Not All Samples Are Created Equal: Deep Learning with Importance Sampling
@article{katharopoulos2018not,
title={Not All Samples Are Created Equal: Deep Learning with Importance Sampling},
author={Katharopoulos, Angelos and Fleuret, F},
journal={arXiv: Learning},
year={2018}}
概
本文提出一种删选合适样本的方法, 这种方法基于收敛速度的一个上界, 而并非完全基于gradient norm的方法, 使得计算比较简单, 容易实现.
主要内容
设\((x_i,y_i)\)为输入输出对, \(\Psi(\cdot;\theta)\)代表网络, \(\mathcal{L}(\cdot, \cdot)\)为损失函数, 目标为
\theta^* = \arg \min_{\theta} \frac{1}{N} \sum_{i=1}^N\mathcal{L}(\Psi(x_i;\theta),y_i),
\]
其中\(N\)是总的样本个数.
假设在第\(t\)个epoch的时候, 样本(被选中)的概率分布为\(p_1^t,\ldots,p_N^t\), 以及梯度权重为\(w_1^t, \ldots, w_N^t\), 那么\(P(I_t=i)=p_i^t\)且
\theta_{t+1}=\theta_t-\eta w_{I_t}\nabla_{\theta_t} \mathcal{L}(\Psi(x_{I_t};\theta_t),y_{I_t}),
\]
在一般SGD训练中\(p_i=1/N,w_i=1\).
定义\(S\)为SGD的收敛速度为:
S :=-\mathbb{E}_{P_t}[\|\theta_{t+1}-\theta^*\|_2^2-\|\theta_t-\theta^*\|_2^2],
\]
如果我们令\(w_i=\frac{1}{Np_i}\) 则
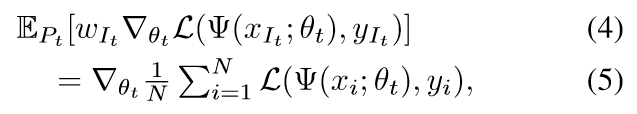
定义\(G_i=w_i\nabla_{\theta_t} \mathcal{L}(\Psi(x_{i};\theta_t),y_{i})\)

我们自然希望\(S\)能够越大越好, 此时即负项越小越好.
定义\(\hat{G}_i \ge \|\nabla_{\theta_t} \mathcal{L}(\Psi(x_{i};\theta_t),y_{i})\|_2\), 既然
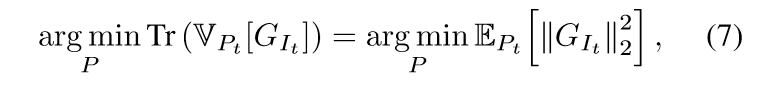
(7)式我有点困惑,我觉得(7)式右端和最小化(6)式的负项(\(\mathrm{Tr}(\mathbb{V}_{P_t}[G_{I_t}])+\|\mathbb{E}_{P_t}[G_{I_t}]\|_2^2\))是等价的.
于是有
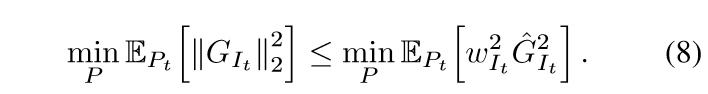
最小化右端(通过拉格朗日乘子法)可得\(p_i \propto \hat{G}_i\), 所以现在我们只要找到一个\(\hat{G}_i\)即可.
这个部分需要引入神经网络的反向梯度的公式, 之前有讲过,只是论文的符号不同, 这里不多赘诉了.

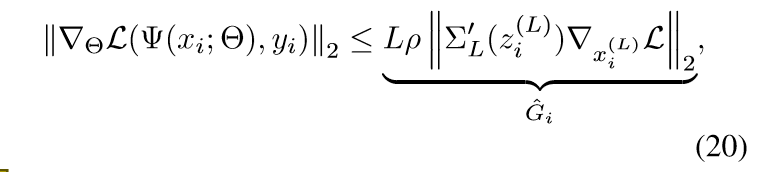
注意\(\rho\)的计算是比较复杂的, 但是\(p_i \propto \hat{G}_i\), 所以我们只需要计算\(\|\cdot\|\)部分, 设此分布为\(g\).
另外, 在最开始的时候, 神经网络没有得到很好的训练, 权重大小相差无几, 这个时候是近似正态分布的, 所以作者考虑设计一个指标,来判断是否需要根据样本分布\(g\)来挑选样本. 作者首先衡量

显然当这部分足够大的时候我们可以采用分布\(g\)而非正态分布\(u\), 但是这个指标不易判断, 作者进步除以\(\mathrm{Tr}(\mathbb{V}_u[G_i])\).

显然\(\tau\)越大越好, 我们自然可以人为设置一个\(\tau_{th}\). 算法如下

最后, 个人认为这个算法能减少计算量主要是因为样本少了, 少在一开始用正态分布抽取了一部分, 所以...
"代码"
主要是\(\hat{G}_i\)部分的计算, 因为涉及到中间变量的导数, 所以需要用到retain_grad().
"""
这里只是一个例子
"""
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.dense = nn.Sequential(
nn.Linear(10, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
self.final = nn.ReLU()
def forward(self, x):
z = self.dense(x)
z.retain_grad()
out = self.final(z)
return out, z
if __name__ == "__main__":
net = Net()
criterion = nn.MSELoss()
x = torch.rand((2, 10))
y = torch.rand((2, 10))
out, z = net(x)
loss = criterion(out, y)
loss.backward()
print(z.grad) #这便是我们所需要的
Not All Samples Are Created Equal: Deep Learning with Importance Sampling的更多相关文章
- Accelerating Deep Learning by Focusing on the Biggest Losers
目录 概 相关工作 主要内容 代码 Accelerating Deep Learning by Focusing on the Biggest Losers 概 思想很简单, 在训练网络的时候, 每个 ...
- (转) The major advancements in Deep Learning in 2016
The major advancements in Deep Learning in 2016 Pablo Tue, Dec 6, 2016 in MACHINE LEARNING DEEP LEAR ...
- Deep Learning in R
Introduction Deep learning is a recent trend in machine learning that models highly non-linear repre ...
- Summary on deep learning framework --- PyTorch
Summary on deep learning framework --- PyTorch Updated on 2018-07-22 21:25:42 import osos.environ[ ...
- [C3] Andrew Ng - Neural Networks and Deep Learning
About this Course If you want to break into cutting-edge AI, this course will help you do so. Deep l ...
- Deep Learning 5_深度学习UFLDL教程:PCA and Whitening_Exercise(斯坦福大学深度学习教程)
前言 本文是基于Exercise:PCA and Whitening的练习. 理论知识见:UFLDL教程. 实验内容:从10张512*512自然图像中随机选取10000个12*12的图像块(patch ...
- (转)WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE
Main Menu Fortune.com E-mail Tweet Facebook Linkedin Share icons By Roger Parloff Illustration ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- (转)The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)
Adit Deshpande CS Undergrad at UCLA ('19) Blog About The 9 Deep Learning Papers You Need To Know Abo ...
随机推荐
- 日常Java 2021/10/3
方法: 用System.out.println()来解释,println()是一个方法,System是系统类,out 是标准输出对象. 也就是调用系统类中的对象中的方法. 注重方法:可以是程序简洁,有 ...
- 大数据学习day22------spark05------1. 学科最受欢迎老师解法补充 2. 自定义排序 3. spark任务执行过程 4. SparkTask的分类 5. Task的序列化 6. Task的多线程问题
1. 学科最受欢迎老师解法补充 day21中该案例的解法四还有一个问题,就是当各个老师受欢迎度是一样的时候,其排序规则就处理不了,以下是对其优化的解法 实现方式五 FavoriteTeacher5 p ...
- Linux基础命令---nslookup查询域名工具
nslookup nslookup是一个查询DNS域名的工具,它有交互和非交互两种工作模式. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.Fedora. 1.语法 ...
- 【Java多线程】CompletionService
什么是CompletionService? 当我们使用ExecutorService启动多个Callable时,每个Callable返回一个Future,而当我们执行Future的get方法获取结果时 ...
- JSP 文字乱码、${}引用无效
问题: 代码:<form action="/test/requestPost.do" method="post"> <input type=& ...
- hibernate多对多单向(双向)关系映射
n-n(多对多)的关联关系必须通过连接表实现.下面以商品种类和商品之间的关系,即一个商品种类下面可以有多种商品,一种商品又可以属于多个商品种类,分别介绍单向的n-n关联关系和双向的n-n关联关系. 单 ...
- MES目前应用很多,为什么APS计划排程系统应用很少?
一.APS自动化计划排程能带来哪些效益? 1.提高订单准时交货率,提高客户满意度 2.缩短生产制造周期,提高生产效率 3.多品种.小批量.以销定产,快速解决插单.急单预测交期问题 4.减少物料采购提前 ...
- Table.FirstN保留前面N….First…(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Boto3访问AWS资源操作总结(1)
最近在工作中需要对AWS上的部分资源进行查询和交叉分析,虽然场景都比较简单,但是这种半机械的工作当然还是交给Python来搞比较合适.AWS为Python提供的SDK库叫做boto3,所以我们建立一个 ...
- linux安装软件系列之npm安装
什么是rpm 百度说它是 Red-hat Package Manager (红帽包管理器) 其实它是:RPM Package Manager (RPM包管理器,来源于:https://rpm.org) ...