Spark核心组件通识概览
在说Spark之前,笔者在这里向对Spark感兴趣的小伙伴们建议,想要了解、学习、使用好Spark,Spark的官网是一个很好的工具,几乎能满足你大部分需求。同时,建议学习一下scala语言,主要基于两点:1. Spark是scala语言编写的,要想学好Spark必须研读分析它的源码,当然其他技术也不例外;2. 用scala语言编写Spark程序相对于用Java更方便、简洁、开发效率更高(后续我会针对scala语言做单独讲解)。书归正传,下面整体介绍一下Spark生态圈。
Apache Spark是一种快速、通用、可扩展、可容错的、基于内存迭代计算的大数据分析引擎。首先强调一点, Spark目前是一个处理数据的计算引擎, 不做存储。首先咱们通过一张图来看看目前Spark生态圈都包括哪些核心组件:
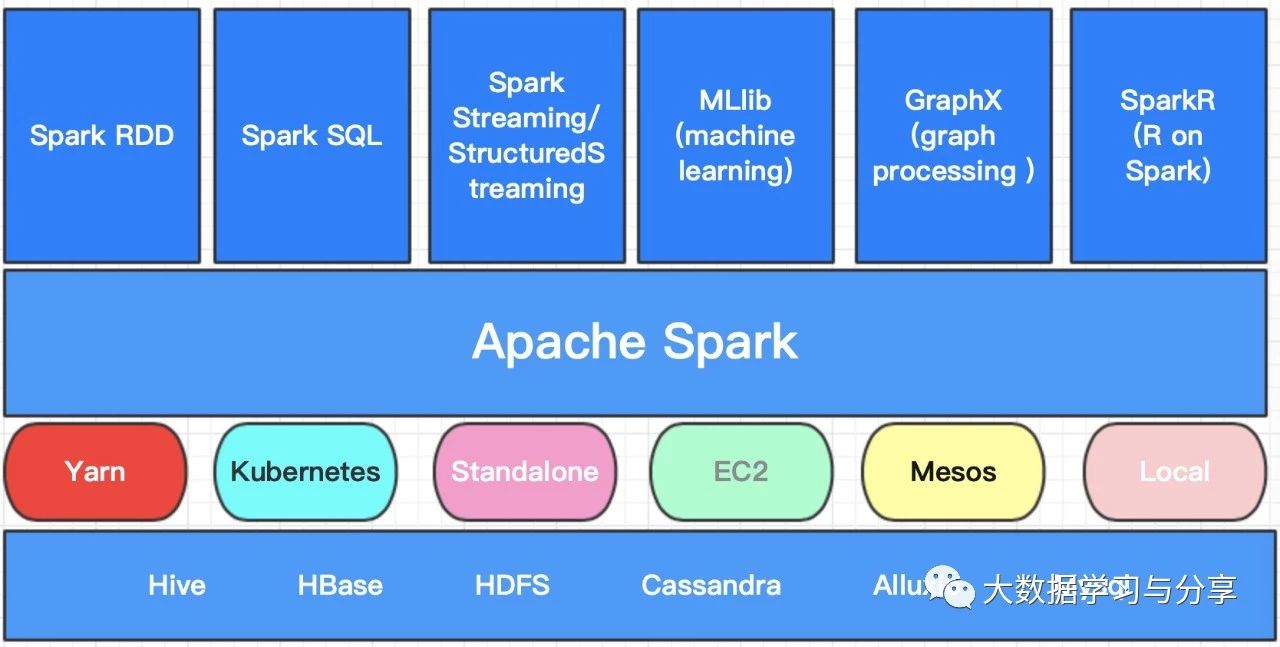
本篇文章先简单介绍一下各个组件的使用场景,后续笔者会单独详解其中的核心组件,以下所讲均基于Spark2.X版本。
Spark RDD和Spark SQL
Spark RDD和Spark SQL多用于离线场景,但Spark RDD即可以处理结构化数据也可以处理非结构数据,但Spark SQL是处理结构化数据的,内部通过dataset来处理分布式数据集
SparkStreaming和StructuredStreaming
用于流式处理,但强调一点Spark Streaming是基于微批处理来处理数据的,即使Structured Streaming在实时方面作了一定优化,但就目前而言,相对于Flink、Storm,Spark的流式处理准备确实准实时处理
MLlib
用于机器学习,当然pyspark也有应用是基于python做数据处理
GraphX
用于图计算
Spark R
基于R语言进行数据处理、统计分析的
下面介绍一下Spark的特性
快
实现DAG执行引擎,基于内存迭代式计算处理数据,Spark可以将数据分析过程的中间结果保存在内存中,从而不需要反复的从外部存储系统中读写数据,相较于mapreduce能更好地适用于机器学习和数据挖掘和等需要迭代运算的场景。易用
支持scala、java、python、R多种语言;支持多种高级算子(目前有80多种),使用户可以快速构建不同应用;支持scala、python等shell交互式查询通用
Spark强调一站式解决方案,集批处理、流处理、交互式查询、机器学习及图计算于一体,避免多种运算场景下需要部署不同集群带来的资源浪费容错性好
在分布式数据集计算时通过checkpoint来实现容错,当某个运算环节失败时,不需要从头开始重新计算【往往是checkpoint到HDFS上】兼容性强
可以运行在Yarn、Kubernetes、Mesos等资源管理器上,实现Standalone模式作为内置资源管理调度器,支持多种数据源
关注微信公众号:大数据学习与分享,获取更多技术干货
Spark核心组件通识概览的更多相关文章
- [Spark Core] Spark 核心组件
0. 说明 [Spark 核心组件示意图] 1. RDD resilient distributed dataset , 弹性数据集 轻量级的数据集合,逻辑上的集合.等价于 list 没有携带数据. ...
- Spark核心组件
Spark核心组件 1.RDD resilient distributed dataset, 弹性分布式数据集.逻辑上的组件,是spark的基本抽象,代表不可变,分区化的元素集合,可以进行并行操作.该 ...
- 【原】Spark Rpc通信源码分析
Spark 1.6+推出了以RPCEnv.RPCEndpoint.RPCEndpointRef为核心的新型架构下的RPC通信方式.其具体实现有Akka和Netty两种方式,Akka是基于Scala的A ...
- 前端进阶笔记(一)---JS语言通识
一.语言按照语法分类 1.非形式语言:中文 英文 2.形式语言:乔姆斯基谱系(四种文法 上下文包含文法) 0型 无限制文法 1型 上下文相关文法 2型 上下文无关文法 正则文法 二 产生式(BNF) ...
- linux通识
linux是服务器应用领域的开源且免费的多用户多任务操作系统的内核. 以下是对上述论断的解释: 操作系统 简言之,操作系统乃是所有计算设备的大管家,小到智能手表,大到航天航空设备,所有需要操控硬件的地 ...
- java IO流体系--通识篇
1.I/O流是什么 Java的I/O流是实现编程语言的输入/输出的基础能力,操作的对象有外部设备.存储设备.网络连接等等,是所有服务器端的编程语言都应该具备的基础能力. I = Input(输入),输 ...
- Spark内核| 调度策略| SparkShuffle| 内存管理| 内存空间分配| 核心组件
1. 调度策略 TaskScheduler会先把DAGScheduler给过来的TaskSet封装成TaskSetManager扔到任务队列里,然后再从任务队列里按照一定的规则把它们取出来在Sched ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
随机推荐
- origin Tips
origin Tips 注意事项 在最初画图时,需要考虑到最好将图片的尺寸限制在 1 张 A4 纸的大小,不然有可能在插入 latex 的时候出问题 . 如何修改图片的尺寸?简而言之就是将画布中的图片 ...
- 关于非标准json格式转变为json对象
eval('(' + tempData + ')') 只需要这一句
- PHP对象传值 - 引用传值
对象传值本质上是引用传值,将一个对象变量($a)赋值给另个变量($b),实际上是将$a存储的对象内存引用地址赋值$b,此时两个变量指向的就是一个对象.其中一个变量发送改变,另一个也会跟着改变.和引用变 ...
- 一篇文章教你快速上手接口管理工具swagger
一.关于swagger 1.什么是swagger? swagger是spring fox的一套产品,可以作为后端开发者测试接口的工具,也可以作为前端取数据的接口文档. 2.为什么使用? 相比于传统的接 ...
- CTF-WeChall-第四天上午
2020.09.12 08:24 哈哈,go on!
- [LeetCode]42. 接雨水(双指针,DP)
题目 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水. 上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下, ...
- Spring的三大核心接口——BeanFactory、ApplicationContext、WebApplicationContext
之前也在用这三个接口,但是对于他们的概念还是处于朦胧状态,同时,也不知道他们之间是一个什么关系,趁着现在有点时间总结一下吧,也需要对你有所帮助.一.BeanFactory 基本认识: ...
- NX导入DWG失败
给客户开发的NX导入DWG图纸功能,部分电脑偶尔出现导入失败的情况,且几乎没有规律可言.客户无法理解,坚持认为是代码的问题,毕竟使用的是我们二次开发的功能.我本机没有问题,在某些出问题的电脑上也尝试多 ...
- python中不需要函数重载的原因
函数重载主要是为了解决两个问题: 1.可变参数类型 2.可变参数个数 并且函数重载一个基本的设计原则是,仅仅当两个函数除了参数类型和参数个数不同以外,其功能是完全相同的,此时才使用函数重载,如果两个函 ...
- gRPC-Protocol语法指南
语法指南 (proto3) Defining A Message Type Scalar Value Types Default Values Enumerations Using Other Mes ...