深度学习需要float64精度吗 —— 为什么各大深度学习框架均不支持float64的深度学习运算呢 —— 商用NVIDIA显卡的float64性能是否多余呢
首先要知道这么几个事实,也是交代一下本文要讨论的问题的背景:
- 各大深度学习框架均支持float64类型的简单运算,但是均不支持float64的深度学习的运算操作;
- 作为深度学习运行的加速设备,各种GPU、TPU、NPU的各种XPU均以其卓越的float64精度计算能力作为宣传,如NVIDIA公司的显卡,其商用版本显卡与家用版本最大的两个不同的性能参数,一个是显存带宽,另一个则是float64计算能力;
在知道了上面的几个事实后,我们这里要问的问题就是既然各大深度学习的设备厂商都以float64性能作为主打宣传,但是为啥各大深度学习框架不支持float64的深度学习运算操作呢?
答案:
深度学习的各种操作其实用不到float64精度。
经过研究发现float32精度就完全够用,而且计算结果和float64精度基本保持一致,甚至有大量研究发现float16精度可以取得和float32精度下相近的最终结果,更为甚者有研究使用int16或int8的精度来进行深度学习计算,也能获得和float32精度下相差程度可以接受的结果。在进行加速计算时浮点型精度越高计算速度越慢,占用的显存也越大,如float16的运算速度则是float32的2倍,而显存占用则是50%,而使用int8这种精度更小的整数类型进行计算则更能大幅度加速计算并减少显存占用(当然这时产生的最终结果要比float32下的有一定差距,但通过一些技术可以控制在一定的可接受范围内)。
各种xPU的始祖,NVIDIA的GPU,其通用计算能力最初是为HPC做异构计算加速的,那个时候还没深度学习什么事情呢。HPC,就是传输中的高性能运行,一般使用C/C++语言配合MPI消息传递框架进行编程,主要运行在各个超级计算机集群上,如我国的天河超算,银河超算等等,最初的应用场景就是做仿真计算,如为飞机制造做设计,算空气动力学,算化学方程式,算药物学方程式,算核物理方程式,算卫星火箭导弹的各种方程式,算天气预报的各种方程式,算地震预测的各种方程式,等等吧,总之这些类型的计算又可以统称为线性代数计算(对,这个就是大学里面学的那个矩阵计算的那个数学)。最初美国搞出HPC这一套东西的时候都是用CPU计算的,后来NVIDIA公司提出这种矩阵计算其实使用GPU是速度更快的,因为GPU本身就是为计算机图形显示做矩阵计算的,也因此就有了GPU的通用计算的这个功能,而这个功能也就自然而然的用到了HPC上,这也就是最早的异构计算。但是政府和军方的订单总是有限的,为了进一步扩大营收,NVIDIA公司就把这个GPU的通用计算功能扩展到了家用级别的显卡上,也就是后来的GTX和RTX这些类型的显卡,这些家用显卡由于具备和军用、政府用的商用级别显卡具备近乎相同的计算能力(除显存带宽和float64精度计算能力不同),其它方面的性能都是几乎一致的。显存带宽会控制整体计算能力的最大吞吐量,也就是控制了GPU设备的最高计算性能,但是要注意,由于GPU的计算核心是不被限制的,因此即使被控制最大吞吐量,但是对于绝大部分科研用处的使用都是足够的,而且要知道往往集群GPU的计算才比较受显存带宽的影响,而绝大部分非军用、非政府用的单机或小集群(三五台主机的情况)其实GPU的带宽对整体性能影响不大。而float64的计算往往是用于军用和政府用处的对精度要求高的仿真计算上,如对桥梁设计时的受力仿真分析,对核物理的反应方程式的计算等等,而民营的场合和科研单位的场合往往是小集群的(受显存带宽影响较小),并且对计算精度要求并不高(比如算某个聚类算法的baseline,如k-means),基本float32就够用,即使有用到float64精度的时候,科研单位或者民用的场合对于这个计算性能要求也没那么高,毕竟家用GPU的float64计算能力只是商用的30%到50%性能,也不是不能用,只是慢些,这种科研单位和民用场合是完全可以接受的。
深度学习的任务类型属于线性代数计算,也就是说深度学习计算也是HPC计算下的任务的一种,因此GPU也可以用来给深度学习计算来加速(这也是为啥现在GPU这么火的原因)。
深度学习框架在设计的时候同时也包括了非深度学习之外的其他线性代数的计算用处的设计,比如pytorch、TensorFlow、jax和mindspore,也就是说这些深度学习框架不仅可以用来做深度学习计算,也可以用来做其他的线性代数的计算之用,如上面见过的各种仿真计算和方程式求解等等。虽然深度学习计算用不到float64精度,但是其他类型的计算却会用到float64精度,如各种化学分子的仿真、药物仿真、天体运行仿真等等,而这些其他场景的线性代数的运算也是深度学习框架设计支持的(虽然这部分的使用率占比很小)。
总结来说,各种xPU虽然是用来给深度学习框架加速的,但是也可以用来给其他的线性代数的计算框架加速的,而很多非深度学习计算的任务是需要使用到float64精度的,因此这些xPU是需要具有float64精度的计算能力的。由于民用场合下对float64的计算场景不多,但是军用等场合是需要的,这也是为什么美国的NVIDIA公司会单纯的以float64计算能力作为民用和军用的分割点(当然还有大集群下的显存带宽也是分割点),因此float64是xPU需要支持的,民用的要比军用的xPU在float64精度上运算慢。虽然深度学习用不到float64精度,但是深度学习框架被设计用来支持的其他线性代数运算(其他科学计算任务,非自动微分的任务)却是需要使用float64精度的,这也就是为啥深度学习框架不支持float64精度的深度学习运算,但是支持float64精度的非深度学习运算(不需要自动微分的场景,不是神经网络的场景,不需要反传的场景,如机器学习算法中的k-means,很多传统的机器学习算法是不需要自动微分和求反传的)。
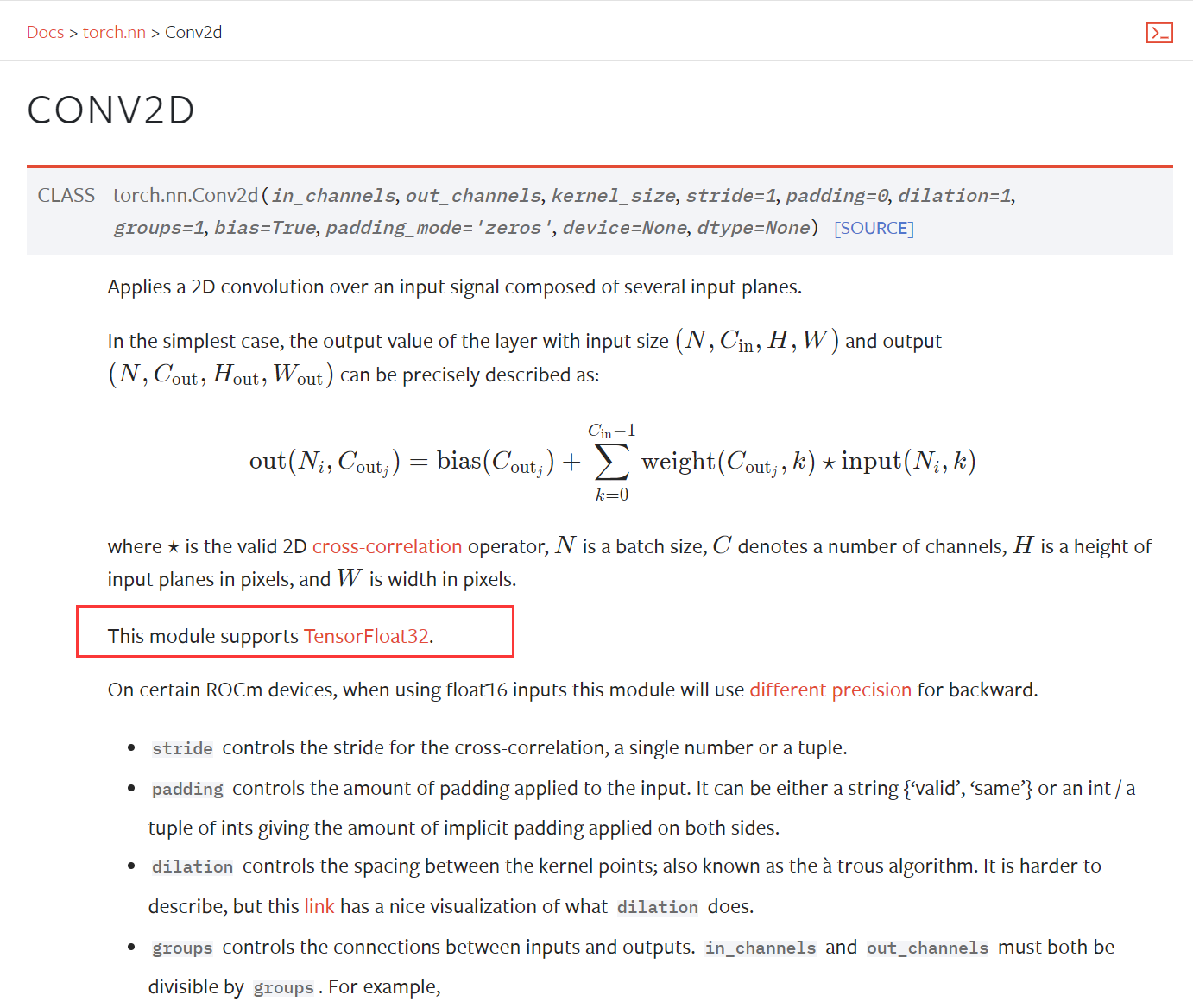
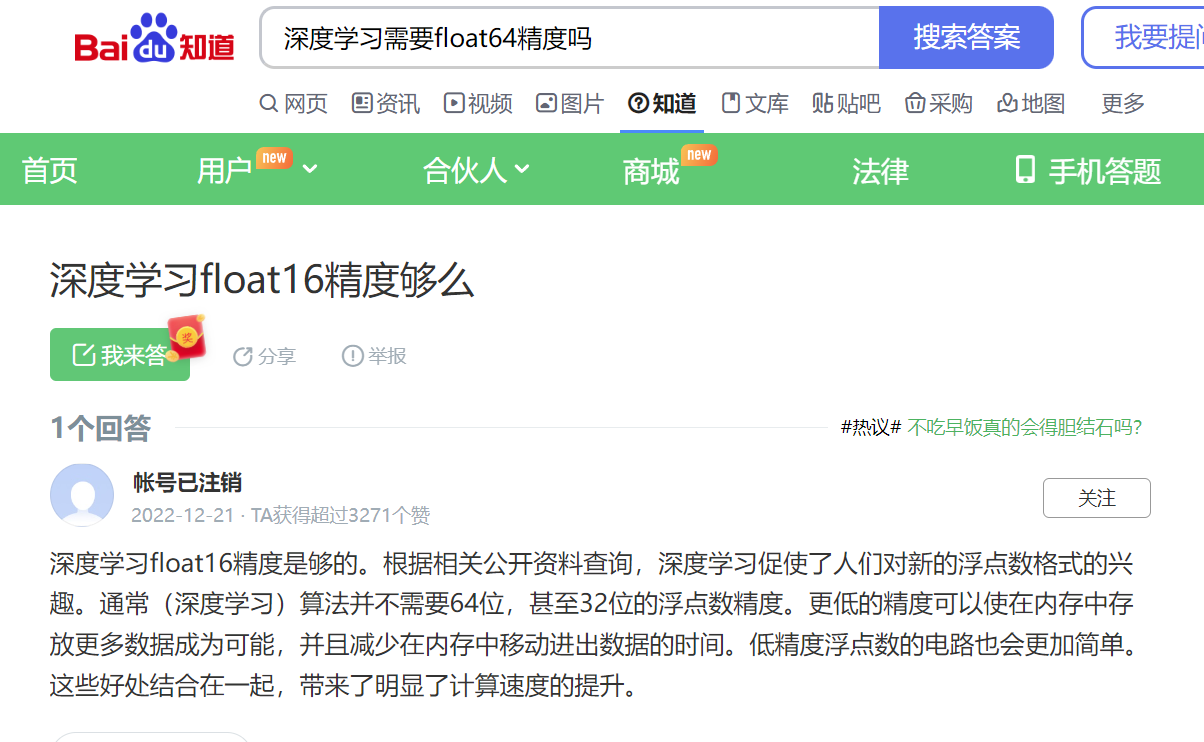
为什么深度学习框架的深度学习操作不支持float64的说明材料:
下面引自的相关链接:
地址:https://zhidao.baidu.com/question/928691981765151259.html
深度学习需要float64精度吗 —— 为什么各大深度学习框架均不支持float64的深度学习运算呢 —— 商用NVIDIA显卡的float64性能是否多余呢的更多相关文章
- 【深度学习系列2】Mariana DNN多GPU数据并行框架
[深度学习系列2]Mariana DNN多GPU数据并行框架 本文是腾讯深度学习系列文章的第二篇,聚焦于腾讯深度学习平台Mariana中深度神经网络DNN的多GPU数据并行框架. 深度神经网络( ...
- 42步进阶学习—让你成为优秀的Java大数据科学家!
作者 灯塔大数据 本文转自公众号灯塔大数据(DTbigdata),转载需授权 如果你对各种数据类的科学课题感兴趣,你就来对地方了.本文将给大家介绍让你成为优秀数据科学家的42个步骤.深入掌握数据准备, ...
- .NET CORE学习笔记系列(2)——依赖注入[7]: .NET Core DI框架[服务注册]
原文https://www.cnblogs.com/artech/p/net-core-di-07.html 包含服务注册信息的IServiceCollection对象最终被用来创建作为DI容器的IS ...
- .NET CORE学习笔记系列(2)——依赖注入[6]: .NET Core DI框架[编程体验]
原文https://www.cnblogs.com/artech/p/net-core-di-06.html 毫不夸张地说,整个ASP.NET Core框架是建立在一个依赖注入框架之上的,它在应用启动 ...
- NASNet学习笔记—— 核心一:延续NAS论文的核心机制使得能够自动产生网络结构; 核心二:采用resnet和Inception重复使用block结构思想; 核心三:利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
from:https://blog.csdn.net/xjz18298268521/article/details/79079008 NASNet总结 论文:<Learning Transfer ...
- Web前端学习,需用了解的7大HTML知识点
HTML是web前端开发基础,关于HTML,这里有几个很重要的知识点,在日常开发常常用到,并且在大家面试的时候也会问的,记住这7个重要知识点,助你在面试时优先录用. 1.网页结构 网页结构一般都包含文 ...
- DRF框架中链表数据通过ModelSerializer深度查询方法汇总
DRF框架中链表数据通过ModelSerializer深度查询方法汇总 一.准备测试和理解准备 创建类 class Test1(models.Model): id = models.IntegerFi ...
- 大神教零基础入门如何快速高效的学习c语言开发
零基础如果更快更好的入门C语言,如何在枯燥的学习中找到属于自己的兴趣,如果把学习当成一种事务性的那以后的学习将会很难有更深入的进步,如果带着乐趣来完成学习那将越学越有意思这样才会让你有想要更深入学习的 ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
- NVIDIA 显卡与 CUDA 在深度学习中的应用
CUDA(Compute Unified Device Architecture),是显卡厂商 NVIDIA 推出的运算平台. 0. 配置 显卡驱动的下载地址:Drivers - Download N ...
随机推荐
- Prometheus + Grafana (2) mysql、redis、Docker容器、服务端点以及预警
接着上一节 <Prometheus + Grafana (1) 监控 >,我们继续探讨 Prometheus + Grafana 的复杂应用 实现目标 这节我们的目标是搭建一个多维度监控微 ...
- 牛客网在线编程-语法篇-基础语法——C 语言解题集
前言 牛客网在线编程-语法篇-基础语法--C 语言解题集. 点击下方超链接跳转至对应编程题目,文章包含解析及源码. 01-基础语法 简单输出 BC1-Hello Nowcoder BC2-小飞机 基本 ...
- Hibernate Validator 校验注解
Hibernate Validator 校验注解/** * 认识一些校验注解Hibernate Validator * * @NotNull 值不能为空 * @Null 值必须为空 * @Patter ...
- 实验一:Wireshark工具的使用
1.0 [实验目的] 了解Wireshark.TCP协议的概念,掌握Wireshark抓包工具的使用.FTP的搭建和登录,学会对Wireshark抓包结果的分析. 2.0[知识点] Wireshark ...
- VSCode因网络问题导致下载更新/扩展出错
VSCode因网络问题导致下载更新/扩展出错 可尝试方法: 问题0: VSCode出现网络问题排查方法? 法1: 启动时加上选项 --log-net-log=netlog.json ...
- 2.上传hdfs系统:将logs目录下的日志文件每隔十分钟上传一次 要求:上传后的文件名修为:2017111513xx.log_copy
先在hdfs系统创建文件夹logshadoop fs -mkdir /logs 编辑shell脚本 filemv.sh #!/bin/bashPATH=/usr/local/bin:/bin:/usr ...
- 树莓派4B安装64位桌面版ubuntu20
[准备] 硬件: 电脑.树莓派4B.显示器(hdmi线Micro HDMI转标准HDMI).鼠标.键盘.读卡器.TF卡.网线 软件:ubuntu20(x64桌面版).官方烧录工具Raspberry P ...
- MySql 数据库、数据表操作
数据库操作 创建数据库 语法 语法一:create database 数据库名 语法二:create database 数据库名 character set 字符集; 查看数据库 语法 查看数据库服务 ...
- 基于vsftpd搭建项目文件服务器
vsftpd 是"very secure FTP daemon"的缩写,安全性是它的一个最大的特点.vsftpd 是一个 UNIX 类操作系统上运行的服务器的名字,它可以运行在诸如 ...
- IDEA新手使用教程之使用技巧总结【详解】
IDEA是一款功能强悍.非常好用的Java开发工具,近几年编程开发人员对IDEA情有独钟. 一.IDEA的下载 IDEA下载地址:https://www.jetbrains.com/idea/down ...