elasticsearch跨集群数据迁移
写这篇文章,主要是目前公司要把ES从2.4.1升级到最新版本7.8,不过现在是7.9了,官方的文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
由于从2.4.1跨很大基本的升级,所以不能平滑的升级了,只能重新搭建集群进行数据迁移,所以迁移数据是第一步,但是呢,2.4.1是可以支持多个type的,现在的新版已经不能支持多个type了,所以在迁移的过程中要将每一个type建立相应的索引,目前只是根据原先的type之间创建新的索引,还没考虑到业务的需求,这个可能需要重新设计索引。
本文主要针对在实际过程中遇到的几个问题进行阐述,第一步迁移的方案选择,第二怎么去迁移,第三对遇到的问题进行解决
一、迁移方案的选择
主要参考下这篇文章:https://www.jianshu.com/p/50ef4c9090f0
我个人觉得比较熟悉的方法选择三种:
一个是备份和还原,也就是说使用snapshot,官方的网址:https://www.elastic.co/guide/en/elasticsearch/reference/current/snapshot-restore.html
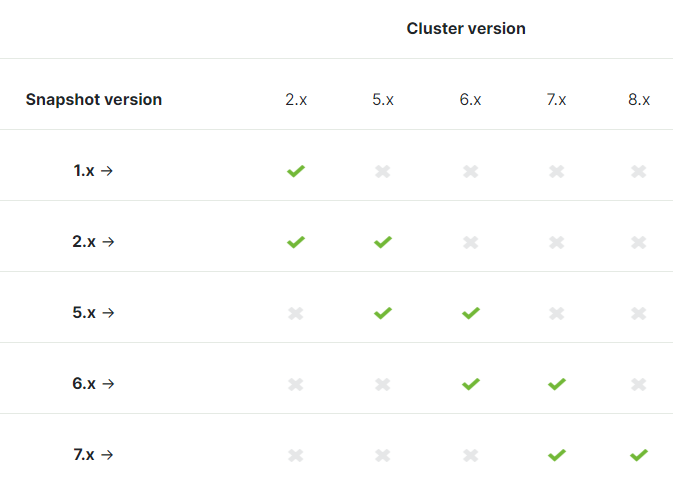
然后发现只能跨一个版本升级,并不不符合我目前的需求,所以排除这个方案。
第二个是使用elk的方式,使用logstash,我有另外一篇文章介绍这个的玩法:从0到1学会logstash的玩法(ELK)
logstash的官方文档:https://www.elastic.co/guide/en/logstash/current/index.html
这个方法确实可以实现迁移,但是对于不熟悉这个elk的童鞋来说有点难,因为刚开始接触,也不是那么的友好,所以我在这里并没有优先选择。
第三种方案就是采用elasticsearch的一个接口_reindex,这个方法很简单,官方文档也很详细,上手也比较快,所以选择了该方案,以前也没接触过,所以也要研究下吧,所以就有官方的文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/docs-reindex.html,对英文不是很熟的童鞋完全可以搜索其他博客,很多博客都有详细的介绍,我也是看别人的博客,但是忘记网址了,然后再来看官网补充下,毕竟官网的是比较可信点。
二、迁移的语法
我们的需求是跨集群进行数据迁移,所以这里不说同集群的迁移,因为对于跨集群来说,同一个集群更简单。
第一步:配置新版es的参数,就是配置白名单,允许哪个集群可以reindex数据进来,在官网copy了一段,根据自己的实际情况进行修改就好,需要重启
reindex.remote.whitelist: "otherhost:9200, another:9200, 127.0.10.*:9200, localhost:*"
第二步:就是在新版的es上建立索引,设置好分片,副本(刚开始为0吧)等,因为自动创建的分片和副本都是1,所以自己先创建好索引比较好
第三步:直接配置啦,这里我就直接贴代码了,具体的介绍可以去看官网啦
curl -u user:password -XPOST "http://ip_new:port/_reindex" -H 'Content-Type:application/json' -d ' #这里的user,port,ip,password都是新集群的
{
"conflicts": "proceed",
"source": {
"remote": { #这是2.4.1的配置
"host": "http://ip:port/",
"username": "user",
"password": "password"
},
"index": "index_name_source", #2.4.1的要迁移的索引
"query": {
"term": {
"_type":"type_name" #查询单个type的数据
}
},
"size": 6000 #这个参数可以根据实际情况调整
},
"dest": {
"index": "index_name_dest", #这里是新es的索引名字
}
}'
好,很好,好了,那就跑起来,刚开始第一个小的索引跑起来没任何问题,刚开始以为就这么简单,后来索引大了,不合理的设计,就出现下面的问题了
三、遇到的问题和解决方案
我。。。这是神马设计,一个文档的id这么长id is too long, must be no longer than 512 bytes but was: 574;

因为在elasticsearch7.8中的id最长为512啦,可以看看这个:https://github.com/elastic/elasticsearch/pull/16036/commits/99052c3fef16d6192af0839558ce3dbf23aa148d

没啥不服气的吧,那怎么解决这个问题呢,id好像不好改吧,网上都说要自己写代码去重新缩短这个id的长度。好吧,感觉有点复杂了,我又去看reindex这个文档的,官方文档啦,原来还支持脚本呢,但是这里这个支持的脚本有点强大,比那个update_by_query的脚本强大,可以改id哦,

看到没,这些都可以修改,看到了希望有没有?接下我就修改迁移的代码啦:
curl -u user:password -XPOST "http://ip_new:port/_reindex" -H 'Content-Type:application/json' -d ' #这里的user,port,ip,password都是新集群的
{
"conflicts": "proceed",
"source": {
"remote": { #这是2..1的配置
"host": "http://ip:port/",
"username": "user",
"password": "password"
},
"index": "index_name_source",
"query": {
"term": {
"_type":"type_name" #查询单个type的数据
}
},
"size": #这个参数可以根据实际情况调整
},
"dest": {
"index": "index_name_dest", #这里是新es的索引名字
},
"script": {
"source": "if (ctx._id.length()>512) {ctx._id = ctx._id.substring(0,511)}", #这里我简单粗暴,截断了,各位可以根据需求去改,这里和java的语法相似的
"lang": "painless"
}
}'
果然解决了问题,迁移数据没问题了,很好,非常好,但是总是不那么如意,当一个索引很大,3+个T的数据(吐槽下,什么鬼,原来的索引还只有6个分片,这个设计。。。)就会curl出问题了,出问题了,中途中断了,说是无法接收到网络数据:
curl: (56) Failure when receiving data from the peer #这个问题网上很多人都问,但是都没解决方案,有人说这是bug
就这么认命了吗,每次跑了一半多,白干活了,这个错误也是真的没啥详细说明呀,有点惨,我想升级这个curl的版本,但是升级失败了
算了,没劲,那就换一个centos7.x的机器看看curl的版本吧,果然比这个高一些,那就换机器继续试试啦。果然没让我失望,没在出现这个问题了。好吧顺利的去迁移数据去了,不过那个size参数是可以调整的,太大了会报错的,要根据文档的大小*size,这个值在5-15M之间速度会比较快一些,我这也还没对比测试。
这里感谢各个写博客的博主,看了很多的博客,解决问题思路,但是没有记录下,现在也就记得这么多了,好久没写博客了,最近看了很多基础的书,果然出来混迟早是要还的,以前落下的基础知识,总要花费一个代价补回去的,也希望自己能够与各位童鞋一起学习进步,一直相信最好的学就是教会别人
elasticsearch跨集群数据迁移的更多相关文章
- elasticsearch7.5.0+kibana-7.5.0+cerebro-0.8.5集群生产环境安装配置及通过elasticsearch-migration工具做新老集群数据迁移
一.服务器准备 目前有两台128G内存服务器,故准备每台启动两个es实例,再加一台虚机,共五个节点,保证down一台服务器两个节点数据不受影响. 二.系统初始化 参见我上一篇kafka系统初始化:ht ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- 【Redis】集群数据迁移
Redis通过对KEY计算hash,将KEY映射到slot,集群中每个节点负责一部分slot的方式管理数据,slot最大个数为16384. 在集群节点对应的结构体变量clusterNode中可以看到s ...
- Elasticsearch跨集群搜索(Cross Cluster Search)
1.简介 Elasticsearch在5.3版本中引入了Cross Cluster Search(CCS 跨集群搜索)功能,用来替换掉要被废弃的Tribe Node.类似Tribe Node,Cros ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- Elasticsearch多集群数据同步
有时多个Elasticsearch集群避免不了要同步数据,网上查找了下数据同步工具还挺多,比较常用的有:elasticserach-dump.elasticsearch-exporter.logsta ...
- redis集群数据迁移txt版
./redis-trib.rb create --replicas 1 192.168.112.33:8001 192.168.112.33:8002 192.168.112.33:8003 192. ...
- redis集群数据迁移
redis集群数据备份迁移方案 n 迁移环境描述及分析 当前我们面临的数据迁移环境是:集群->集群. 源集群: 源集群为6节点,3主3备 主 备 192.168.112.33:8001 192 ...
- 多es 集群数据迁移方案
前言 加入新公司的第二个星期的星期二 遇到另一个项目需要技术性支持:验证es多集群的数据备份方案,需要我参与验证,在这个项目中需要关注到两个集群的互通性.es集群是部署在不同的k8s环境中,K8s环境 ...
随机推荐
- vue cli 中关于vue.config.js中chainWebpack的配置
Vue CLI 的官方文档上写:调整webpack配置最简单的方式就是在vue.config.js中的configureWebpack选项提供一个对象. Vue CLI 内部的 webpack 配置 ...
- [netty4][netty-handler]netty之idle handler处理
初始化时记录idle时间,并启动一个延时任务,延时时间为idle时间,延时任务是io.netty.handler.timeout.IdleStateHandler.AllIdleTimeoutTask ...
- 前端vue2-org-tree实现精美组织架构图
最近遇到开发组织架构的需求,与以往开发的组织架构不同,不光要展示人名,还要显示职务(或者子公司名称).对应的头像等,并且要考虑,如果用户未上传头像,需使用默认头像(男.女.中性),(⊙o⊙)…要尊重尊 ...
- 使用BurpSuite、Hydra和medusa爆破相关的服务
一.基本定义 1.爆破=爆破工具(BP/hydra)+字典(用户字典/密码字典). 字典:就是一些用户名或者口令(弱口令/使用社工软件的生成)的集合. 2.BurpSuite 渗透测试神器,使用Jav ...
- Windows server 2008R2 中sql server的搭建
一.安装sql server Step1:下载sql server 2008 r2 standard,解压到Windows的C:\下. Step2:打开安装程序,进行sql server的安装 Ste ...
- 使用 codeblocks 编写C++ udp组播程序遇到的问题
编译错误 会出现好多undefined reference to'WSAStartup to@8之类的错误,都是undefind开头的 解决方法: Settings -> Compiler se ...
- windows下RocketMQ的安装部署
一.预备环境 1.系统 Windows 2. 环境 JDK1.8.Maven.Git 二. RocketMQ部署 1.下载 1.1地址:http://rocketmq.apache.org/relea ...
- Mysql Lost connection to MySQL server at ‘reading initial communication packet', system error: 0
在用Navicat for MySQL远程连接mysql的时候,出现了 Lost connection to MySQL server at ‘reading initial communicatio ...
- CentOS下删除物理磁盘,删除LVM
1.删除 dmsetup remove LV_name 2.vgreduce VG_name --removemissing 3.vgremove VG_name 4.pvremove disk
- Spring Security认证流程分析--练气后期
写在前面 在前一篇文章中,我们介绍了如何配置spring security的自定义认证页面,以及前后端分离场景下如何获取spring security的CSRF Token.在这一篇文章中我们将来分析 ...