JDK1.7 ConcurrentHashMap--解决高并发下的HashMap使用问题
高并发下也可以使用HashTable 、Collections.synchronizedMap因为他们是线程安全的,但是却牺牲了性能,无论是读操作、写操作都是给整个集合加锁,导致同一时间内其他操作均为之阻塞。
ConcurrentHashMap则兼容了安全和效率问题。
ConcurrentHashMap的Segment概念:
Segment是什么呢?Segment本身就相当于一个HashMap对象。
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
单一的Segment结构如下:
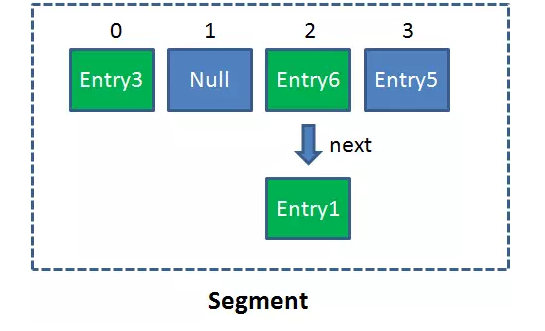
像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组当中。
因此整个ConcurrentHashMap的结构如下:

可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
这样的二级结构,和数据库的水平拆分有些相似。
ConcurrentHashMap采用了“锁分段技术”,每个segment就是一个区,读写操作高度自治,互相不干涉。
Case1:不同Segment的并发写入
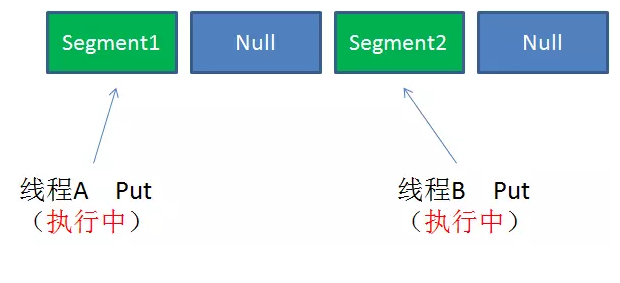
不同Segment的写入是可以并发执行的。
Case2:同一Segment的一写一读

同一Segment的写和读是可以并发执行的。
Case3:同一Segment的并发写入
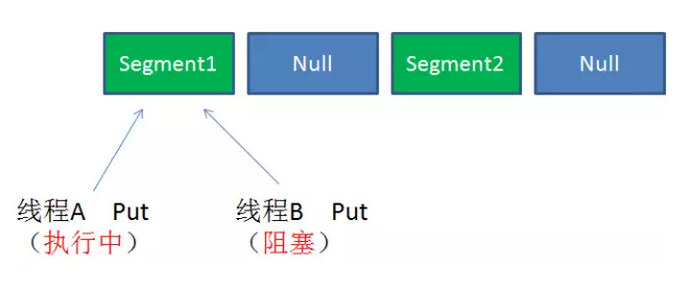
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
每个Segment都各自加锁,返回size怎么保持一致性?
Size方法的目的是统计ConcurrentHashMap的总元素数量, 自然需要把各个Segment内部的元素数量汇总起来。
但是,如果在统计Segment元素数量的过程中,已统计过的Segment瞬间插入新的元素,这时候该怎么办呢?
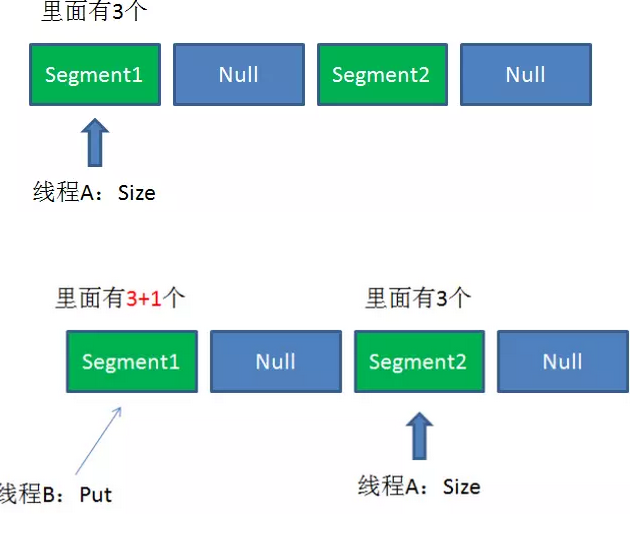

ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
官方源代码如下:
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
为什么这样设计呢?这种思想和乐观锁悲观锁的思想如出一辙。
为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。
JDK1.7 ConcurrentHashMap--解决高并发下的HashMap使用问题的更多相关文章
- 对HashMap的理解(二):高并发下的HashMap
在分析hashmap高并发场景之前,我们要先搞清楚ReHash这个概念.ReHash是HashMap在扩容时的一个步骤.HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和 ...
- PHP+Redis链表解决高并发下商品超卖问题
目录 实现原理 实现步骤 上一篇文章聊了一下使用Redis事务来解决高并发商品超卖问题,今天我们来聊一下使用Redis链表来解决高并发商品超卖问题. 实现原理 使用redis链表来做,因为pop操作是 ...
- JDK1.7 高并发下的HashMap
HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高. 这时候,HashMap需要扩展它的长度,也就是进行Resize. 影响发 ...
- 高并发下的HashMap,ConcurrentHashMap
参照: http://mp.weixin.qq.com/s/dzNq50zBQ4iDrOAhM4a70A http://mp.weixin.qq.com/s/1yWSfdz0j-PprGkDgOomh ...
- python 如何解决高并发下的库存问题??
python 提供了2种方法解决该问题的问题:1,悲观锁:2,乐观锁 悲观锁:在查询商品储存的时候加锁 select_for_update() 在发生事务的commit或者是事务的rollback时 ...
- redis解决高并发下脏读问题
//解决并发情况下卡脏读的问题 protected function BingFa($mobile, $ent_id){ $obj = EnterpriseMembers::getNewMemberC ...
- 高并发下,HashMap会产生哪些问题?
HashMap在高并发环境下会产生的问题 HashMap其实并不是线程安全的,在高并发的情况下,会产生并发引起的问题: 比如: HashMap死循环,造成CPU100%负载 触发fail-fast 下 ...
- 漫画:高并发下的HashMap
这一期我们来讲解高并发环境下,HashMap可能出现的致命问题. HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高. 这时候 ...
- [Redis] - 高并发下Redis缓存穿透解决
高并发情况下,可能都要访问数据库,因为同时访问的方法,这时需要加入同步锁,当其中一个缓存获取后,其它的就要通过缓存获取数据. 方法一: 在方法上加上同步锁 synchronized //加同步锁,解决 ...
随机推荐
- Android开发 ---构建对话框Builder对象,消息提示框、列表对话框、单选提示框、多选提示框、日期/时间对话框、进度条对话框、自定义对话框、投影
效果图: 1.activity_main.xml 描述: a.定义了一个消息提示框按钮 点击按钮弹出消息 b.定义了一个选择城市的输入框 点击按钮选择城市 c.定义了一个单选提示框按钮 点击按钮选择某 ...
- 使用json改写网站
效果图 json文件 https://raw.githubusercontent.com/sherryloslrs/timetable/master/timetable.json { "Ti ...
- 一个class标签里面有多个属性时的提取标签
<div class="uibox-con carpic-list03 border-b-solid"> #即这个标签同时满足三个class:“uibox”.“ca ...
- 剑指Offer 32. 把数组排成最小的数 (数组)
题目描述 输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个.例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323. 题目地址 h ...
- Vue+WebSocket 实现页面实时刷新长连接
最近vue项目要做数据实时刷新,折线图每秒重画一次,数据每0.5秒刷新一次,说白了就是实时刷新,因为数据量较大,用定时器估计页面停留一会就会卡死... 与后台人员讨论过后决定使用h5新增的WebSoc ...
- 单例模式demo
package com.test; /** * * @author Administrator *我的发现:调用这个的时候,不能直接实例化了;需要=null;然后get; 这样安全些; *然后仔细找了 ...
- 面试题 -AR VR MR以及CR的简单介绍
AR 增强现实技术(Augmented Reality,简称 AR),是一种实时地计算摄影机影像的位置及角度并加上相应图像.视频.3D模型的技术,这种技术的目标是在屏幕上把虚拟世界套在现实世界并进行互 ...
- cmd运行jar
https://blog.csdn.net/lemon_tree12138/article/details/44081909 https://www.cnblogs.com/LanTianYou/p/ ...
- 20155208徐子涵 《网络对抗》Exp1 PC平台逆向破解
20155208徐子涵 <网络对抗>Exp1 PC平台逆向破解 实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数 ...
- 仿QQ菜单栏:消息,电话菜单
转载自:http://blog.csdn.net/johnnyz1234/article/details/45919907 在实际项目开发使用Fragment的时候,也碰到一些异常和存在的问题,下面做 ...