[论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 参考文献
(1) 解决问题
由于DeepWalk的随机游走是完全无指导的随机采样,即随机游走不可控。本文从该问题出发,设计了一种有偏向的随机游走策略,使得随机游走可以在DFS和BFS两种极端搜索方式中取得平衡。
(2) 主要贡献
Contribution: 本篇论文主要的创新点在于改进了随机游走的策略,定义了两个参数p和q,使得随机游走在BFS和DFS两种极端中达到一个平衡,同时考虑到局部和宏观的信息。
(3) 算法原理
node2vec算法框架主要包含两个部分:首先在图上做有偏向的随机游走,其次将得到的节点序列输入Skip-Gram模型学习节点表示向量嵌入(不再赘述,参考DeepWalk)。
有偏的随机游走策略:
其定义了两个参数p(向后参数)和q(向前参数),在广度优先搜索(BFS)和深度优先搜索(DFS)两种极端中达到一个平衡,从而同时考虑到局部和全局的结构信息。给定源点u,利用有偏随机游走生成长度为L的序列,随机游走的转移概率计算公式设计如下:
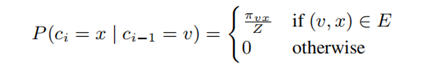
ci表示序列中的第i个点,c0=u,Z为一个归一化常数。分母πvx为v到x的非归一化的转移概率,如下所示(dtx为上一跳节点t与下一跳考虑跳转节点的距离):
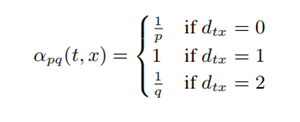
以一个例子来解释,如下图所示:

假设随机游走的上一跳节点是t,当前节点是v,则依据上述转移概率公式的设计下一跳节点怎么选择呢?下一跳节点可能是x1,x2,x3和t。由于x1与上一跳节点距离1跳,因此下一跳到节点x1的非归一化转移概率为1,而x2、x3与上一跳节点距离2跳,因此下一跳到x2和x3的非归一化转移概率均为1/q,此外t与上一跳节点距离0跳,因此下一跳到t的非归一化转移概率为1/p。以上便是Node2vec中设计的权衡BFS和DFS的随机游走策略。
通过以上方式生成同构网络上的随机游走序列之后,采用Skip-Gram模型训练节点向量即可。
(4) 参考文献
Grover A, Leskovec J. node2vec: Scalable feature learning for networks[A]. Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining[C]. 2016: 855–864.
[论文阅读笔记] node2vec Scalable Feature Learning for Networks的更多相关文章
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- 论文解读(node2vec)《node2vec Scalable Feature Learning for Networks》
论文题目:<node2vec Scalable Feature Learning for Network>发表时间: KDD 2016 论文作者: Aditya Grover;Adit ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 ...
- 论文阅读笔记二十三:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR2017)
论文源址:https://arxiv.org/abs/1709.04609 摘要 该文提出了基于深度学习的实例分割框架,主要分为三步,(1)训练一个基于ResNet-101的通用模型,用于分割图像中的 ...
- 论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)
论文源址:https://arxiv.org/abs/1705.06820 tensorflow(github): https://github.com/HongyangGao/PixelDCN 基于 ...
- [论文阅读笔记] LouvainNE Hierarchical Louvain Method for High Quality and Scalable Network Embedding
[论文阅读笔记] LouvainNE: Hierarchical Louvain Method for High Quality and Scalable Network Embedding 本文结构 ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
随机推荐
- 第十五章、Model/View架构中Item Views部件的父类
老猿Python博文目录 老猿Python博客地址 引言:本章早就写好了,其简版<第15.18节 PyQt(Python+Qt)入门学习:Model/View架构中视图Item Views父类详 ...
- PyQt(Python+Qt)学习随笔:clicked和clicked(bool)信号连接同名函数出现的问题
在Qt中,控件中的clicked()信号和clicked(bool)信号是两个不同的信号,映射槽函数时,clicked()信号映射到的槽函数是不带参的,clicked(bool)信号映射到的槽函数是带 ...
- PyQt(Python+Qt)学习随笔:Qt Designer中建立CommandLinkButton信号与Action的槽函数连接
在Qt Designer中,通过F4进行信号和槽函数连接编辑时,接收信号的对象不能是Action对象,但在右侧的编辑界面,可以选择将一个界面对象的信号与Action对象的槽函数连接起来. 如图: 上图 ...
- QQFishing QQ钓鱼站点搭建
答:为什么要写这个代码? 当然不是做黑产去盗别人扣扣,也没有啥查看别人隐私信息的癖好,搭建该站点的适用对象为->使用社会工程学定向钓鱼攻击的安全渗透人员 另外管理员界面后端写的很丑+很烂,除了我 ...
- SQL注入WAF绕过姿势
(1)大小写绕过 此类绕过不经常使用,但是用的时候也不能忘了它,他原理是基于SQL语句不分大小写的,但过滤只过滤其中一种. 这里有道题 (2)替换关键字 这种情况下大小写转化无法绕过而且正则表达式会替 ...
- CSS基础-边框
border border-top设置上边界 border-bottom / border-left / border-right 同理 可以为每一条边设置 : border-top-width宽度 ...
- Spring AOP的理解(通俗易懂)。
转载 原文链接:http://www.verydemo.com/demo_c143_i20837.html 这种在运行时,动态地将代码切入到类的指定方法.指定位置上的编程思想就是面向切面的编程. 1. ...
- day109:MoFang:好友列表显示&添加好友页面初始化&添加好友后端接口
目录 1.好友列表 2.添加好友-前端 3.服务端提供添加好友的后端接口 1.好友列表 1.在用户中心页面添加好友列表点击入口 html/user.html,用户中心添加好友列表点击入口,代码: &l ...
- 其它语言通过HiveServer2访问Hive
先解释一下几个名词: metadata :hive元数据,即hive定义的表名,字段名,类型,分区,用户这些数据.一般存储关系型书库mysql中,在测试阶段也可以用hive内置Derby数据库. me ...
- Hbase系列文章
Hbase系列文章 HBase(一): c#访问hbase组件开发 HBase(二): c#访问HBase之股票行情Demo HBase(三): Azure HDInsigt HBase表数据导入本地 ...