getAttribute("href"))});
JSON.stringfy(links)//便于复制数组
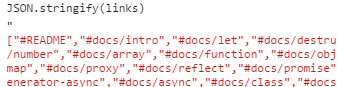
服务端
新建一个js文件。接下来就是陪links玩了。首先我们写出了以下的渣代码,不过还好可以跑
var fs = require('fs'),http = require('http');
var links = ["#README", "#docs/intro", "#docs/let", "#docs/destructuring", "#docs/string", "#docs/regex", "#docs/number", "#docs/array", "#docs/function", "#docs/object", "#docs/symbol", "#docs/set-map", "#docs/proxy", "#docs/reflect", "#docs/promise", "#docs/iterator", "#docs/generator", "#docs/generator-async", "#docs/async", "#docs/class", "#docs/decorator", "#docs/module", "#docs/module-loader", "#docs/style", "#docs/spec", "#docs/arraybuffer", "#docs/simd", "#docs/reference"];
var allInOne = "",
host = "http://es6.ruanyifeng.com/";
var realLinks = links.map(function(link) { return link.slice(1) + '.md' });//迷之reallinks
console.log(links.length);
现在你就可以先在命令行里node getES6了,除了得到数组长度外并没有什么用。
请求
有了原料之后,开始下锅了,我们的构想是,写一个循环来依次请求这些页面,然后把得到的html字符串写到一起:
var allInOne = "",
n = 0;//数数用
for(let link of links) {
n++;
allInOne += getHTML(host + link, n);
}
}
接下来实现getHtml这个函数:
function getHTML(url, n, id = "body") {
var promise = new Promise(function(resolve, reject) {//不清楚的看http://es6.ruanyifeng.com/#docs/promise
var pageStr = '';//用于放html或md文件
var req = http.get(url, function(res) {//发起请求
res.setEncoding('utf8');
var status = res.statusCode;
if(status == '200') {
res.on('data', function(chunk) {
pageStr += chunk;
});
res.on('end', function(data) {
allInOne += pageStr;
fs.appendFile(`./page/${n}.md`, pageStr, 'utf8', function(e) {//将文件保存到本地的page文件夹下,后缀是md?
console.log(e);
});
console.log(`finish load ${url}`);
resolve();
});
}
});
});
return promise;
}
将上面两个个代码片段拼到一起,可以先node ES6跑跑看了,是不是与期望不符?下回再说。
ES6快到碗里来---一个简单的爬虫指南的更多相关文章
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- Python并发编程-一个简单的爬虫
一个简单的爬虫 #网页状态码 #200 正常 #404 网页找不到 #502 504 import requests from multiprocessing import Pool def get( ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- 用node.js从零开始去写一个简单的爬虫
如果你不会Python语言,正好又是一个node.js小白,看完这篇文章之后,一定会觉得受益匪浅,感受到自己又新get到了一门技能,如何用node.js从零开始去写一个简单的爬虫,十分钟时间就能搞定, ...
- nodejs实现一个简单的爬虫
nodejs是js语言,实现一个爬出非常的方便. 步骤 1. 使用nodejs的request模块,获取目标页面的html代码:https://github.com/request/request 2 ...
- 爬虫浅谈一:一个简单c#爬虫程序
这篇文章只是简单展示一个基于HTTP请求如何抓取数据的文章,如觉得简单的朋友,后续我们再慢慢深入研究探讨. 图1: 如图1,我们工作过程中,无论平台网站还是企业官网,总少不了新闻展示.如某天产品经理跟 ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
- Python网络爬虫 - 一个简单的爬虫例子
下面我们创建一个真正的爬虫例子 爬取我的博客园个人主页首页的推荐文章列表和地址 scrape_home_articles.py from urllib.request import urlopen f ...
随机推荐
- (转)mysql command line client打不开(闪一下消失)的解决办法
转自:http://www.2cto.com/database/201209/153858.html 网上搜索到的解决办法: 1.找到mysql安装目录下的bin目录路径. 2.打开cmd,进入到bi ...
- STM32F10X-定时器/计数器
1.STM32F10X的计数器与定时器关系 当时钟连接外脉冲时是计数器:当时钟采用系统内部时钟时是定时器! 2.STM32F10X定时器的时钟源 STM32F10X定时器的时钟不是直接来至于APB1和 ...
- Mac使用终端安装Homebrew(brew)
Homebrew简称brew,OSX上的软件包管理工具,在Mac终端可以通过brew安装.更新.卸载软件. 1.打开终端直接输入下面指令回车: // ruby -e "$(curl -fsS ...
- Mybatis类型转换介绍
1.1 目录 1.2 建立TypeHandler 1.2.1 TypeHandler接口 1.2.2 BaseTypeHandler抽象类 1.3 注册TypeHa ...
- JavaScript 获取鼠标点击位置坐标
在一些DOM操作中我们经常会跟元素的位置打交道,鼠标交互式一个经常用到的方面,令人失望的是不同的浏览器下会有不同的结果甚至是有的浏览器下没结果,这篇文章就上鼠标点击位置坐标获取做一些简单的总结,没特殊 ...
- [mysql语句] mysql 语句收集
// http://stackoverflow.com/questions/6666152/mysql-order-by-where 1. "select * from t_activity ...
- (原创)用c++11打造好用的any
上一篇博文用c++11实现了variant,有童鞋说何不把any也实现一把,我正有此意,它的兄弟variant已经实现了,any也顺便打包实现了吧.其实boost.any已经挺好了,就是转换异常时,看 ...
- 利用GDI+处理图像的色彩
首先先介绍一下ColorMatrix结构体:表示颜色的变换关系,定义如下: typedef struct { REAL m[][]; } ColorMatrix; ColorMatrix结构体一般和I ...
- 未能加载文件或程序集“System.Web.Http.WebHost, Version=4.0.0.0, ”或它的某一个依赖项。系统找不到指定的文件。
第一次发布MVC项目,打开网站 未能加载文件或程序集“System.Web.Http.WebHost, Version=4.0.0.0, ”或它的某一个依赖项.系统找不到指定的文件. 问题原因:缺少配 ...
- XML hexadecimal value 0x__, is an invalid character
XML操作时异常:(十六进制值 0x__) 是无效的字符. 方法一: 设置 CheckCharacters=false. XmlReaderSettings xmlReaderSettings = n ...