【大数据系列】HDFS文件权限和安全模式、安装
HDFS文件权限
1、与linux文件权限类型
r:read w:write x:execute权限x对于文件忽略,对于文件夹表示是否允许访问其内容
2、如果linux系统用户sanglp使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是sanglp
3、HDFS的权限目的:阻止好人做错事,而不是阻止坏人做坏事。
安全模式
1、 namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
2、 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一个空的编辑日志。
3、 此刻namenode运行在安全模式。即namenode的文件系统对于客户端来说是只读的(显示目录、显示文件内容等。写、删除、重命名都会失败)
4、 在此阶段Namenode手机各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的,在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
5、 当检测到副本数不足的数据块时,该块会被复制直到最小副本数,系统中数据块的位置并不是由namenode维护的,而是以块列表示形式存储在datanode中。
HDFS安装
1、 伪分布式安装
2、 完全分布式安装
- 下载
- 解压
- 检查java和ssh的免密码登陆
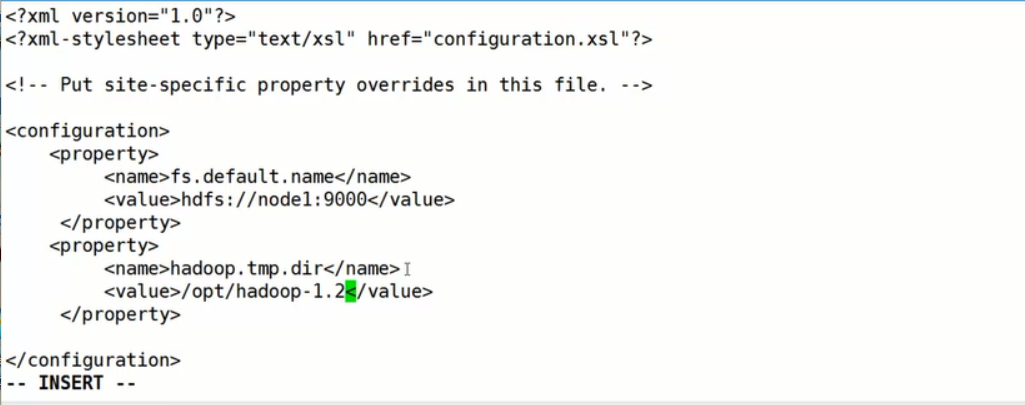
- 修改core-site.xml
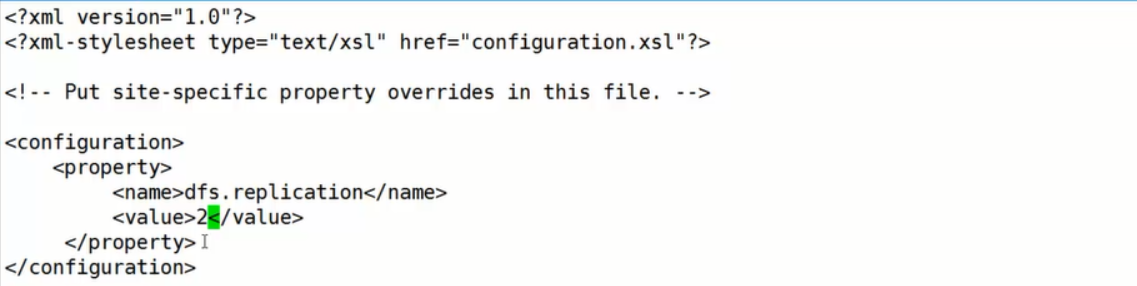
- 修改hdfs-site.xml
- 修改master文件和slaves文件
- 格式化namenode
- start-hdfs.sh启动
3、 按照文档安装
编辑core-site.xml (默认core-default.xml里有使用到的变量 fs.default.name配置的是NameNode的主机和入口)
编辑hdfs-site.xml(副本数是小于或等于DataNode的节点数的 hdfs-default.xml)
编辑slaves(配置datanode的ip信息)
修改masters(配置secondary NameNode 配置主机名或ip )
配置免密登陆是为了在任何一台机器上可以操作所有的节点
只启动hdfs的时候使用start-dfs.sh
需要在hadoop/conf/Hadoop-env.sh中配置JAVA_HOME
如果namenode启动的时候显示别的dataNode已经启动,但是别的主机上jps没有启动则关闭防火墙重新启动。
之后访问http://node1:50070查看详情NameNode DataNode等信息
【大数据系列】HDFS文件权限和安全模式、安装的更多相关文章
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- 【大数据系列】win10不借助Cygwin安装hadoop2.8
一.下载安装包 解压安装包并创建data,name,tmp文件夹 二.修改配置文件 1.core-site.xml <?xml version="1.0" encoding= ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
随机推荐
- 详细分析Java中断机制[转]
1. 引言 当我们点击某个杀毒软件的取消按钮来停止查杀病毒时,当我们在控制台敲入quit命令以结束某个后台服务时……都需要通过一个线程去取消另一个线程正在执行的任务.Java没有提供一种安全直接的方法 ...
- LigerUI编辑表格组件单元格校验问题
这几天在使用LigerUI(版本为1.2.2)编辑表格组件的时候,遇到几个小问题,从官方demo和api中没有找到解决的办法 问题1.从数据库查询出来的主键单元格不可编辑问题 主键单元格已经保存之前编 ...
- 9款极具创意的HTML5/CSS3进度条动画
今天我们要分享9款极具创意的HTML5/CSS3进度条动画,这些进度条也许可以帮你增强用户交互和提高用户体验,喜欢的朋友就收藏了吧. 1.HTML5/CSS3图片加载进度条 可切换多主题 今天要分享的 ...
- SVN中图标符号的含义
黄色感叹号(有冲突): 这是有冲突了,冲突就是说你对某个文件进行了修改,别人也对这个文件进行了修改,别人抢在你提交之前先提交了,这时你再提交就会被提示发生冲突,而不允许你提交,防止你的提交覆盖了别人的 ...
- Objc将数据写入iOS真机的plist文件里
大熊猫猪·侯佩原创或翻译作品.欢迎转载,转载请注明出处. 假设认为写的不好请多提意见,假设认为不错请多多支持点赞.谢谢! hopy ;) 怎样写入模拟器的博文在 这里 可是这对真机无论用,由于在真机环 ...
- js scrollIntoViewIfNeeded
根据 MDN的描述,Element.scrollIntoView()方法让当前的元素滚动到浏览器窗口的可视区域内. 而Element.scrollIntoViewIfNeeded()方法也是用来将不在 ...
- asp.net单击头模板中的checkbox,实现datalist中所有chebox的全选和取消
转载时请以超链接形式标明文章原始出处和作者信息及本声明http://blueseach.blogbus.com/logs/31281126.html 使用C#和javascript都可以实现,第二种更 ...
- gcc 高版本兼容低版本 技巧 :指定 -specs={自定义specs文件} 参数。可以搞定oracle安装问题
如: #!/bin/sh /usr/bin/gcc-7 -specs=/usr/lib/gcc/x86_64-linux-gnu/jin.spec $* 该技巧很实用.这么久才发现,唉,不是专业搞某个 ...
- Java 多线程编程知识详解
Java 给多线程编程提供了内置的支持.一个多线程程序包含两个或多个能并发运行的部分.程序的每一部分都称作一个线程,并且每个线程定义了一个独立的执行路径. 多线程是多任务的一种特别的形式,但多线程使用 ...
- 放假前来个笑话:IT人士群聚喝酒的讲究(超级搞笑)
大家喝的是啤酒,这时你入座了…… 你给自己倒了杯可乐,这叫低配置. 你给自已倒了杯啤酒,这叫标准配置. 你给自己倒了杯茶水,这茶的颜色还跟啤酒一样,这叫木马. 你给自己倒了杯可乐,还滴了几滴醋,不仅颜 ...