超级无敌详细使用ubuntu搭建hadoop完全分布式集群
一、软件准备
- 安装VMware
- 下载ubuntu镜像(阿里源ubuntu下载地址)选择自己适合的版本,以下我使用的是18.04-server版就是没有桌面的。安装桌面版如果自己电脑配置不行的话启动集群容易卡死。
(说明一下哈就是桌面版和服务器版没什么太大的区别,桌面版为个人电脑所配置,预装了图形界面和一些其他软件,比如LibreOffice,音乐播放器,游戏等等,而服务器版没有这些东西,服务器版启动之后只有一个黑屏+光标,所有的操作都是命令形式的)
- 下载Hadoop和jdk(链接:https://pan.baidu.com/s/1QL4flw5_XRhVrGouZyPhjg
提取码:a0z6 )也可以去官网下载。 - 准备xshell和xftp后期要使用xftp网虚拟机上上传文件(链接:https://pan.baidu.com/s/1nkMCSxuVPFKO6wiLdAB7cA
提取码:mbb6 )
二、安装过程
- 首先在VMware里创建一个名为master的虚拟机(在已经安装完VMware的前提下)
打开VMware点击-----创建新的虚拟机弹出窗口选择典型安装即可----下一步:
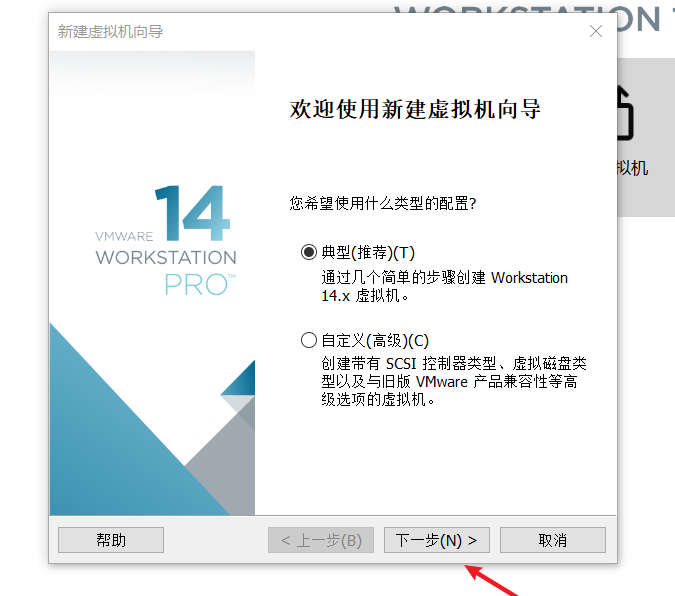
弹出以下窗口 选择 稍后安装操作系统----下一步:
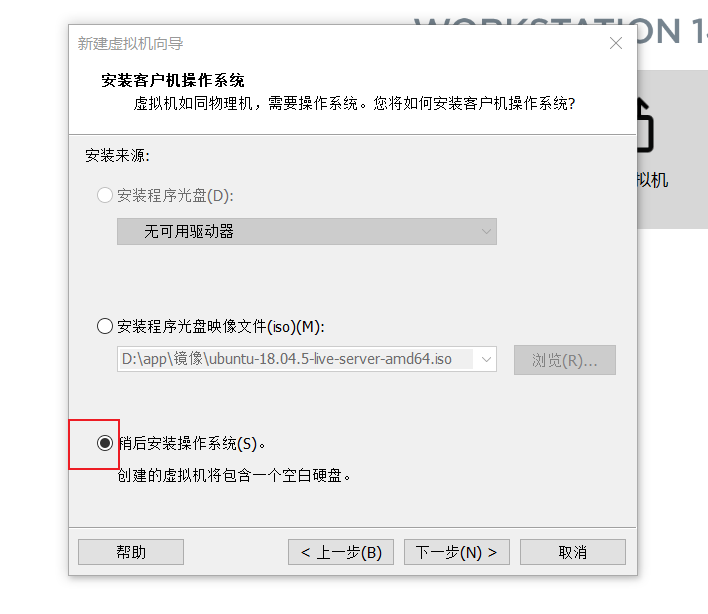
选择需要安装的操作系统----下一步:
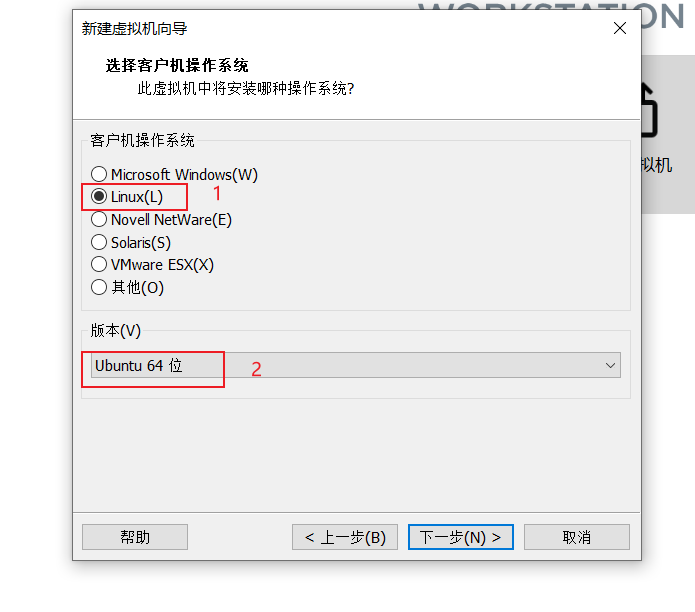
这里设置虚拟机的名字和要安装的位置----下一步:
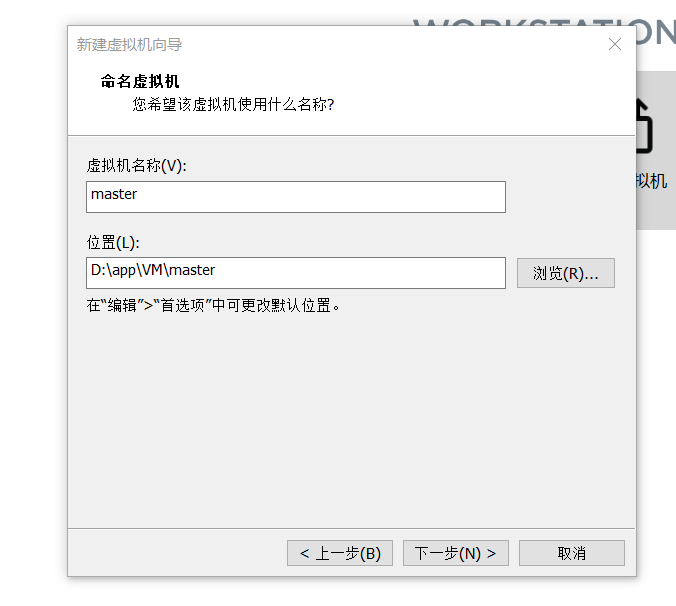
设置磁盘容量----下一步:
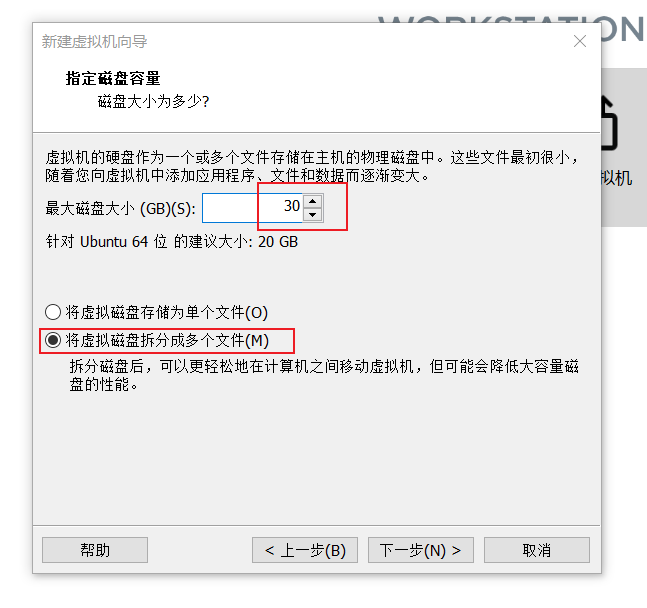
这里先不要点击完成选择自定义硬件

这里指定自己ISO镜像的位置----关闭

点击完成

可以看到VMware下生成了一个名为master的虚拟机----点击开启此虚拟机。
现在虚拟机还不能使用,现在就相当于一个没有安装操作系统的空电脑,只有躯体没有灵魂
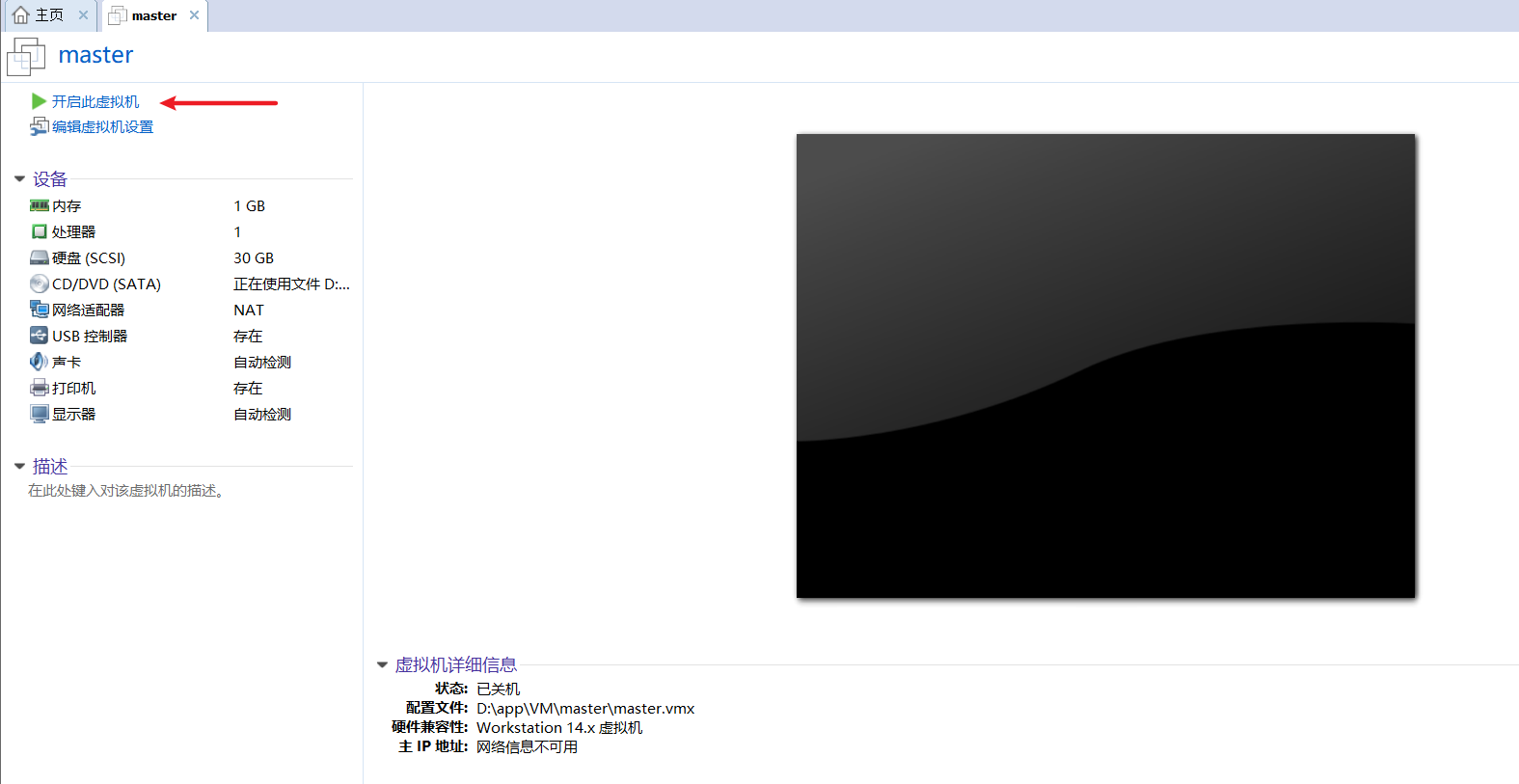
点开之后会一阵加载文件,等一会会出现下面界面:
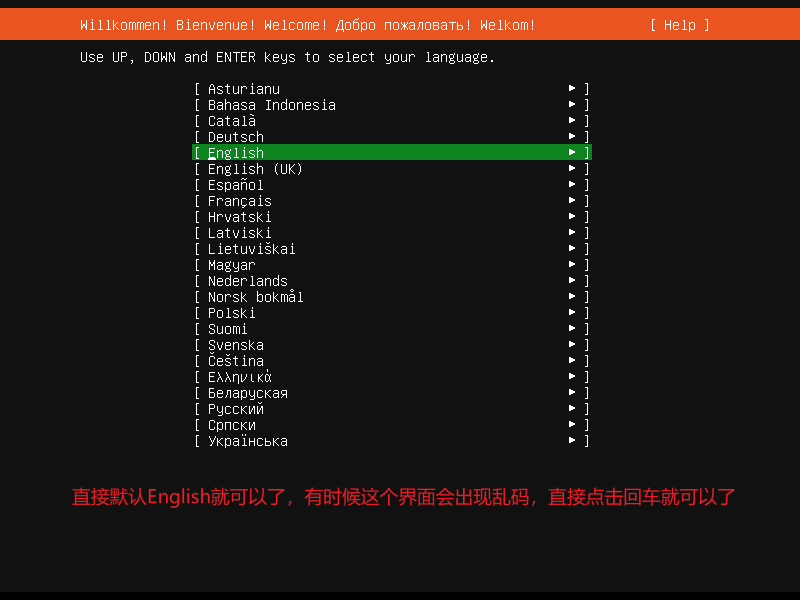
这里选择继续而不更新----摁回车

这里是设置键盘默认就可以了----摁回车
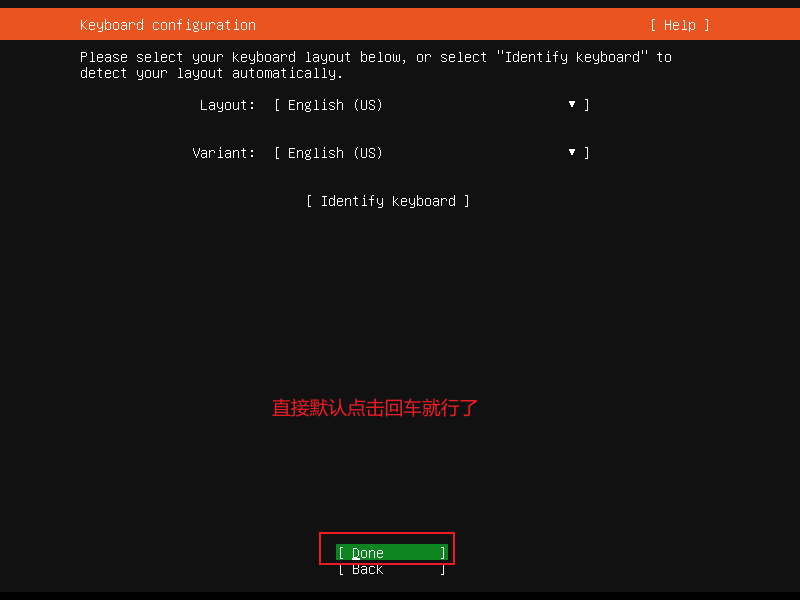
这里也是直接默认就可以了----摁回车
这里是设置代理服务器的,不用填写直接回车就可以了
设置下载源
选择Done直接回车就可以了
这里也是默认直接回车
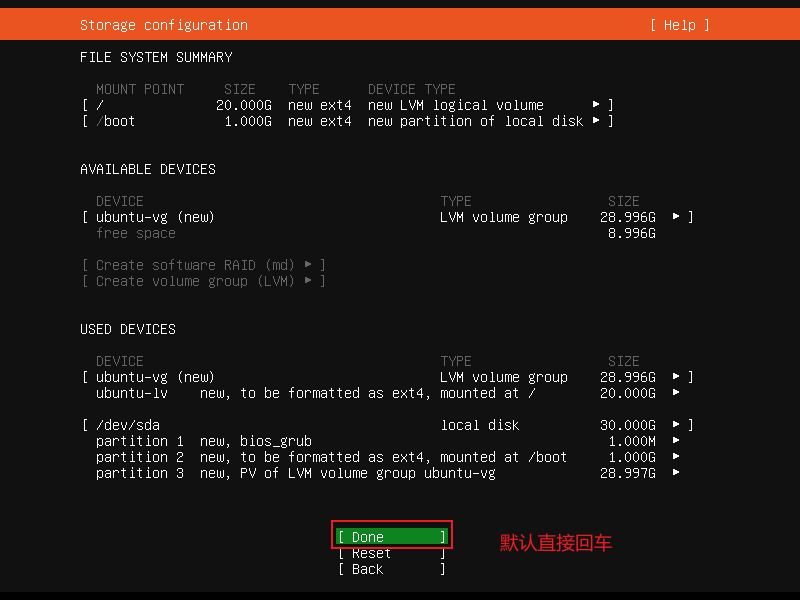
上一步回车之后会弹出一个对话框如下图:----选择Continue回车
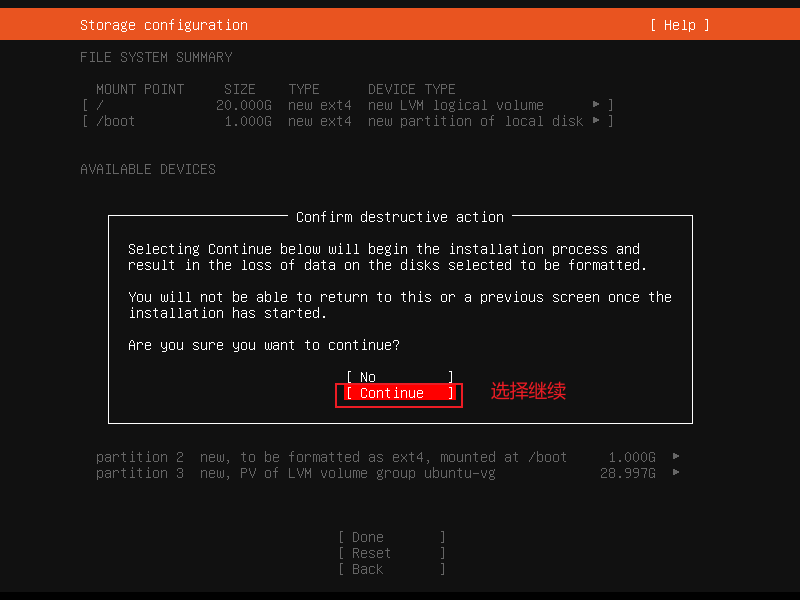
设置用户名和主机名设置完之后选在Done进行下一步
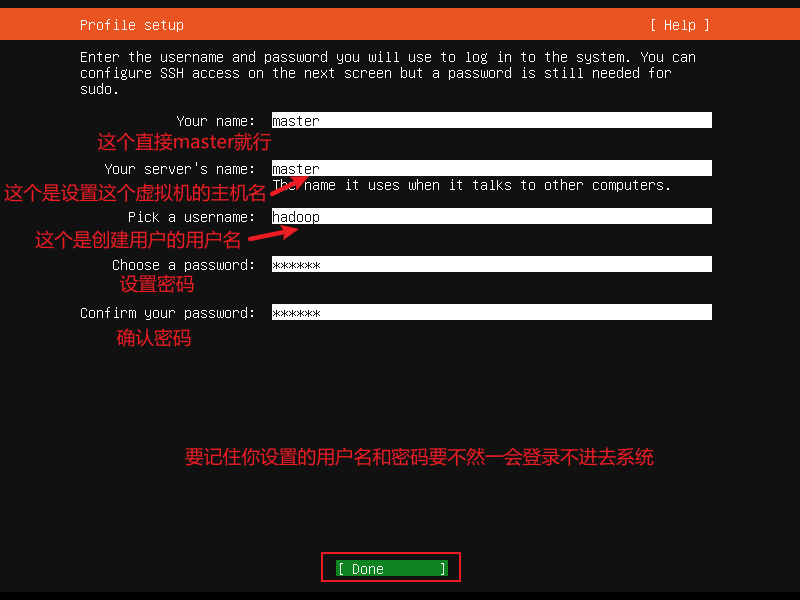
选择安装OpenSSH 服务
直接选择Done进行下一步
安装页面
更新包和重启虚拟机,选择完之后还要等一会

经过漫长的等待出现下面界面直接按回车继续执行
出现下面界面摁回车就可以
执行上一步的话会出现下面界面使用用户密码登录

使用用户名登陆上去就说明这台虚拟机已经可以工作了
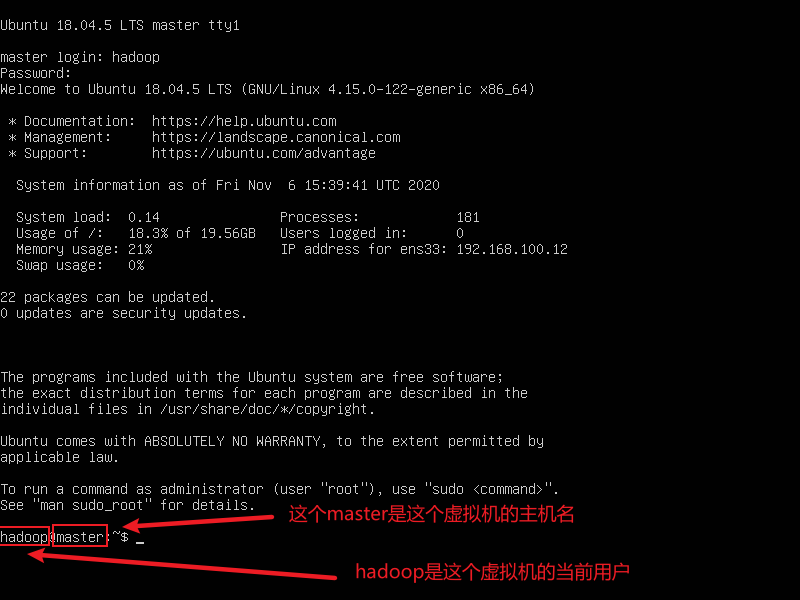
三、环境基础配置
| 节点 | IP地址 | 主机名 |
|---|---|---|
| master | 192.168.100.100 | master |
| slave1 | 192.168.100.101 | slave1 |
| slave2 | 192.168.100.102 | slave2 |
1.配置静态IP、hosts文件、克隆虚拟机、更改主机名
在配置静态IP之前要看一下VMware虚拟网卡的网段
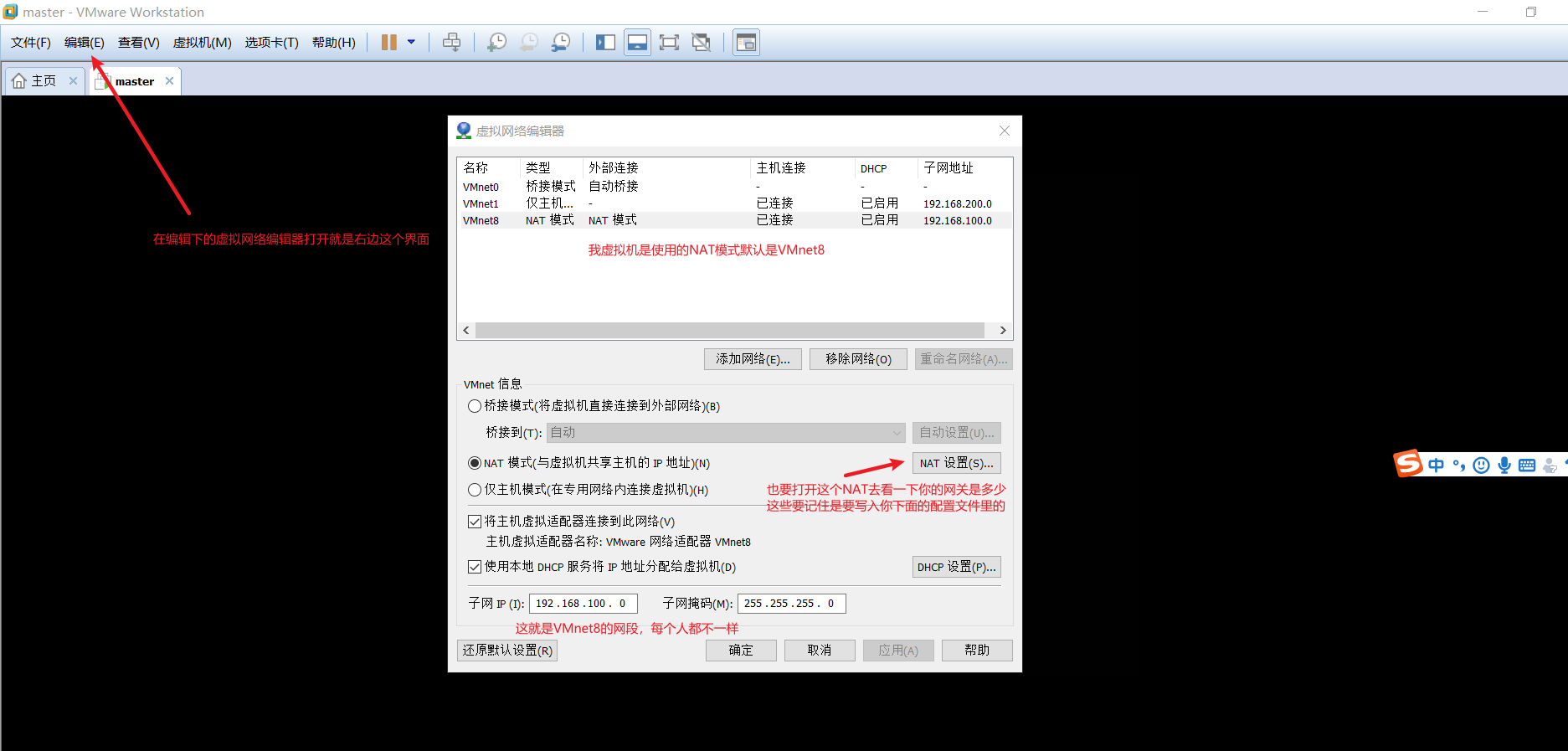
- 配置静态IP
cd /etc/netplan
ls

- 查看完配置文件,使用 vi 进入配置文件
sudo vi 00-installer-config.yaml
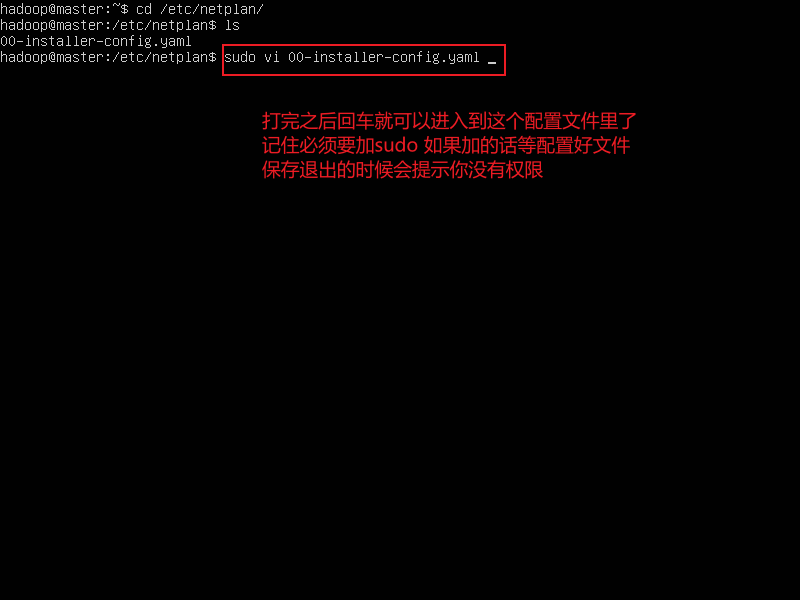
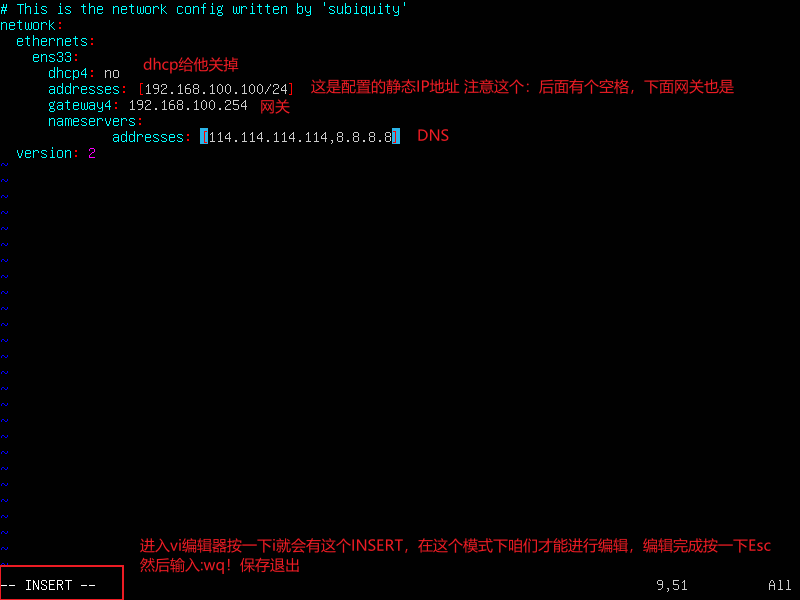
- 进行配置
vi 编辑器刚进入的时候默认是命令模式,要按一下 i 进入编辑模式。如果编辑完成想要退出,首先先按一下Esc到命令模式然后输如
:wq!
保存退出,如果不想保存退出就使用:q!命令。
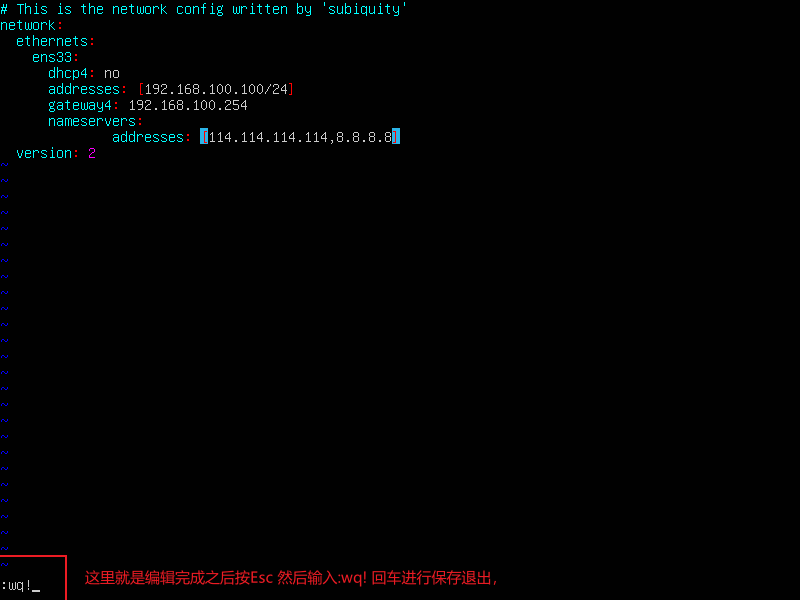
- 退出之后启动网卡
sudo netplan apply
ip a 查看IP的命令
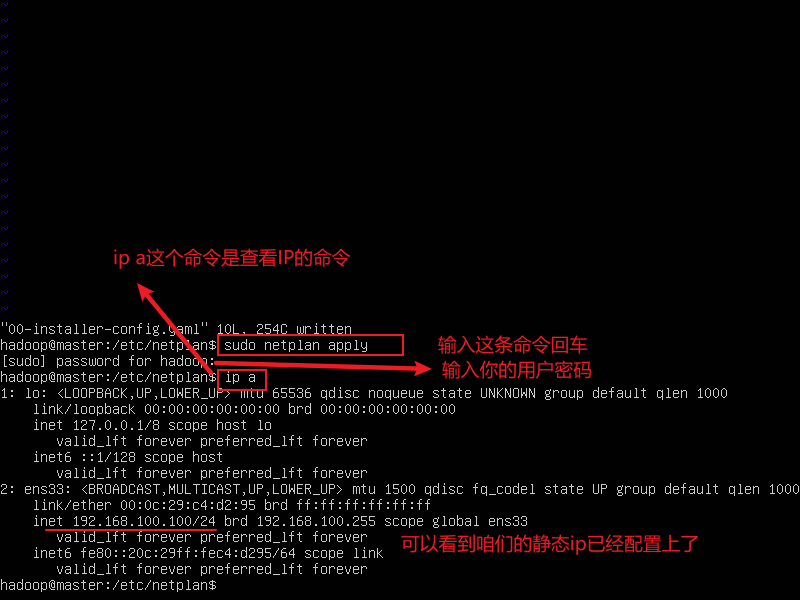
- 配置hosts文件
hosts文件是本地域名解析,一个本地的DNS。它将IP地址和主机名相互解析
也是使用vi 编辑器进行编辑
vi /etc/hosts
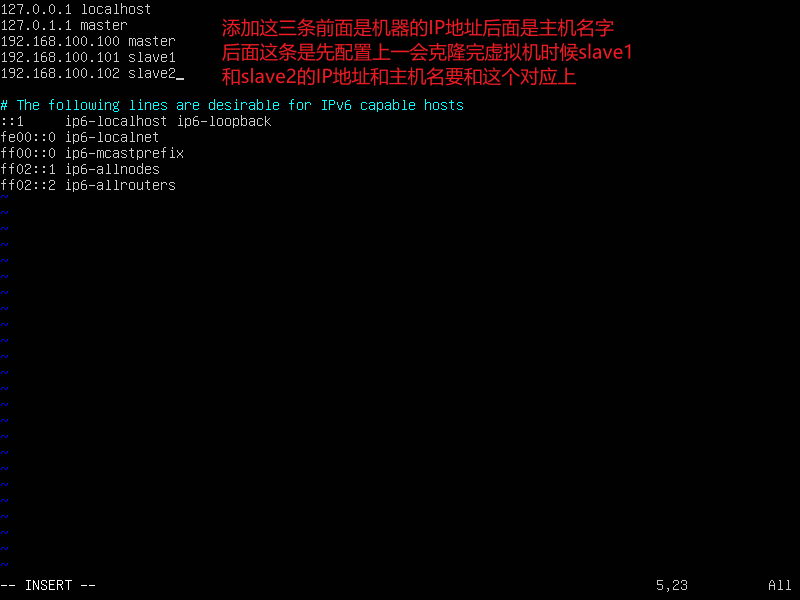
- 克隆虚拟机
先关闭master虚拟机然后点击虚拟机-----管理----克隆----下一步----下一步----选择创建完全克隆----下一步----更改虚拟机名称为slave1,位置自己选择即可。点击完成。即可看到VMware里多了一台名为slave1的虚拟机。slave2操作相同,就是虚拟机名称改为slave2即可。创建完如下图:

- 配置slave1和slave2
注意此时slave1和slave2虚拟机是克隆的,所以说配置文件和master是完全相同的,登录的话也是master的用户和密码(用户:hadoop 密码:你自己设置的)登录上咱们要给他更改一下主机名和IP地址。打开slave1、slave2虚拟机进行以下操作:
对slave1虚拟机进行操作的命令,操作的时候会让你输入密码
就输入hadoop用户的密码
hostnamectl set-hostname slave1 这个命令是永久更改主机名
sudo login 执行完这个命令会让你重新登录以下直接hadoop用户登录
对slave2虚拟机进行相同操作
hostnamectl set-hostname slave2 注意这里是slave2
sudo login
更改slave1的IP地址
vi /etc/netplan/00-installer-config.yaml
sudo netplan apply 配置完启动一下网络服务
ip a 查看一下是否配置成功
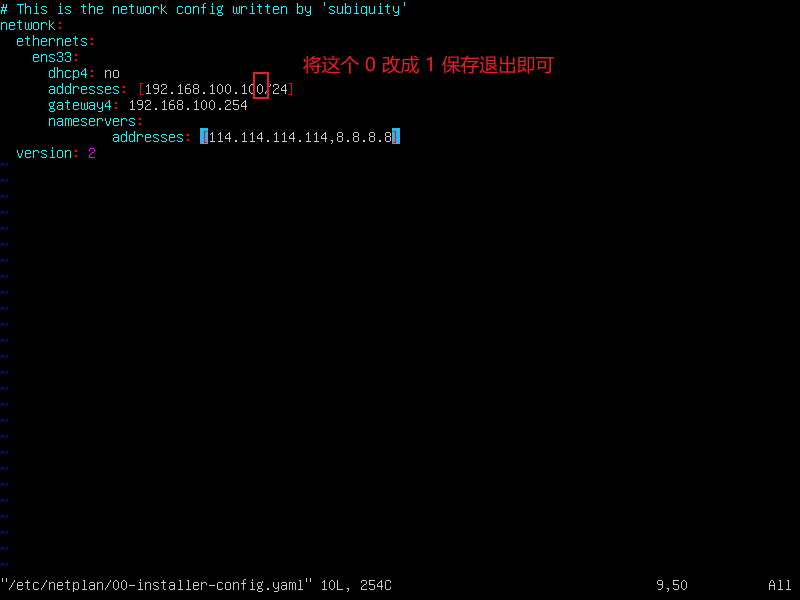
- 更改slave2的IP地址
操作跟slave1命令一样,把 0 改成 2 保存退出即可,也要使用
sudo netplan apply
命令启动一下网络服务。使用ip a查看一下是否配置成功
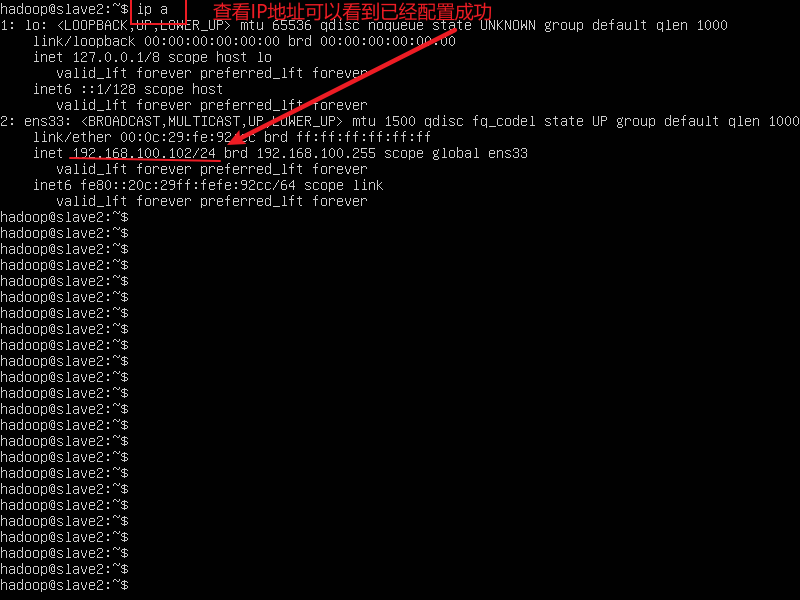
2.配置ssh免密登录
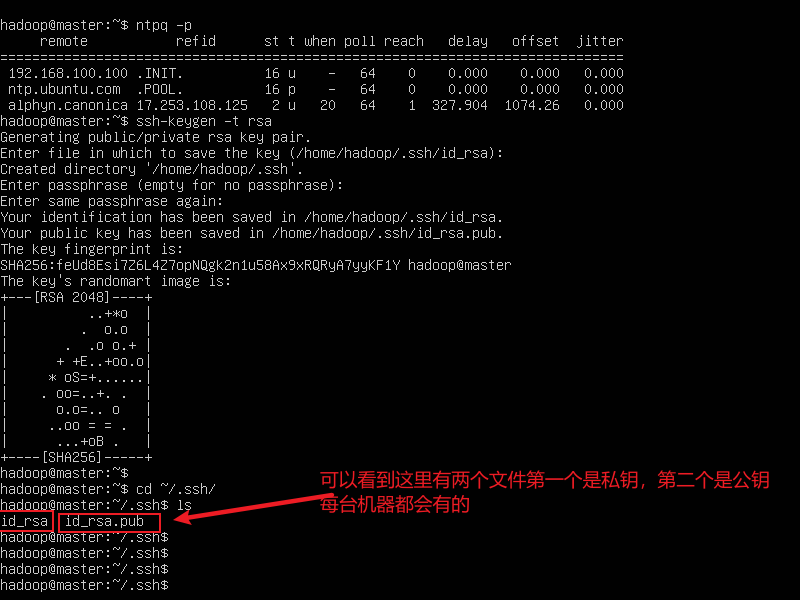
ssh-keygen -t rsa 每台机器都要执行这个命令,一路回车就可以了
- 执行完上面的命令,会发现用户目录下有一个
.ssh的目录,使用下面的命令查看一下
cd ~/.ssh/
ls
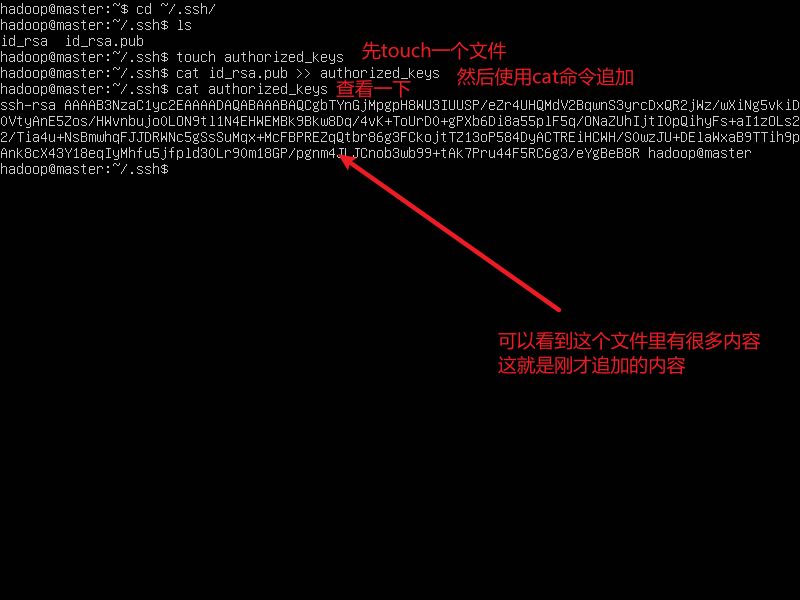
现在在master节点touch一个名为authorized_keys的文件然后使用cat命令将master的公钥追加到这个文件里。命令如下:
touch authorized_keys
cat id_rsa.pub >> authorized_keys
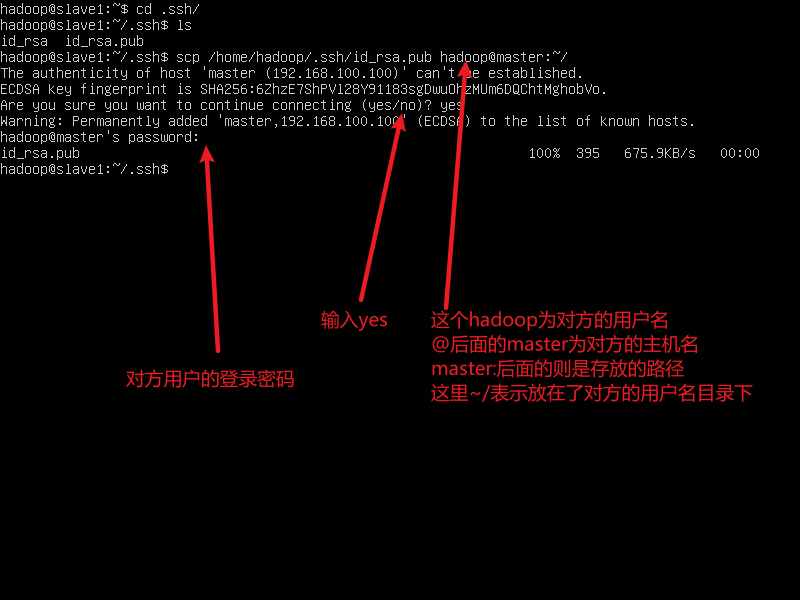
然后将slave1的公钥使用
scp命令复制到master节点上
scp ~/.ssh/id_rsa.pub hadoop@msater:~/
可以看到master节点用户命令下多了一个id_rsa_pub的文件
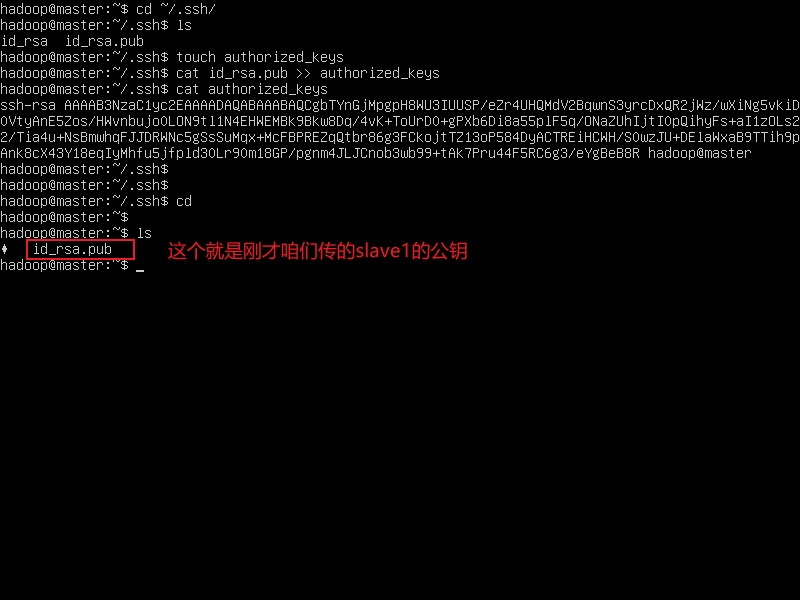
同样使用
cat命令将slave1的公钥追加到authorized_keys文件里
cat id_rsa_pub >> .ssh/authorized_keys
cat .ssh/authorized_keys
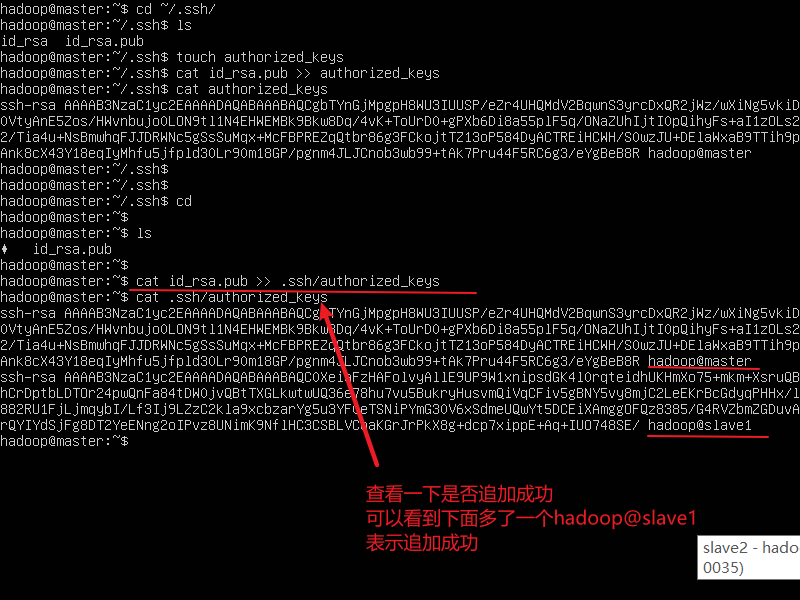
使用相同的命令将slave2的公钥传到master节点里并写入authorized_keys文件里
scp /home/hadoop/.ssh/id_rsa.pub hadoop@master:~/ 在slave2里执行
(这里说明一下执行完上面这个命令会把之前咱们传的slave1的公钥文件覆盖掉,没什么影响。在master节点里执行下面的命令)
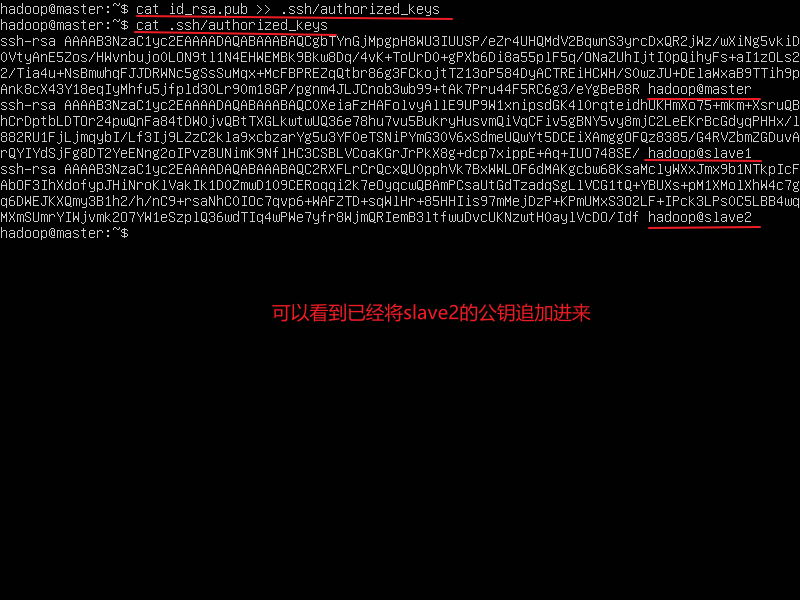
cat id_rsa_pub >> .ssh/authorized_keys
cat .ssh/authorized_keys
然后使用scp命令将master节点里的authorized_keys文件分别上传到slave1和slave2节点的.ssh/目录下
scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:~/.ssh/
scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:~/.ssh/
- 验证ssh免密登录
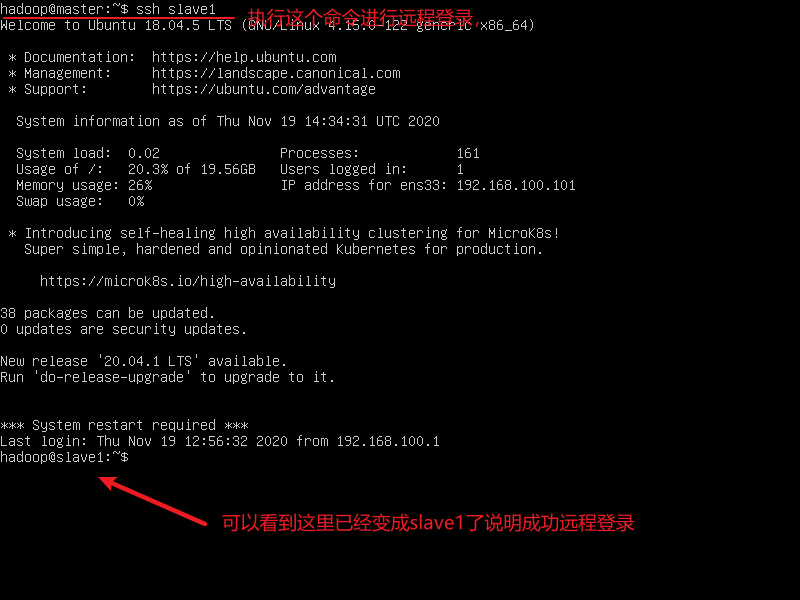
ssh slave1 远程登录slave1命令,如果想登录其他节点,将slave1改成其他主机的主机名即可
exit 这个是退出命令
3.上传并解压JDK、Hadoop压缩包
- 使用Xftp软件进行上传
注意:使用Xftp之前要确保宿主机(就是自己的电脑)和虚拟机相互通信。
- 点击【连接】会出现下面界面
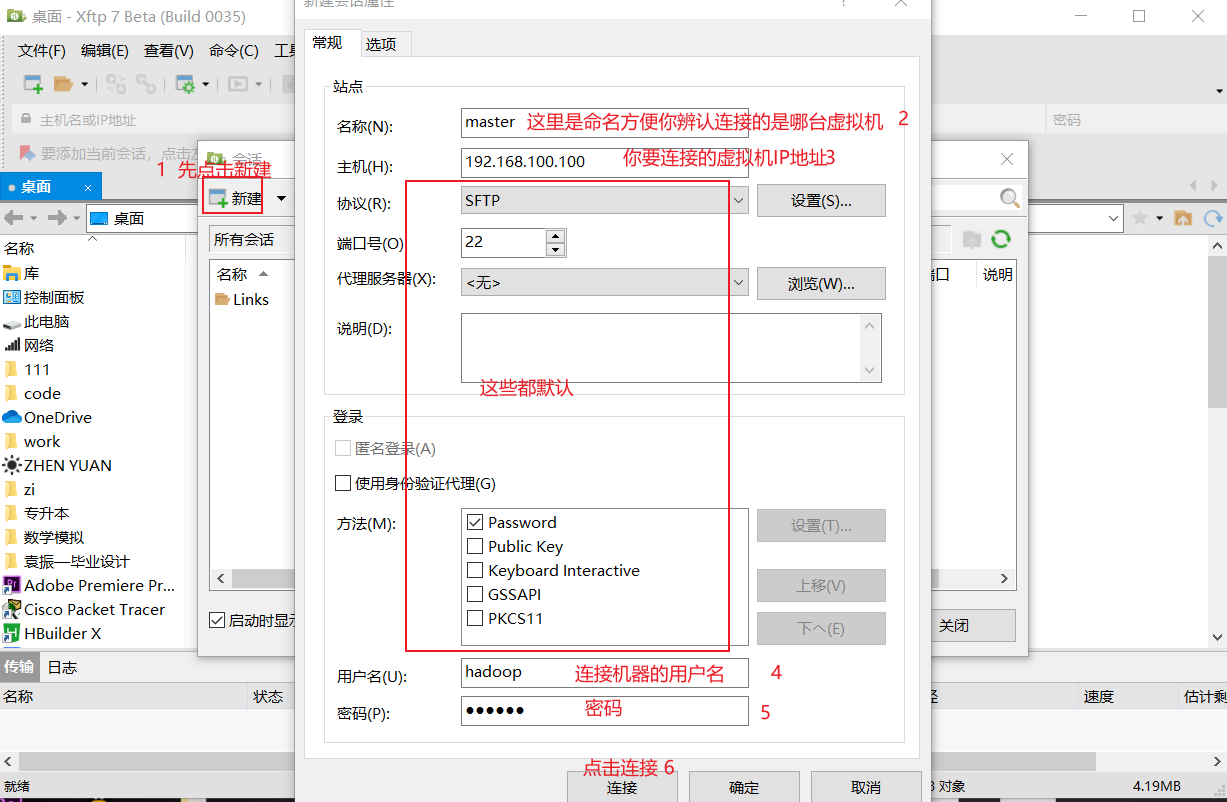
出现下面界面,咱们可以直接把左面电脑里的文件拖到右面的虚拟机里。当然虚拟机里的文件也可以直接拖到自己电脑里。
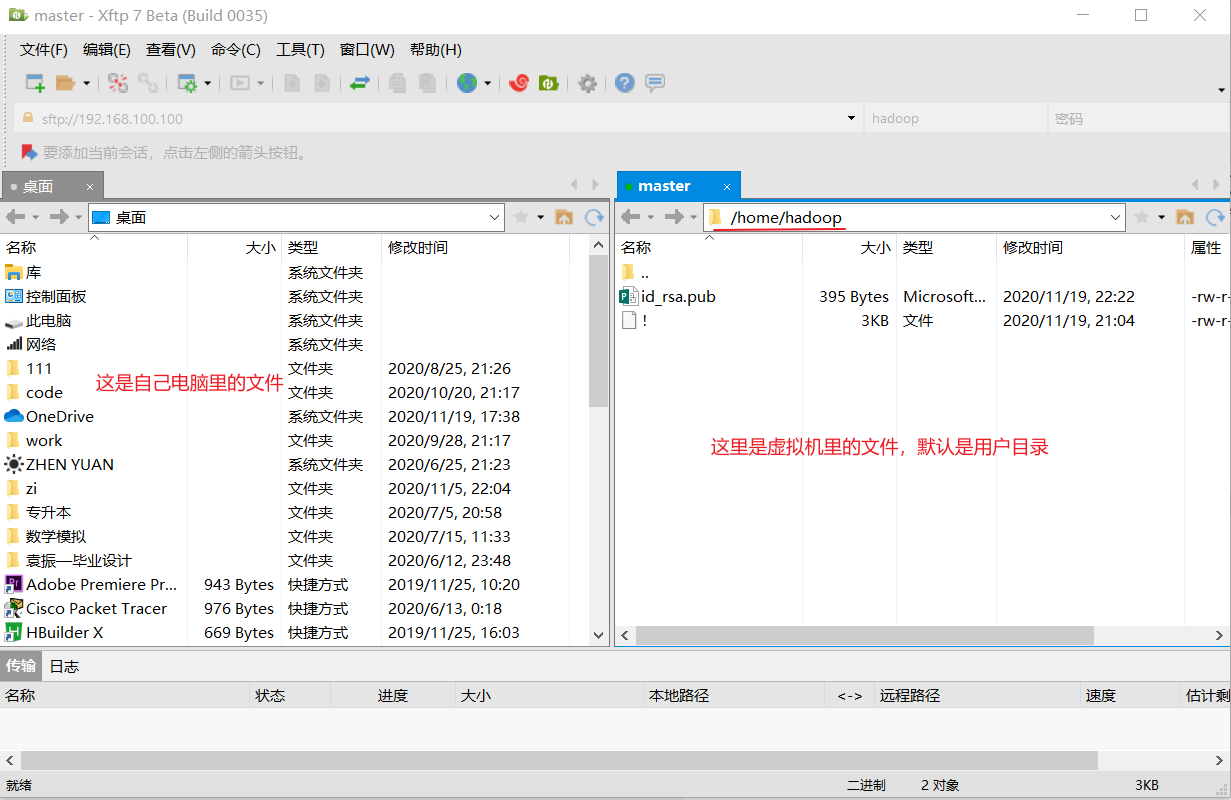
将hadoop、jdk压缩文件拖到虚拟机里

也可以到master用户目录下查看
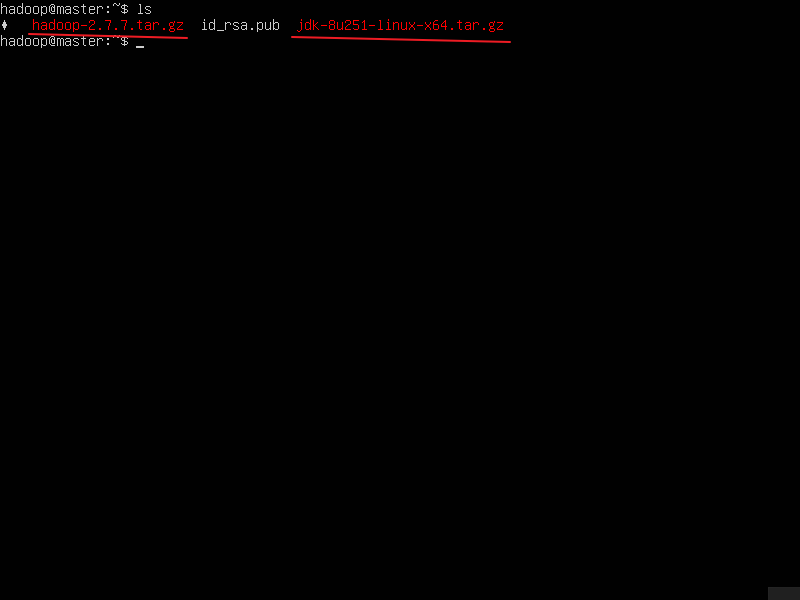
解压hadoop、jdk
sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/ -C参数是指定解压到哪个目录下
sudo tar -zxvf jdk-8u251-linux-x64.tar.gz -C /usr/local/
cd /usr/local/ 到这个目录下
ls 查看一下

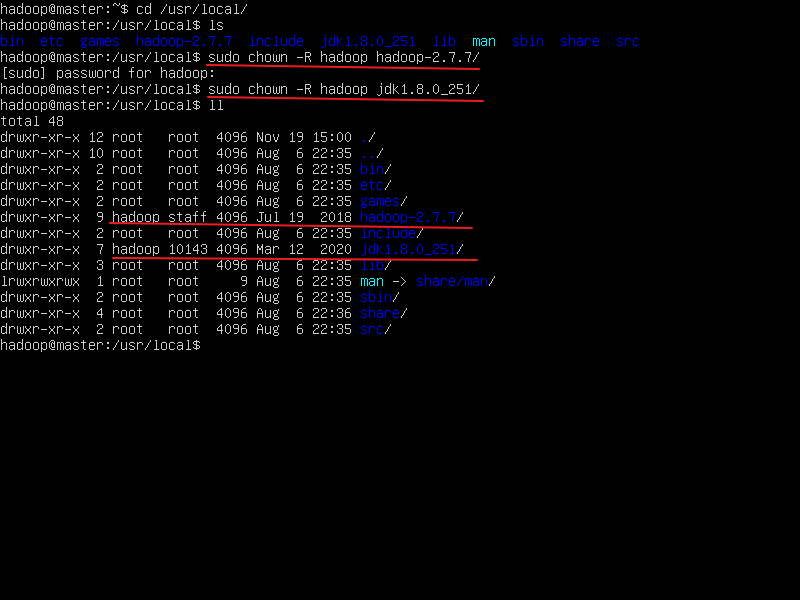
- 给这两个权限,归hadoop用户所有
sudo chown -R hadoop hadoop-2.7.7/
sudo chown -R hadoop jdk1.8.0_251
ll 查看一下
4.添加环境变量
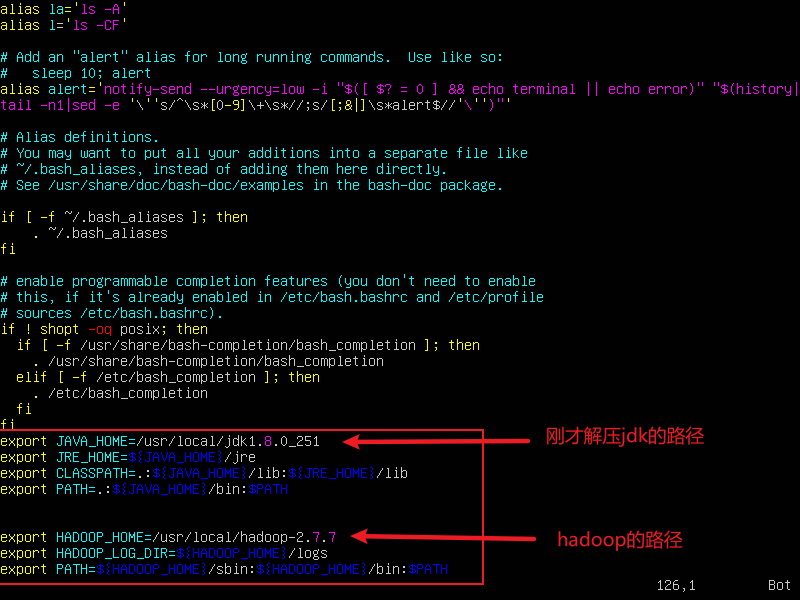
vi .bashrc 在这个文件最后添加如下内容,三台机器都需要添加。
source .bashrc 添加完成之后执行这个条命令,让其生效。
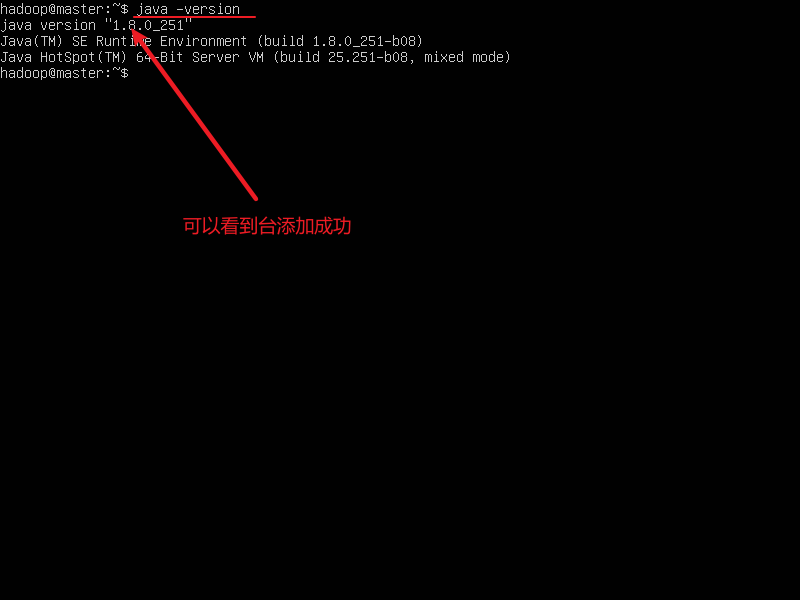
- 验证一下是否添加成功
java -version
四、配置Hadoop文件
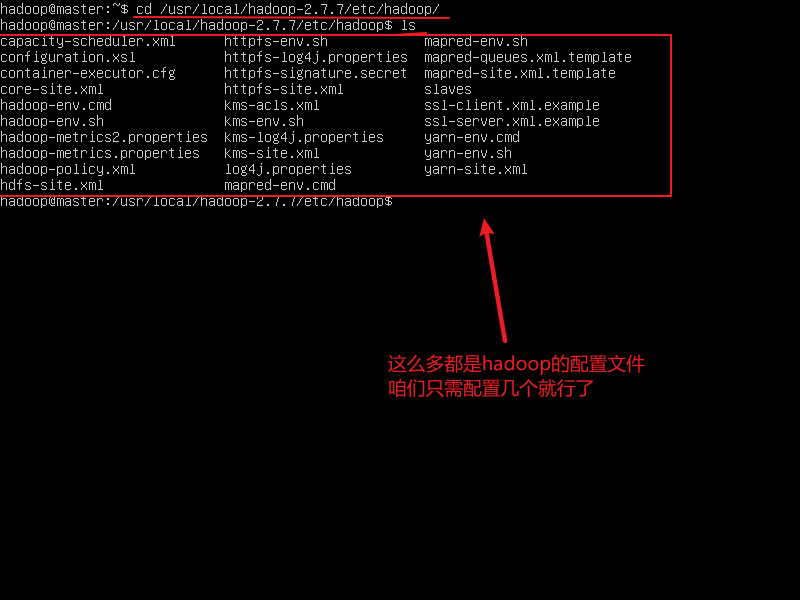
- 首先进入存放Hadoop配置文件的目录
cd /usr/local/hadoop-2.7.7/etc/hadoop/ 进入此目录
ls 查看一下
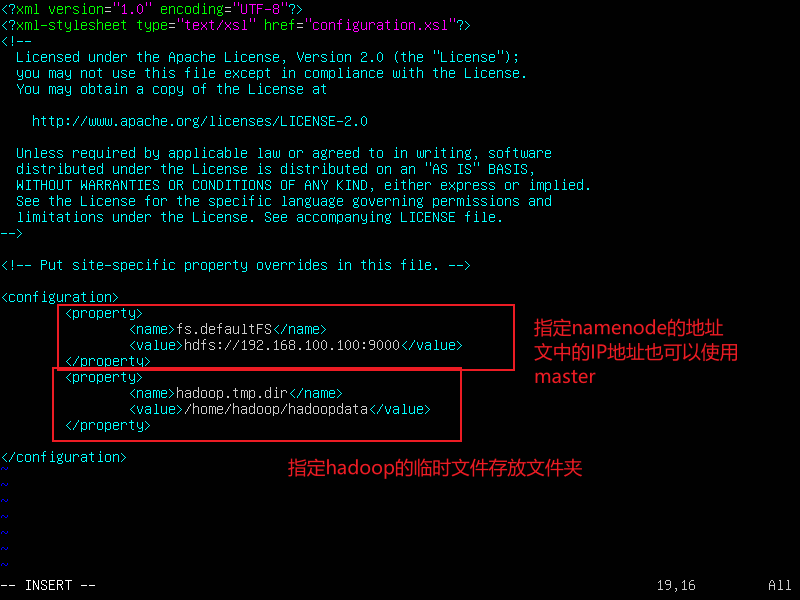
1.配置核心组件core-site.xml
vi core-site.xml 打开文件,添加以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.100.100:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopdata</value>
</property>
2.配置hadoop-env.sh
vi hadoop-env.sh 添加JDK的安装目录
export JAVA_HOME=/usr/local/jdk1.8.0_251

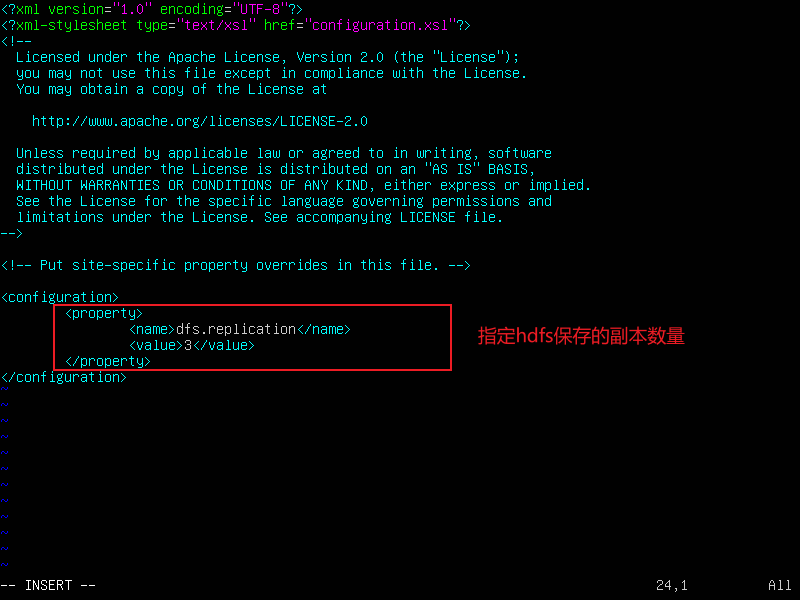
3.配置hdfs-site.xml
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
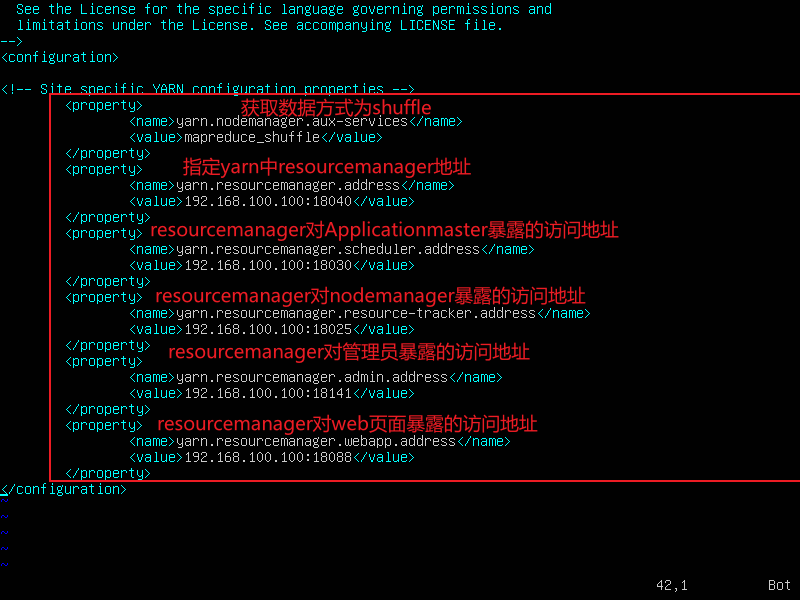
4.配置yarn-site.xml
vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.100.100:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.100.100:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.100.100:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.100.100:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.100.100:18088</value>
</property>
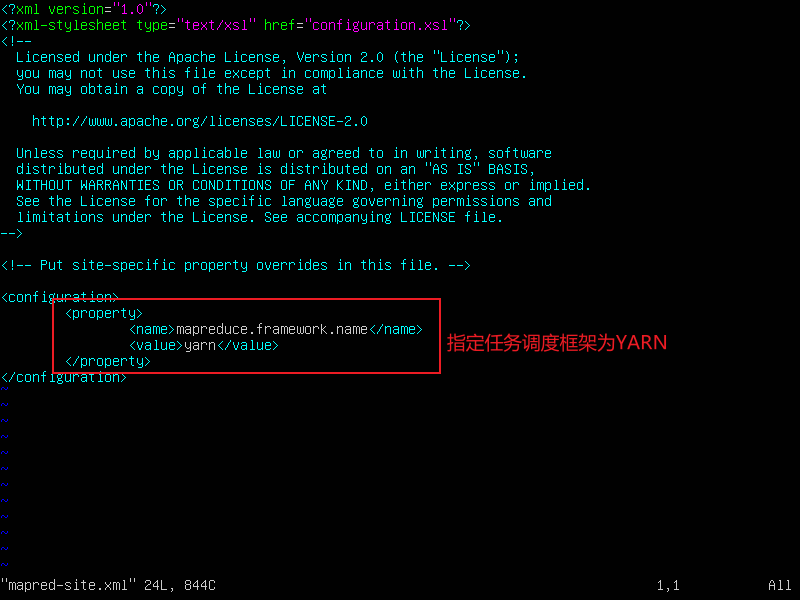
5.配置mapred-site.xml
使用cp命令复制mapred-site.xml.template文件为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml 使用cp命令进行复制
vi mapred-site.xml 添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
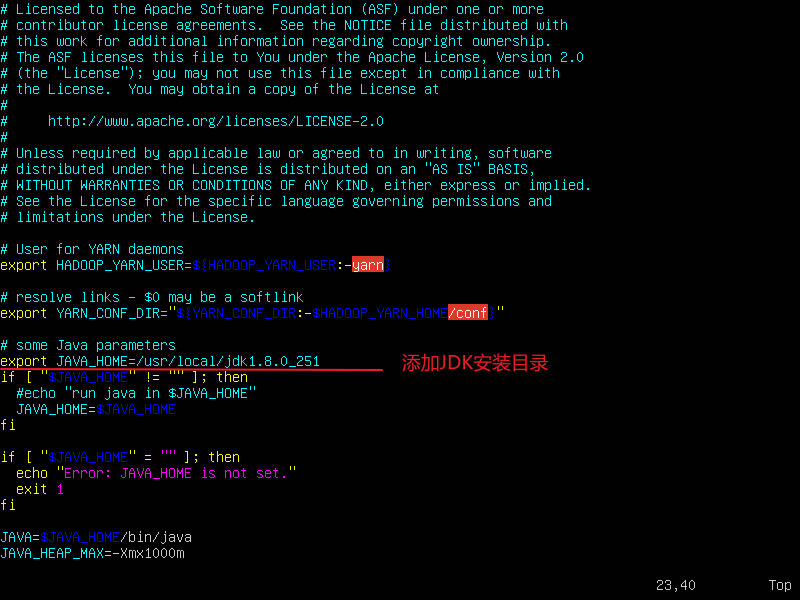
6.配置yarn-env.sh
vi yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_251
五、复制文件
1.使用scp命令将hadoop、jdk文件复制到slave1和slave2节点上。
在master节点执行下面命令
sudo scp -r /usr/local/hadoop-2.7.7 hadoop@slave1:~/
sudo scp -r /usr/local/hadoop-2.7.7 hadoop@slave2:~/
sudo scp -r /usr/local/jdk1.8.0_251 hadoop@slave1:~/
sudo scp -r /usr/local/jdk1.8.0_251 hadoop@slave2:~/
此时已经将这两个文件复制到slave1、slave2节点的用户目录下
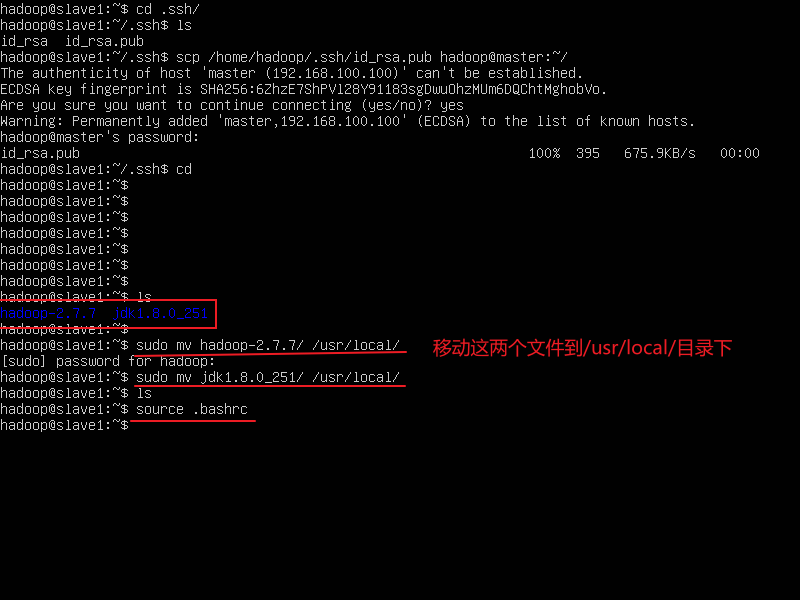
2.移动文件
在slave1、slave2节点执行下面命令
sudo mv /home/hadoop/hadoop-2.7.7/ /usr/local/
sudo mv /home/hadoop/jdk1.8.0_251/ /usr/local/
source .bashrc 生效一下环境变量,每台节点都要执行。
六、启动集群
1.在master节点格式化namenode
hdfs namenode -format 进行格式化
2.start-all.sh启动集群
start-all.sh
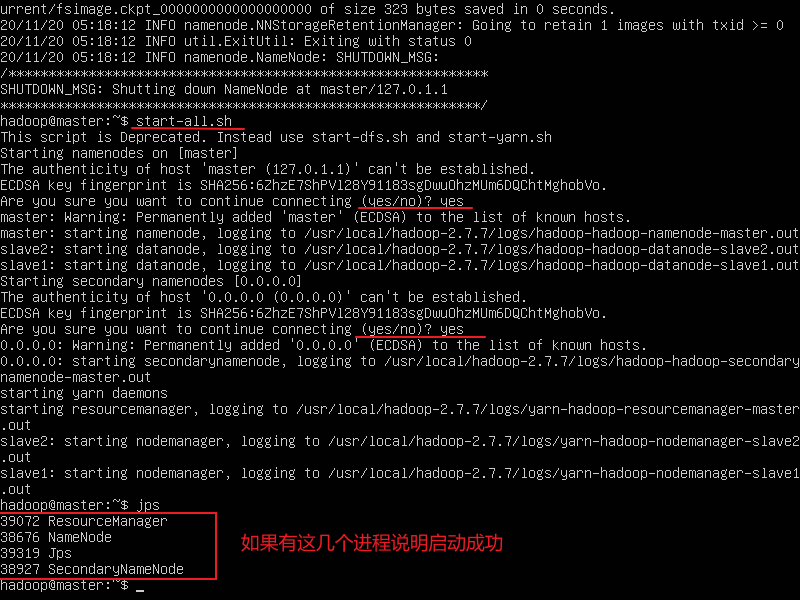
查看slave1节点的进程

查看slave2节点的进程

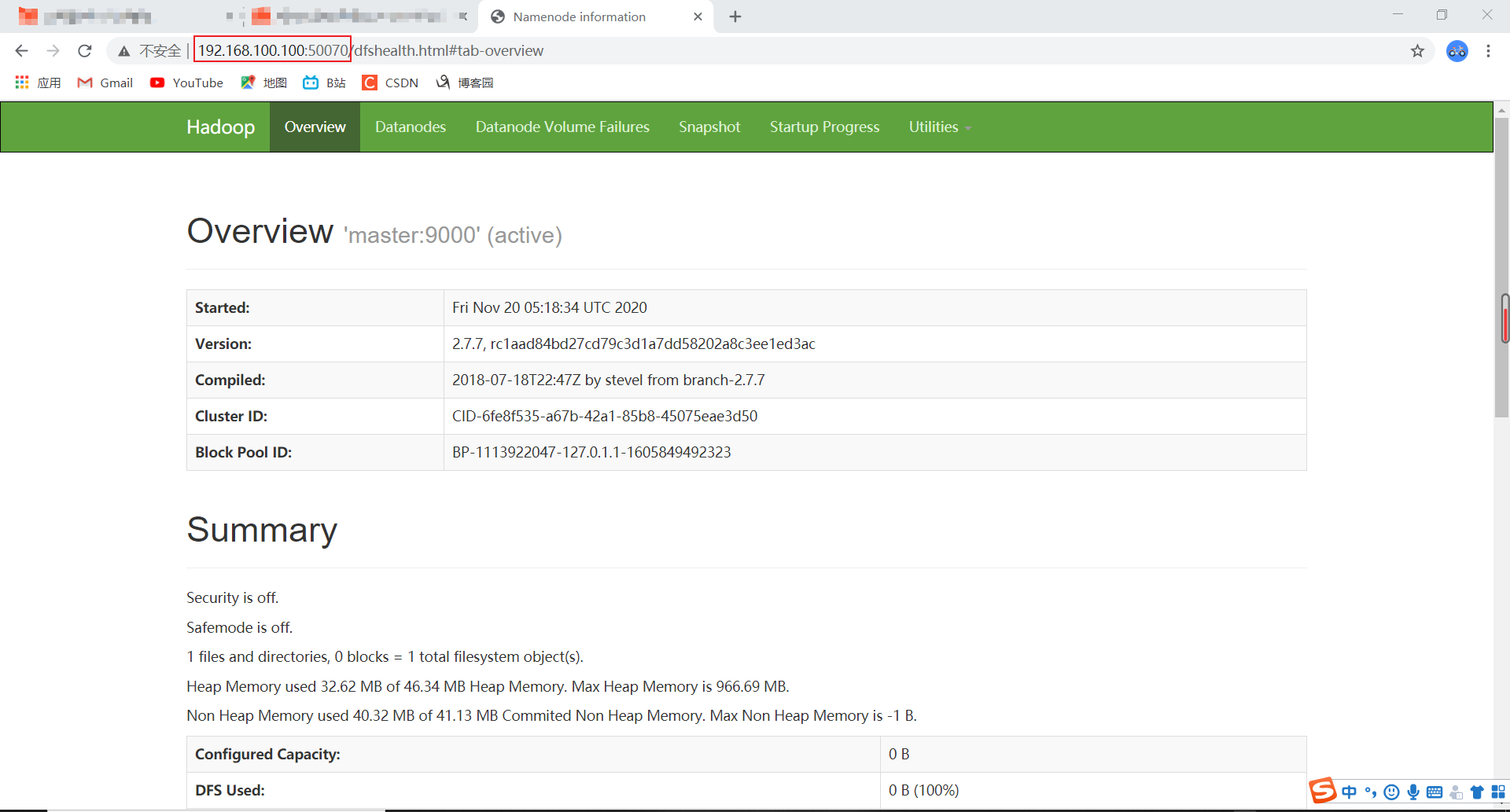
3.通过浏览器访问UI 集群信息图
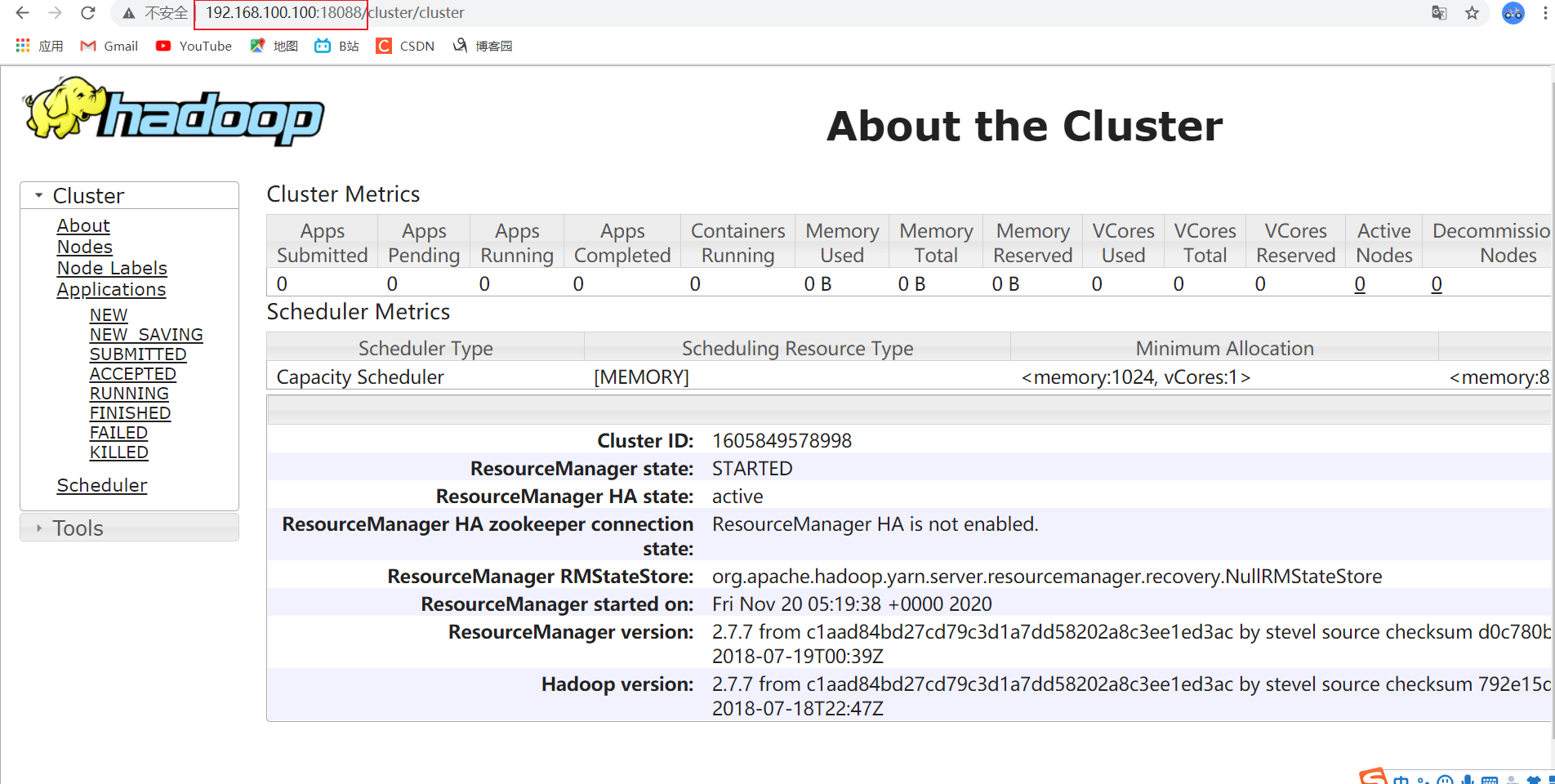
4.通过浏览器访问Yarn web 信息图
至此Hadoop完全分布式搭建完成
超级无敌详细使用ubuntu搭建hadoop完全分布式集群的更多相关文章
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- VM+CentOS+hadoop2.7搭建hadoop完全分布式集群
写在前边的话: 最近找了一个云计算开发的工作,本以为来了会直接做一些敲代码,处理数据的活,没想到师父给了我一个课题“基于质量数据的大数据分析”,那么问题来了首先要做的就是搭建这样一个平台,毫无疑问,底 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- hadoop完全分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 准备三台虚拟机master,slave01,slave02 hado ...
随机推荐
- docker19.03搭建私有容器仓库
一,启动docker后,搜索registry [root@localhost source]# systemctl start docker [root@localhost source]# dock ...
- PHP SPL标准库-迭代器
通过某种统一的方式遍历链表或者数组中的元素的过程叫做迭代遍历,这种统一的遍历工具我们叫做迭代器. PHP中迭代器是通过Iterator 接口定义的. ArrayIterator迭代器 foreach ...
- Dijkstra算法 python实现
1.Dijkstra算法的基本实现 \(O(n^2)\) 简介: Dijkstra算法是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题.迪杰斯特拉算法主要特点是从起始点开始,采用贪 ...
- SELECT INTO与INSERT INTO SELECT用法
SELECT INTO SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中: -- 创建 Websites 的备份,这种写法没走索引导致全表扫描 SELECT * INTO W ...
- cgdb安装
cgdb官网:http://cgdb.github.io/ 一.cgdb安装 可使用wget命令下载,wget http://cgdb.me/files/cgdb-0.7.0.tar.gz 之后解压 ...
- 第三章 MySQL的多实例
一.MySQL服务构成 1.MySQL程序结构 1.连接层 2.sql层 3.存储引擎层 2.MySQL逻辑结构 1.库 2.表:元数据+真实数据行 3.元数据:列+其它属性(行数+占用空间大小+权限 ...
- Solr入门-Solr服务安装(windows系统)
安装Solr 首先保证已经正确安装了Java 下载Solr,当前最新版6.1.0 Solr各个版本下载地址 Solr从6.0之后需要Java1.8所以如果使用Solr6.0及其以上版本,请确保Java ...
- 走在深夜的小码农 Third Day
Css3 Third Day writer:late at night codepeasant css简介 CSS 是层叠样式表 ( Cascading Style Sheets ) 的简称. ...
- Luogu P3757 [CQOI2017]老C的键盘
题目描述 老C的键盘 题解 显然对于每个数 x 都有唯一对应的 \(x/2\) , 然而对于每个数 x 却可以成为 \(x*2\) 和 \(x*2+1\) 的对应数 根据这一特性想到了啥??? 感谢l ...
- Polyglot Translators: Let's do i18n easier! 一款国际化插件小助手!
在做国际化文本有关的工作时, 是否厌倦了在不同应用或者网页之间频繁地切换进行中文, 繁体, 英文甚至韩文日文的文本翻译工作? 好吧, 我就是受不了频繁在进行文本字符串的转换, 还得跑到百度翻译上面搜索 ...