Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
- 上一篇介绍了利用CookieJar访问人人网,本篇将使用filecookiejar将cookie以文件形式保存
- 自动使用cookie登录,使用步骤:
- 1.打开登录页面后,通过用户名密码登录
- 2.自动提取反馈回来的cookie
- 3.利用提取的cookie登录个人信息页面
- 创建cookiejar实例
- 生成cookie的管理器
- 创建http请求管理器
- 创建https请求的管理器
- 创建请求管理器
- 通过输入用户名和密码,获取cookie
- 代码:
# 创建cookiejar的实例
cookie = cookiejar.CookieJar()
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
创建handle后,使用opener打开,打开后相应的业务由相应的handle处理
cookie作为一个变量打印出来
- 案例v14cookie4文件:https://xpwi.github.io/py/py爬虫/py14cookie4.py
# 使用cookiejar
# cookie作为一个变量打印出来
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
cookie = cookiejar.CookieJar()
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
# 负责首次登录,输入用户名和密码,用来获取cookie
url = 'http://www.renren.com/PLogin.do'
id = input('请输入用户名:')
pw = input('请输入密码:')
data = {
# 参数使用正确的用户名密码
"email": id,
"password": pw
}
# 把数据进行编码
data = parse.urlencode(data)
# 创建一个请求对象
req = request.Request(url,data=data.encode('utf-8'))
# 使用opener发起请求
rsp = opener.open(req)
# 以上代码就可以进一步获取cookie了,cookie在哪呢?cookie在opener里
def getHomePage():
# 地址是用在浏览器登录后的个人信息页地址
url = "http://www.renren.com/967487029/profile"
# 如果已经执行login函数,则opener自动已经包含cookie
rsp = opener.open(url)
html = rsp.read().decode()
with open("rsp1.html", "w", encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
if __name__ == '__main__':
login()
# 执行完login之后,会得到授权之后的cookie,下一步打印出来
print(cookie)
for item in cookie:
print(type(item))
print(item)
for i in dir(item):
print(i)
我们使用print(i)打印出来了cookie的所有属性
下面介绍常用的属性
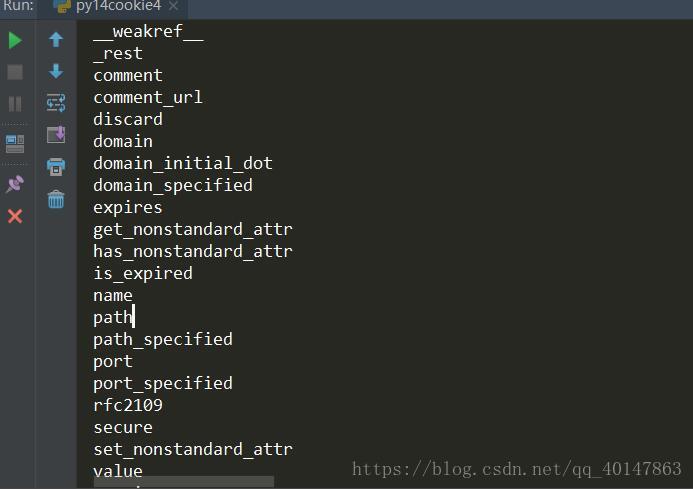
cookie的属性
- name:名称
- value:值
- domain:可以访问此cookie的域名
- path:可以访问此cookie的页面路径
- expires:过期时间
- size:大小
- http:字段
cookie的值虽然可以自己修改,但是修改后就会导致和服务器端数据不一致,而使cookie无效,最终登录失败
cookie的保存-FileCookieJar
- 将cookie以文件形式保存
- 案例v15filecookiejar文件:https://xpwi.github.io/py/py爬虫/py15filecookiejar.py
# 使用filecookiejar
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
filename = "py15renrenCookie.txt"
cookie = cookiejar.MozillaCookieJar(filename)
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
# 负责首次登录,输入用户名和密码,用来获取cookie
url = 'http://www.renren.com/PLogin.do'
id = input('请输入用户名:')
pw = input('请输入密码:')
data = {
# 参数使用正确的用户名密码
"email": id,
"password": pw
}
# 把数据进行编码
data = parse.urlencode(data)
# 创建一个请求对象
req = request.Request(url,data=data.encode('utf-8'))
# 使用opener发起请求
rsp = opener.open(req)
'''
保存cookie到文件
两个参数:
ignore_discard:表示及时cookie将要被丢弃,是否保存下来
ignore_expires:表示如果该文件中cookie已经过期,是否保存下来
'''
cookie.save(ignore_discard=True, ignore_expires=True)
if __name__ == '__main__':
login()
运行结果
本篇使用filecookiejar将cookie以文件形式保存
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)的更多相关文章
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python 基础教程 —— 网络爬虫入门篇
前言 Python 是一种解释型.面向对象.动态数据类型的高级程序设计语言,它由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年.自面世以后,Pytho ...
- Python 简明教程 --- 14,Python 数据结构进阶
微信公众号:码农充电站pro 个人主页:https://codeshellme.github.io 如果你发现特殊情况太多,那很可能是用错算法了. -- Carig Zerouni 目录 前几节我们介 ...
- Python爬虫教程-05-python爬虫实现百度翻译
使用python爬虫实现百度翻译功能 python爬虫实现百度翻译: python解释器[模拟浏览器],发送[post请求],传入待[翻译的内容]作为参数,获取[百度翻译的结果] 通过开发者工具,获取 ...
- 大爽Python入门教程 1-4 习题
大爽Python入门公开课教案 点击查看教程总目录 1 [思考]方向变换 小明同学站在平原上,面朝北方,向左转51次之后(每次只转90度), 小明面朝哪里?小明转过了多少圈? (360度为一圈,圈数向 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- [转] vagrant学习笔记 - provision
[From] https://blog.csdn.net/54powerman/article/details/50684844 从字面上来看,provision是准备,实现的功能是在原生镜像的基础 ...
- 线程局部存储空间 pthread_key_t、__thread 即 ThreadLocal
https://www.jianshu.com/p/495ea7ce649b?utm_source=oschina-app 该博客还未学习完 还有 pthread_key_t Thread ...
- mysql故障总结
MYSQL故障排查 https://zhuanlan.zhihu.com/p/27834293
- Stirng,Stringbuffer,Stringbuild的区别浅淡
String 1,Stirng是对象不是基本数据类型 2,String是final类,不能被继承.是不可变对象,一旦创建,就不能修改它的值. 3,对于已经存在的Stirng对象,修改它的值,就是重新创 ...
- 数据结构与算法(C++)大纲
1.栈 栈的核心是LIFO(Last In First Out),即后进先出 出栈和入栈只会对栈顶进行操作,栈底永远为0 1.1概念 栈底(bottom):栈结构的首部 栈顶(top):栈结构的尾部 ...
- Java入门系列-16-继承
这一篇文章教给新手学会使用继承,及理解继承的概念.掌握访问修饰符.掌握 final 关键字的用法. 继承 为什么要使用继承 首先我们先看一下这两个类: public class Teacher { p ...
- 查询数据库的所有列信息 sys.all_columns
一.Database.sys.tables 为每个表对象返回一行,当前仅用于 sys.objects.type = U 的表对象. 列名 数据类型 说明 <继承的列> 有关此视图所继承 ...
- PHP学习8——图像处理
主要内容: 加载GD库 创建图像 绘制点,线,矩形,多边形,椭圆,弧线 绘制文字 通过GD库生成验证码 其实吧,学习图像方法的最大作用,好像就是为了制作验证码. 所以此专题,不如叫做制作验证码. 1. ...
- .Net高阶异常处理第二篇~~ dump进阶之MiniDumpWriter
dump文件相信有些朋友已经很熟悉了,dump文件的作用在于保存进程运行时的堆栈信息,方便日后排查软件故障,提升软件质量.关于dump分析工具windbg.adplus的文章更多了,如果您还不知道怎么 ...
- Java 并发(一) --- CAS
CAS 原理 先来看看下面的代码是否可以输出预期的值.开启了两个线程,是否会输出200 呢 结果由于并发的原因,结果会小于或等于200 , 原因出现在 count++; 由于这一行代码存在三个操作: ...