【爬虫案例】用Python爬取百度热搜榜数据!
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是:百度热搜榜
分别爬取每条热搜的:
热搜标题、热搜排名、热搜指数、描述、链接地址。
下面,对页面进行分析。
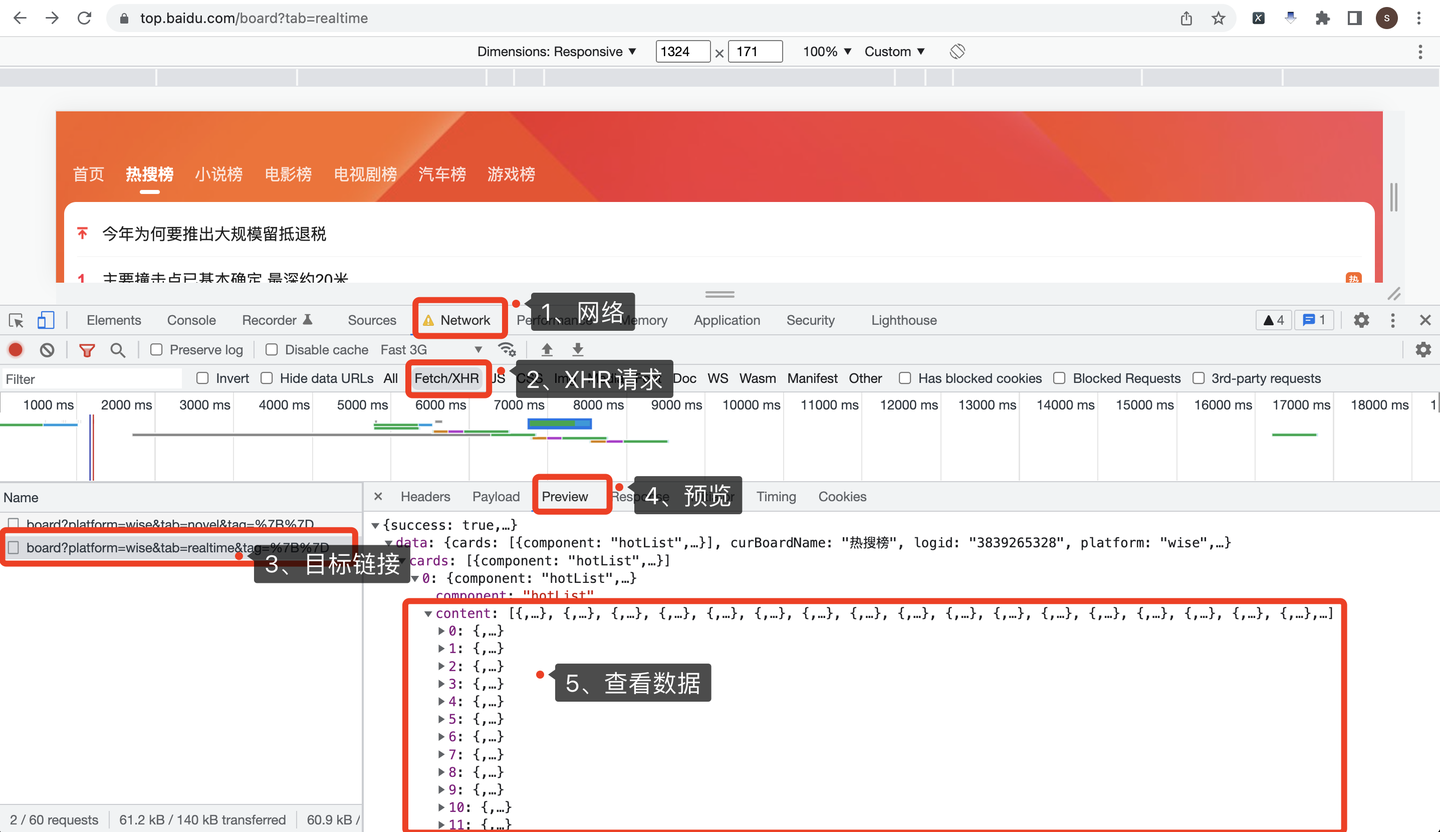
经过分析,此页面有XHR链接,可以针对接口进行爬取。
打开Chrome浏览器,按F12进入开发者模式,依次点击:
- 点击Network,选择网络
- 点击XHR,选择XHR请求
- 选择目标链接地址
- 击Preview,选择预览
- 查看返回数据
操作过程,如下图所示:
二、编写爬虫代码
首先,导入需要用到的库:
import requests # 发送请求
import pandas as pd # 存入excel数据
定义一个百度热搜榜接口地址:
# 百度热搜榜地址
url = 'https://top.baidu.com/api/board?platform=wise&tab=realtime'
构造一个请求头,伪装爬虫:
# 构造请求头
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'Host': 'top.baidu.com',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://top.baidu.com/board?tab=novel',
}
向百度页面发送requests请求:
# 发送请求
r = requests.get(url, header)
返回的数据是json格式的,直接用r.json()接收:
# 用json格式接收请求数据
json_data = r.json()
这里,需要注意的是,页面上有2种热搜:
百度热搜榜最上面一条是置顶热搜,下面从1到30是普通热搜,接口返回的数据也是区分开的:
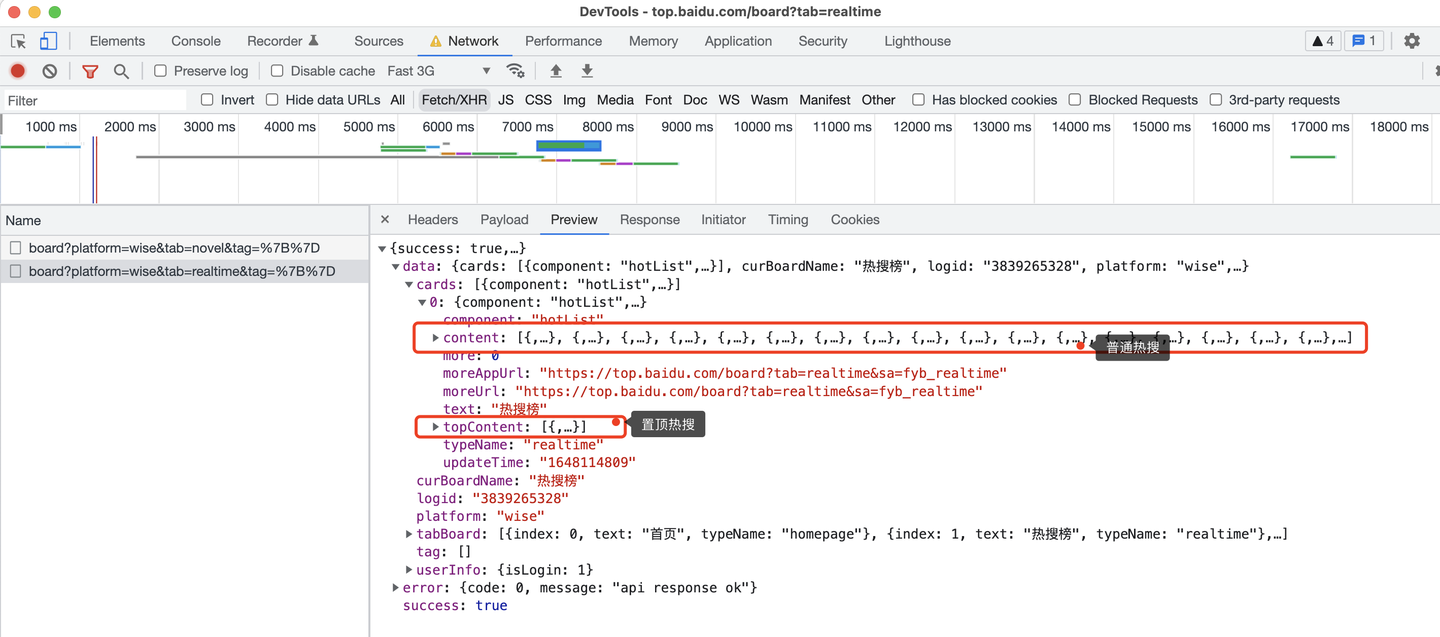
所以,爬虫代码需要分开处理逻辑:
置顶热搜:
# 爬取置顶热搜
top_content_list = json_data['data']['cards'][0]['topContent']
普通热搜:
# 爬取普通热搜
content_list = json_data['data']['cards'][0]['content']
然后再分别进行json解析,对应的字段(标题、排名、热搜指数、描述、链接地址)。
最后,保存结果数据到excel即可。
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'热搜标题': title_list,
'热搜排名': order_list,
'热搜指数': score_list,
'描述': desc_list,
'链接地址': url_list
}
)
df.to_excel('百度热搜榜.xlsx', index=False) # 保存结果数据
最后,查看一下爬取到的数据:

一共31条数据(1条置顶热搜+30条普通热搜)。
每条数据包含:热搜标题、热搜排名、热搜指数、描述、链接地址。
三、同步视频讲解
讲解视频:https://www.zhihu.com/zvideo/1490668062617161728
四、完整源码
get完整源码:【爬虫案例】用Python爬取百度热搜榜数据!
我是@马哥python说,持续分享python源码干货中!
【爬虫案例】用Python爬取百度热搜榜数据!的更多相关文章
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
- nodejs实现定时爬取微博热搜
The summer is coming " 我知道,那些夏天,就像青春一样回不来. - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了. 废话 我发现,自己对 coding 这 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
随机推荐
- matlab学习系列
matlab系列学习 1.学习缘由 本来已经学习过这个软件,了解了包括电路仿真在内的诸多功能,能够比较熟练地编写m文件和函数. 但是,在最近的依次练习中发现之前的许多操作都忘记了.有一些基本的语法都不 ...
- Windows线程API —CreateTimerQueueTimer/DeleteTimerQueueTimer的使用
问题代码: 1 #include<windows.h> 2 #include<iostream> 3 #include<thread> 4 HANDLE h1; 5 ...
- Python爬虫爬取ECVA论文标题、作者、链接
1 import re 2 import requests 3 from bs4 import BeautifulSoup 4 import lxml 5 import traceback 6 imp ...
- 应对 DevOps 中的技术债务:创新与稳定性的微妙平衡
技术性债务在DevOps到底意味着什么?从本质上讲,这是小的开发缺陷的积累,需要不断地返工.它可能由多种原因引起,例如快速交付新功能的压力,这可能会导致团队不得不牺牲代码的整洁和完善.但这些不完整的小 ...
- #AC自动机#洛谷 2444 [POI2000]病毒
题目 给定若干01串,问是否存在无限长的01串任意子串不是给定的若干串 分析 如果在AC自动机上跳到了访问过的前缀即代表存在一个循环可以无限跳, 在AC自动机上记录哪些状态是不能访问的,在AC自动机上 ...
- Seaborn分布数据可视化---直方图/密度图
直方图\密度图 直方图和密度图一般用于分布数据的可视化. distplot 用于绘制单变量的分布图,包括直方图和密度图. sns.distplot( a, bins=None, hist=True, ...
- MyBatis-Plus 代码生成(新)
MyBatis-Plus 的代码生成功能十分人性化,即支持通过简单的配置实现,也可以通过自定义模板实现. 这里列出项目中的常用配置供参考,其他配置可以参考官网:https://baomidou.com ...
- 上新啦KIT
HMS Core上新啦!分析服务区服分析全新上线:机器学习服务OCR新增手写识别服务:3D建模续扫能力更新:视频编辑服务支持自定义上传素材--更多#HMS Core#能力可点击网页链接了解. 了解更多 ...
- Taurus.MVC 性能压力测试(ap 压测 和 linux 下wrk 压测):.NET Core 版本
前言: 最近的 Taurus.MVC 版本,对性能这一块有了不少优化,因此准备进行一下压测,来测试并记录一下 Taurus.MVC 框架的性能,以便后续持续优化改进. 今天先压测 .NET Core ...
- 重新点亮shell————awk数组[十四]
前言 简单介绍一下awk的数组. 正文 数组的定义: 数组的遍历: 删除数组: 例子: 例子2: 结 下一节awk函数.