MySQL架构总览->查询执行流程->SQL解析顺序
Reference: https://www.cnblogs.com/annsshadow/p/5037667.html
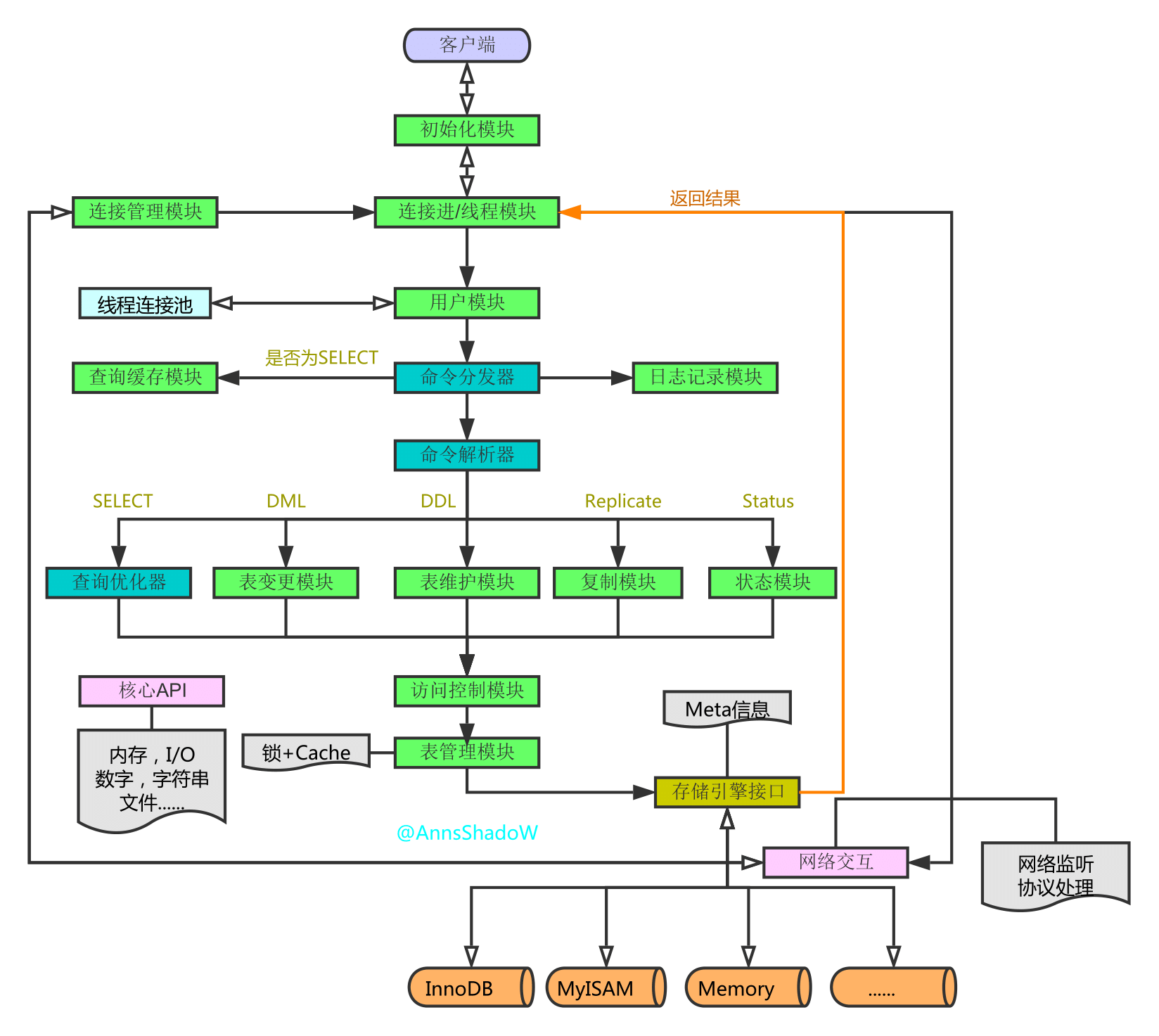

SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)

MySQL架构总览->查询执行流程->SQL解析顺序的更多相关文章
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
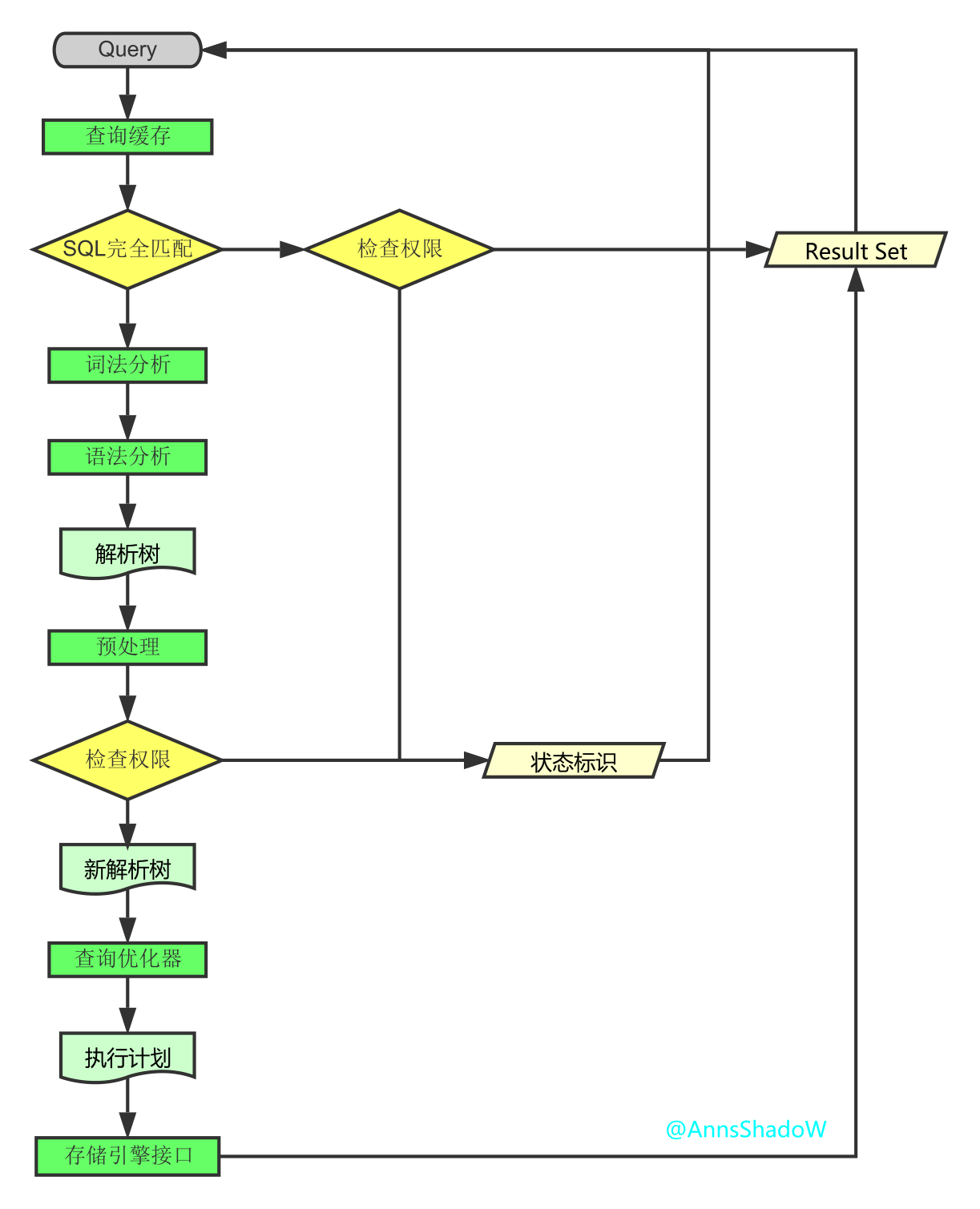
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序(转)
文章转自 http://www.cnblogs.com/annsshadow/p/5037667.html https://www.cnblogs.com/cuisi/p/7685893.html
- 步步深入MySQL:架构->查询执行流程->SQL解析顺序!
一.前言 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序 ...
- 让MySQL为我们记录执行流程
让MySQL为我们记录执行流程 我们可以开启profiling,让MySQL为我们记录SQL语句的执行流程 查看profiling参数 shell > select @@profilin ...
- mysql join语句的执行流程是怎么样的
mysql join语句的执行流程是怎么样的 join语句是使用十分频繁的sql语句,同样结果的join语句,写法不同会有非常大的性能差距. select * from t1 straight_joi ...
- SQL学习笔记四(补充-1-1)之MySQL单表查询补充部分:SQL逻辑查询语句执行顺序
阅读目录 一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析 一 SELECT语句关键字的定义顺序 SELE ...
- MySQL深层理解,执行流程
MySQL是一个关系型数据库,关联的数据保存在不同的表中,增加了数据操作的灵活性. 执行流程 MySQL是一个单进程服务,每一个请求用线程来响应, 流程: 1,客户请求,服务器开辟一个线程响应用户. ...
- Spark架构与作业执行流程简介(scala版)
在讲spark之前,不得不详细介绍一下RDD(Resilient Distributed Dataset),打开RDD的源码,一开始的介绍如此: 字面意思就是弹性分布式数据集,是spark中最基本的数 ...
- scrapy架构图与执行流程
概览 本文描述了Scrapy的架构图.数据流动.以及个组件的相互作用 架构图与数据流 上图中各个数字与箭头代表数据的流动方向和流动顺序,具体执行流程如下: 0. Scrapy将会实例化一个Crawle ...
随机推荐
- CSS选择器、样式、盒模型
一.CSS基础选择器 # 1.*(通配选择器):html,body以及body下用于显示的标签 #html和body颜色会被改变,但是div标签不会发生改变,由于不同的选择器具有优先级 # 语法:* ...
- JAVA的8种基本数据类型和类型转换
byte 字节型 1字节(8bit) 初始值:0 char 字符型 2字节 空格 short 短整型 2字节 0 int 整形 4字节 0 long ...
- MySQL连接缓慢,打开缓慢原因
问题状况:最近由于服务器变换了网段,导致IP地址变换,变化后使用MySQL客户端连接MySQL服务器和在客户端中打开表的速度非常慢(无论表的大小),甚至连接超时,但是直接登录到服务器在本地连接MySQ ...
- C Windows控制台字符版本俄罗斯方块
//一个可以工作在Windows控制台字符界面下的俄罗斯方块 //工作在非图形模式,无需其他库依赖,单个C文件代码即可运行 //支持最高纪录,并且对于纪录进行了加密 //By wrule 2015年1 ...
- shell脚本使用技巧3--函数调用
定义函数 function fname() { statements; } 或者 fname() { statements; } 传递参数给函数: fname arg1 arg2; ex: 函数参数定 ...
- ZKW线段树入门
Part 1 来说说它的构造 线段树的堆式储存 我们来转成二进制看看 小学生问题:找规律 规律是很显然的 一个节点的父节点是这个数左移1,这个位运算就是低位舍弃,所有数字左移一位 一个节点的子节点是这 ...
- tarjan求双联通分量(割点,割边)
之前一直对tarjan算法的这几种不同应用比较混淆...我太弱啦! 被BLO暴虐滚过来 用tarjan求点双,很多神犇都给出了比较详细的解释和证明,在这里就不讲了(其实是这只蒟蒻根本不会orz) 这里 ...
- centos 7 之nginx
环境信息 [root@node1 ~]# cat /etc/redhat-release CentOS Linux release (Core) [root@node1 ~]# uname -r -. ...
- Myeclispe 代码自动补全
1.Myeclispe—>Preference 2.Java->Editor->Content Assist 3.Auto activation for java 补全(.abcde ...
- JAVA自学笔记10
JAVA自学笔记10 1.形式参数与返回值 1)类名作为形式参数(基本类型.引用类型) 作形参必须是类的对象 2)抽象类名作形参 需要该抽象类的子类对象,通过多态实现 3)接口名为形参 需要的是该接口 ...