【SIGIR 2022】面向长代码序列的Transformer模型优化方法,提升长代码场景性能
简介: 论文主导通过引入稀疏自注意力的方式来提高Transformer模型处理长序列的效率和性能
阿里云机器学习平台PAI与华东师范大学高明教授团队合作在SIGIR2022上发表了结构感知的稀疏注意力Transformer模型SASA,这是面向长代码序列的Transformer模型优化方法,致力于提升长代码场景下的效果和性能。由于self-attention模块的复杂度随序列长度呈次方增长,多数编程预训练语言模型(Programming-based Pretrained Language Models, PPLM)采用序列截断的方式处理代码序列。SASA方法将self-attention的计算稀疏化,同时结合了代码的结构特性,从而提升了长序列任务的性能,也降低了内存和计算复杂度。
论文:Tingting Liu, Chengyu Wang, Cen Chen, Ming Gao, and Aoying Zhou. Understanding Long Programming Languages with Structure-Aware Sparse Attention. SIGIR 2022
模型框架
下图展示了SASA的整体框架:

其中,SASA主要包含两个阶段:预处理阶段和Sparse Transformer训练阶段。在预处理阶段得到两个token之间的交互矩阵,一个是top-k frequency矩阵,一个是AST pattern矩阵。Top-k frequency矩阵是利用代码预训练语言模型在CodeSearchNet语料上学习token之间的attention交互频率,AST pattern矩阵是解析代码的抽象语法树(Abstract Syntax Tree,AST ),根据语法树的连接关系得到token之间的交互信息。Sparse Transformer训练阶段以Transformer Encoder作为基础框架,将full self-attention替换为structure-aware sparse self-attention,在符合特定模式的token pair之间进行attention计算,从而降低计算复杂度。
SASA稀疏注意力一共包括如下四个模块:
- Sliding window attention:仅在滑动窗口内的token之间计算self-attention,保留局部上下文的特征,计算复杂度为
 ,
, 为序列长度,
为序列长度, 是滑动窗口大小。
是滑动窗口大小。 - Global attention:设置一定的global token,这些token将与序列中所有token进行attention计算,从而获取序列的全局信息,计算复杂度为
 ,
, 为global token个数。
为global token个数。 - Top-k sparse attention:Transformer模型中的attention交互是稀疏且长尾的,对于每个token,仅与其attention交互最高的top-k个token计算attention,复杂度为
 。
。 - AST-aware structure attention:代码不同于自然语言序列,有更强的结构特性,通过将代码解析成抽象语法树(AST),然后根据语法树中的连接关系确定attention计算的范围。
为了适应现代硬件的并行计算特性,我们将序列划分为若干block,而非以token为单位进行计算,每个query block与个滑动窗口blocks和 个global blocks以及
个global blocks以及 个top-k和AST blocks计算attention,总体的计算复杂度为
个top-k和AST blocks计算attention,总体的计算复杂度为 ,
, 为block size。
为block size。
每个sparse attention pattern 对应一个attention矩阵,以sliding window attention为例,其attention矩阵的计算为:

ASA伪代码:

实验结果
我们采用CodeXGLUE[1]提供的四个任务数据集进行评测,分别为code clone detection,defect detection,code search,code summarization。我们提取其中的序列长度大于512的数据组成长序列数据集,实验结果如下:

从实验结果可以看出,SASA在三个数据集上的性能明显超过所有Baseline。其中Roberta-base[2],CodeBERT[3],GraphCodeBERT[4]是采用截断的方式处理长序列,这将损失一部分的上下文信息。Longformer[5]和BigBird[6]是在自然语言处理中用于处理长序列的方法,但未考虑代码的结构特性,直接迁移到代码任务上效果不佳。
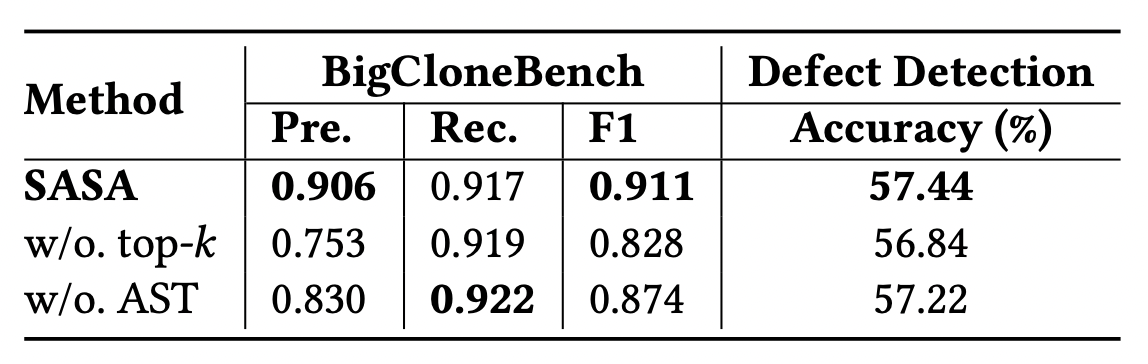
为了验证top-k sparse attention和AST-aware sparse attention模块的效果,我们在BigCloneBench和Defect Detection数据集上做了消融实验,结果如下:
sparse attention模块不仅对于长代码的任务性能有提升,还可以大幅减少显存使用,在同样的设备下,SASA可以设置更大的batch size,而full self-attention的模型则面临out of memory的问题,具体显存使用情况如下图:

SASA作为一个sparse attention的模块,可以迁移到基于Transformer的其他预训练模型上,用于处理长序列的自然语言处理任务,后续将集成到开源框架EasyNLP(https://github.com/alibaba/EasyNLP)中,贡献给开源社区。
论文链接:https://arxiv.org/abs/2205.13730
参考文献
[1] Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin B. Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, Shujie Liu. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation. NeurIPS Datasets and Benchmarks 2021
[2] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019)
[3] Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, Ming Zhou. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. EMNLP 2020
[4] Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin B. Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, Ming Zhou. GraphCodeBERT: Pre-training Code Representations with Data Flow. ICLR 2021
[5] Iz Beltagy, Matthew E. Peters, Arman Cohan. Longformer: The Long-Document Transformer. CoRR abs/2004.05150 (2020)
[6] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontañón, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed. Big Bird: Transformers for Longer Sequences. NeurIPS 2020
了解更多精彩内容,欢迎关注我们的阿里灵杰公众号
原文链接:http://click.aliyun.com/m/1000348767/
本文为阿里云原创内容,未经允许不得转载。
【SIGIR 2022】面向长代码序列的Transformer模型优化方法,提升长代码场景性能的更多相关文章
- (LIS)最长上升序列(DP+二分优化)
求一个数列的最长上升序列 动态规划法:O(n^2) //DP int LIS(int a[], int n) { int DP[n]; int Cnt=-1; memset(DP, 0, sizeof ...
- dp(最长升序列:二分查找时间优化nlogn)
We are all familiar with sorting algorithms: quick sort, merge sort, heap sort, insertion sort, sele ...
- XHXJ's LIS HDU - 4352 最长递增序列&数位dp
代码+题解: 1 //题意: 2 //输出在区间[li,ri]中有多少个数是满足这个要求的:这个数的最长递增序列长度等于k 3 //注意是最长序列,可不是子串.子序列是不用紧挨着的 4 // 5 // ...
- [LeetCode] 298. Binary Tree Longest Consecutive Sequence 二叉树最长连续序列
Given a binary tree, find the length of the longest consecutive sequence path. The path refers to an ...
- [LeetCode] 549. Binary Tree Longest Consecutive Sequence II 二叉树最长连续序列之 II
Given a binary tree, you need to find the length of Longest Consecutive Path in Binary Tree. Especia ...
- 序列推荐(transformer)
目录 Attention演进(RNN&LSTM&GRU&Seq2Seq + Attention机制) LSTM GRU Seq2Seq + Attention机制 Attent ...
- [LeetCode] Binary Tree Longest Consecutive Sequence 二叉树最长连续序列
Given a binary tree, find the length of the longest consecutive sequence path. The path refers to an ...
- [LeetCode] Longest Consecutive Sequence 求最长连续序列
Given an unsorted array of integers, find the length of the longest consecutive elements sequence. F ...
- ACM: Racing Gems - 最长递增序列
Racing Gems You are playing a racing game. Your character starts at the x axis (y = 0) and procee ...
- leetcode 最长连续序列 longest consecutive sequence
转载请注明来自souldak,微博:@evagle 题目(来自leetcode): 给你一个n个数的乱序序列,O(N)找出其中最长的连续序列的长度. 例如给你[100, 4, 200, 1, 3, 2 ...
随机推荐
- HTML <nav> 标签
定义和用法 标签定义导航链接的部分. 提示和注释 提示:如果文档中有"前后"按钮,则应该把它放到 元素中. 实例 <!DOCTYPE html> <html> ...
- MyBatis Java 和 Mysql数据库 数据类型对应表
类型处理器(typeHandlers) MyBatis 在设置预处理语句(PreparedStatement)中的参数或从结果集中取出一个值时, 都会用类型处理器将获取到的值以合适的方式转换成 Jav ...
- 喜报|3DCAT入选“灵境杯”深圳市最佳元宇宙案例!
2022年11月10日~11日,2022全球元宇宙大会深圳站胜利召开,在本次大会上重磅发布"灵境杯"全球元宇宙创新大赛成果,公布深圳最具潜力元宇宙入选企业. 创新大赛结合" ...
- 用Vue3.0 写过组件吗?如果想实现一个 Modal你会怎么设计?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一.组件设计 组件就是把图形.非图形的各种逻辑均抽象为一个统一的概念(组件)来实现开发的模式 现在有一个场景,点击新增与编辑都弹框出来进行 ...
- 记录--Canvas实现打飞字游戏
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 打开游戏界面,看到一个画面简洁.却又富有挑战性的游戏.屏幕上,有一个白色的矩形框,里面不断下落着各种单词,而我需要迅速地输入这些单词.如果 ...
- 优化Mysql配置调整内存
1.查看Mysql版本 # mysql -V 示例: [root@root /]# mysql -V mysql Ver 14.14 Distrib 5.7.44, for Linux (x86_64 ...
- FastJson反序列化2-1.2.24漏洞利用
1.1.2.24漏洞利用-JNDI 漏洞利用思路,如果某个类的set()方法中使用了JNDI,那么则可以使用JDNI注入执行任意命令.事实上在JDK8中就存在这样的类:JDBCRowSetImpl; ...
- DRConv:旷视提出区域感知动态卷积,多任务性能提升 | CVPR 2020
论文提出DRConv,很好地结合了局部共享的思想并且保持平移不变性,包含两个关键结构,从实验结果来看,DRConv符合设计的预期,在多个任务上都有不错的性能提升 来源:晓飞的算法工程笔记 公众号 ...
- 求一个整数的因数分解--Java--小白必懂
public class OJ_1415 { public static void main(String[] args) { Scanner sc = new Scanner(System.in); ...
- 绚烂之境:Python Rich,让终端输出更炫酷!
转载请注明出处️ 作者:测试蔡坨坨 原文链接:caituotuo.top/c8c7bd95.html 初识rich 你好,我是测试蔡坨坨. 在代码的世界里,每一行都是一个故事,每一个变量都是一个角色, ...