zookeeper和Kafka集群安装配置
3个虚拟机,首先关闭防火墙,在进行下面操作

和多个follower
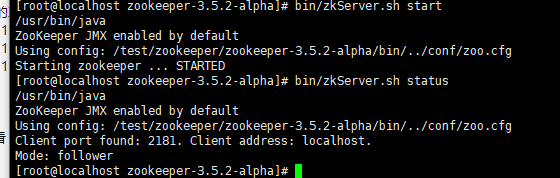


.png)

.png)

zookeeper和Kafka集群安装配置的更多相关文章
- (Linux环境Kafka集群安装配置及常用命令
Linux环境Kafka集群安装配置及常用命令 Kafka 消息队列内部实现原理 Kafka架构 一.下载Kafka安装包 二.Kafka安装包的解压 三.设置环境变量 四.配置kafka文件 4.1 ...
- kafka集群安装配置
1.下载安装包 2.解压安装包 3.进入到kafka的config目录修改server.properties文件 进入后显示如下: 修改log.dirs,基本上大部分都是默认配置 kafka依赖zoo ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- zookeeper+kafka集群安装之二
zookeeper+kafka集群安装之二 此为上一篇文章的续篇, kafka安装需要依赖zookeeper, 本文与上一篇文章都是真正分布式安装配置, 可以直接用于生产环境. zookeeper安装 ...
- zookeeper+kafka集群安装之一
zookeeper+kafka集群安装之一 准备3台虚拟机, 系统是RHEL64服务版. 1) 每台机器配置如下: $ cat /etc/hosts ... # zookeeper hostnames ...
- zookeeper+kafka集群安装之中的一个
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/cheungmine/article/details/26678877 zookeeper+kafka ...
- CentOS6安装各种大数据软件 第五章:Kafka集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- KafKa集群安装、配置
一.事前准备 1.kafka官网:http://kafka.apache.org/downloads. 2.选择使用版本下载. 3.kafka集群环境准备:(linux) 192.168.145.12 ...
- Kafka集群安装Version1.0.1(自带Zookeeper)
1.说明 Kafka集群安装,基于版本1.0.1, 使用kafka_2.12-1.0.1.tgz安装包, 其中2.12是编译工具Scala的版本. 而且不需要另外安装Zookeeper服务, 使用Ka ...
随机推荐
- 洛谷P3939 数颜色 二分查找
正解:二分 解题报告: 传送门! 话说其实我开始看到这题想到的是分块,,, 但是显然不用这么复杂,,,因为仔细看下这题,会发现每次只改变相邻的兔子的位置 所以开个vector(或者开个数组也成QwQ( ...
- 【我的Android进阶之旅】解决AndroidStudio编译时报错:Timeout waiting to lock artifact cache .
1. 错误描述 今天在Android Studio中,使用gradle命令的时候,出现了如下所示的错误: D:\GitLab Source\XTCLint>gradlew clean uploa ...
- DHCP服务器配置实践
实验背景:在LINUX系统上为一园区网络配置DHCP服务器,给网络内各主机自动分配IP地址,地址池范围为:192.168.X.100~192.168.X.200,配置作用域选项,其中网关为:192.1 ...
- Python3.x:os.path模块
Python3.x:os.path模块 #返回绝对路径 os.path.abspath(path) #返回文件名 os.path.basename(path) #返回list(多个路径)中,所有pat ...
- 20155201 2016-2017-2 《Java程序设计》第一周学习总结
20155201 2016-2017-2 <Java程序设计>第一周学习总结 教材学习内容总结 每一章的问题: 第一章 Java ME都有哪些成功的平台? 第二章 哪些情况可以使用impo ...
- Java实现:数据结构之排序
Java实现:数据结构之排序 0.概述 形式化定义:假设有n个记录的序列(待排序列)为{ R1, R2 , -, Rn },其相应的关键字序列为 { K1, K2, -, Kn }.找到{1,2, - ...
- Applet再学习
ZLYD团队Apllet学习笔记 Applet再学习 Applet是什么? Applet又称为Java小应用程序,是能够嵌入到一个HTML页面中,并且可通过Web浏览器下载和执行的一种Java类 .A ...
- linux kernel 卡在提示信息Waiting for root device /dev/mmcblk0p1...处
一.背景 1.1 移植linux-4.14内核的过程中,此时使用的是ext4文件系统,并且将根文件系统存储在sd卡的第一个分区上 1.2 内核打印完Waiting for root device /d ...
- enum SQLiteDateFormats
DateTimeFormatInfo.CurrentInfo https://msdn.microsoft.com/en-us/library/system.globalization.datetim ...
- cf 429 B Working out
B. Working out time limit per test 2 seconds memory limit per test 256 megabytes input standard inpu ...