DBScan聚类,打破形状的限制,使用密度聚类
如何用花盆摆放成国庆字,并且包围这两个字。
在DBSCAN中衡量密度主要使用的指标:半径、最少样本量
算法原理
*直接密度可达
如果一个点在核心对象的半径区域内,那么这个点和核心对象称为直接密度可达,比如A和B,B和C等
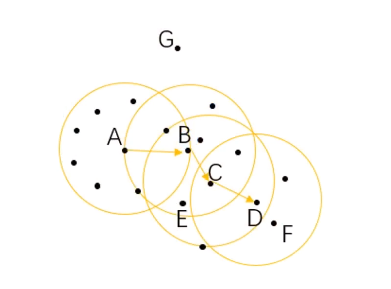
图1
*密度可达
如果有一系列点,都满足上一个点到这个点都是密度直达,那么这个系列中不相邻的点就称为密度可达,比如上图1中A和D。另外下图2也是有解释的
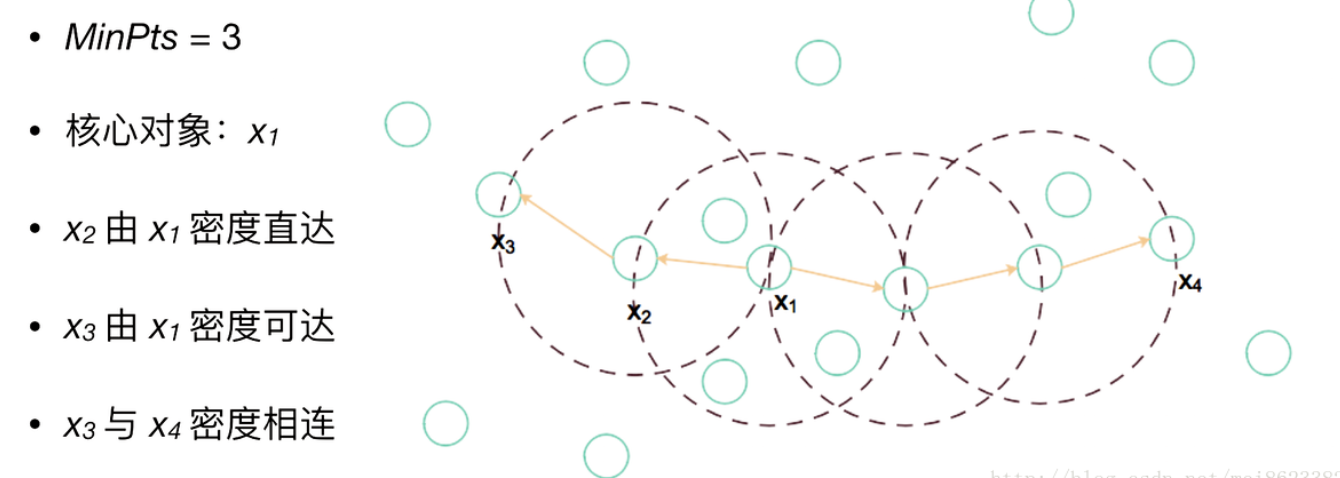
图2
*密度相连
如果通过一个核心对象出发,得到两个密度可达的点,那么这两个点称为密度相连,比如图1中E和F
经过初始化后,从整个样本集中去抽取样本点
如果这个样本点是核心对象,那么从这个点出发,找到所有密度可达的对象,构成一个簇
如果这个样本点不是核心对象,那么再重新找下一个点
算法优点
不需要划分个数(只需要计算)
可以处理噪点
可以处理任何形状的空间聚类问题
算法缺点
需要指定最小样本量和半径两个参数
数量大时开销也很大
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量比较差
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import dbscan #生成500个点,噪声为0.1
X,_=datasets.make_moons(500,noise=0.1,random_state=1) df=pd.DataFrame(X,columns=['x','y'])
df.plot.scatter('x','y',s=200,alpha=0.5,c="green",title='dataset by DBSCAN')
plt.show()

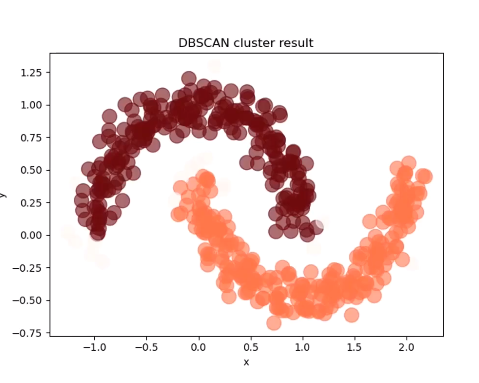
生成的绿色结果
#eps为邻域半径,min_samples为最少样本量
core_samples,cluster_ids=dbscan(X,eps=0.2,min_samples=20)
#cluster_ids中-1表示对应的点为噪声
df=pd.DtaFrame(np.c_[X,cluster_ids],columns=['x','y','cluster_id'])
df['cluster_id']=df['cluster_id'].astype('i2') #绘制结果图像
df.plot.scatter('x','y',s=200,
c=list(df['scatter_id']),cmap='Reds',colorbar=False,
alpha=0.6,title='DBSCAN cluster result')
plt.show()
DBScan聚类,打破形状的限制,使用密度聚类的更多相关文章
- 聚类——密度聚类DBSCAN
Clustering 聚类 密度聚类——DBSCAN 前面我们已经介绍了两种聚类算法:k-means和谱聚类.今天,我们来介绍一种基于密度的聚类算法——DBSCAN,它是最经典的密度聚类算法,是很多算 ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- DBSCAN密度聚类
1. 密度聚类概念 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密 ...
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- 【转】DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 31(1).密度聚类---DBSCAN算法
密度聚类density-based clustering假设聚类结构能够通过样本分布的紧密程度确定. 密度聚类算法从样本的密度的角度来考察样本之间的可连接性,并基于可连接样本的不断扩张聚类簇,从而获得 ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 密度聚类 - DBSCAN算法
参考资料:python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan import numpy as np from sklearn.cluster impo ...
随机推荐
- go http 中间件
- SpringBoot 自定义配置
有时候需要自己定义一些配置,比如SpringBoot没有提供Druid连接池的配置,需要我们自己写配置. 以在springboot中使用Druid为例. 依赖 <dependency> & ...
- JAVA多线程学习- 三:volatile关键字
Java的volatile关键字在JDK源码中经常出现,但是对它的认识只是停留在共享变量上,今天来谈谈volatile关键字. volatile,从字面上说是易变的.不稳定的,事实上,也确实如此,这个 ...
- 基于Apache的Tomcat负载均衡和集群(2)
反向代理负载均衡 (Apache+JK+Tomcat) 使用代理服务器可以将请求转发给内部的Web服务器,让代理服务器将请求均匀地转发给多台内部Web服务器之一上,从而达到负载均衡的目的.这种代理方式 ...
- Net6 DI源码分析Part3 CallSiteRuntimeResolver,CallSiteVisitor
CallSiteRuntimeResolver CallSiteRuntimeResolver是实现了CallSiteVisitor之一. 提供的方法主要分三个部分 自有成员方法 Resolve提供服 ...
- 第2章 selenium开发环境的搭建
前端技术: html:网页的基础,一种标记语言,显示数据: JS:前端脚本语言,解释型语言,在页面中添加交互行为 xml:扩展标记语言,用来传输和存储数据 css:层叠样式表,用来表现HTML或XML ...
- Solution -「CF 923E」Perpetual Subtraction
\(\mathcal{Description}\) Link. 有一个整数 \(x\in[0,n]\),初始时以 \(p_i\) 的概率取值 \(i\).进行 \(m\) 轮变换,每次均匀随机 ...
- 通过shell脚本统计elasticsearch indices每天的数量以及大小
前情提要: 最近elasticsearch集群总出问题,之前虽然修复了,现在又出现新的问题,于是PM要求拉取elasticsearch每天建立的索引有多少,索引有多大,需要对机器进行评估 客户现场无法 ...
- 利用信号量semaphore实现两个进程读写同步 Linux C
这篇帖子主要是记录一下自己使用信号量遇到的坑. 首先是需求:创建两个进程A,B.A往buffer中写,B读.两个进程利用命名管道进行通信,并实现读写同步.即A写完后通知B读,B读完后通知A写. 如果A ...
- 设置maven创建工程的jdk编译版本
方式一:在maven的主配置文件中指定创建工程时使用jdk1.8版本 <profile> <id>jdk-1.8</id> <activation> & ...