spark 集群优化
只有满怀自信的人,能在任何地方都怀有自信,沉浸在生活中,并认识自己的意志。
前言
最近公司有一个生产的小集群,专门用于运行spark作业。但是偶尔会因为nn或dn压力过大而导致作业checkpoint操作失败进而导致spark 流任务失败。本篇记录从应用层面对spark作业进行优化,进而达到优化集群的作用。
集群使用情况
有数据的目录以及使用情况如下:
|
目录
|
说明
|
大小
|
文件数量
|
数据数量占比
|
数据大小占比
|
|---|---|---|---|---|---|
| /user/root/.sparkStaging/applicationIdxxx | spark任务配置以及所需jar包 | 5G | 约1k | 约20% | 约100% |
| /tmp/checkpoint/xxx/{commits|metadata|offsets|sources} | checkpoint文件,其中commits和offsets频繁变动 | 2M | 约4k | 约80% | 约0% |
对于.sparkStaging目录,不经常变动,只需要优化其大小即可。
对于 checkpoint目录,频繁性增删,从生成周期和保留策略两方面去考虑。
.sparkStaging目录优化
对于/user/root/.sparkStaging下文件,是spark任务依赖文件,可以将jar包上传到指定目录下,避免或减少了jar包的重复上传,进而减少任务的等待时间。
可以在spark的配置文件spark-defaults.conf配置如下内容:
spark.yarn.archive=hdfs://hdfscluster/user/hadoop/jars
spark.yarn.preserve.staging.files=false
参数说明
|
Property Name
|
Default
|
Meaning
|
|---|---|---|
| spark.yarn.archive | (none) | An archive containing needed Spark jars for distribution to the YARN cache. If set, this configuration replaces spark.yarn.jars and the archive is used in all the application's containers. The archive should contain jar files in its root directory. Like with the previous option, the archive can also be hosted on HDFS to speed up file distribution. |
| spark.yarn.preserve.staging.files | false | Set to true to preserve the staged files (Spark jar, app jar, distributed cache files) at the end of the job rather than delete them. |
checkpoint优化
首先了解一下 checkpoint文件代表的含义。
checkpoint文件说明
offsets 目录 - 预先记录日志,记录每个批次中存在的偏移量。为了确保给定的批次将始终包含相同的数据,我们在进行任何处理之前将其写入此日志。因此,该日志中的第N个记录指示当前正在处理的数据,第N-1个条目指示哪些偏移已持久地提交给sink。
commits 目录 - 记录已完成的批次ID的日志。这用于检查批处理是否已完全处理,并且其输出已提交给接收器,因此无需再次处理。(例如)在重新启动过程中使用,以帮助识别接下来要运行的批处理。
metadata 文件 - 与整个查询关联的元数据,只有一个 StreamingQuery 唯一ID
sources目录 - 保存起始offset信息
下面从两个方面来优化checkpoint。
第一,从触发checkpoint机制方面考虑
trigger的机制
Trigger是用于指示 StreamingQuery 多久生成一次结果的策略。
Trigger有三个实现类,分别为:
OneTimeTrigger - A Trigger that processes only one batch of data in a streaming query then terminates the query.
ProcessingTime - A trigger that runs a query periodically based on the processing time. If
intervalis 0, the query will run as fast as possible.by default,trigger isProcessingTime, andinterval=0
ContinuousTrigger - A Trigger that continuously processes streaming data, asynchronously checkpointing at the specified interval.
可以为 ProcessingTime 指定一个时间 或者使用 指定时间的ContinuousTrigger ,固定生成checkpoint的周期,避免checkpoint生成过于频繁,减轻多任务下小集群的nn的压力
第二,从checkpoint保留机制考虑。
保留机制
spark.sql.streaming.minBatchesToRetain - 必须保留并使其可恢复的最小批次数,默认为 100
可以调小保留的batch的次数,比如调小到 20,这样 checkpoint 小文件数量整体可以减少到原来的 20%
checkpoint 参数验证
主要验证trigger机制和保留机制
验证trigger机制
未设置trigger效果
未设置trigger前,spark structured streaming 的查询batch提交的周期截图如下:
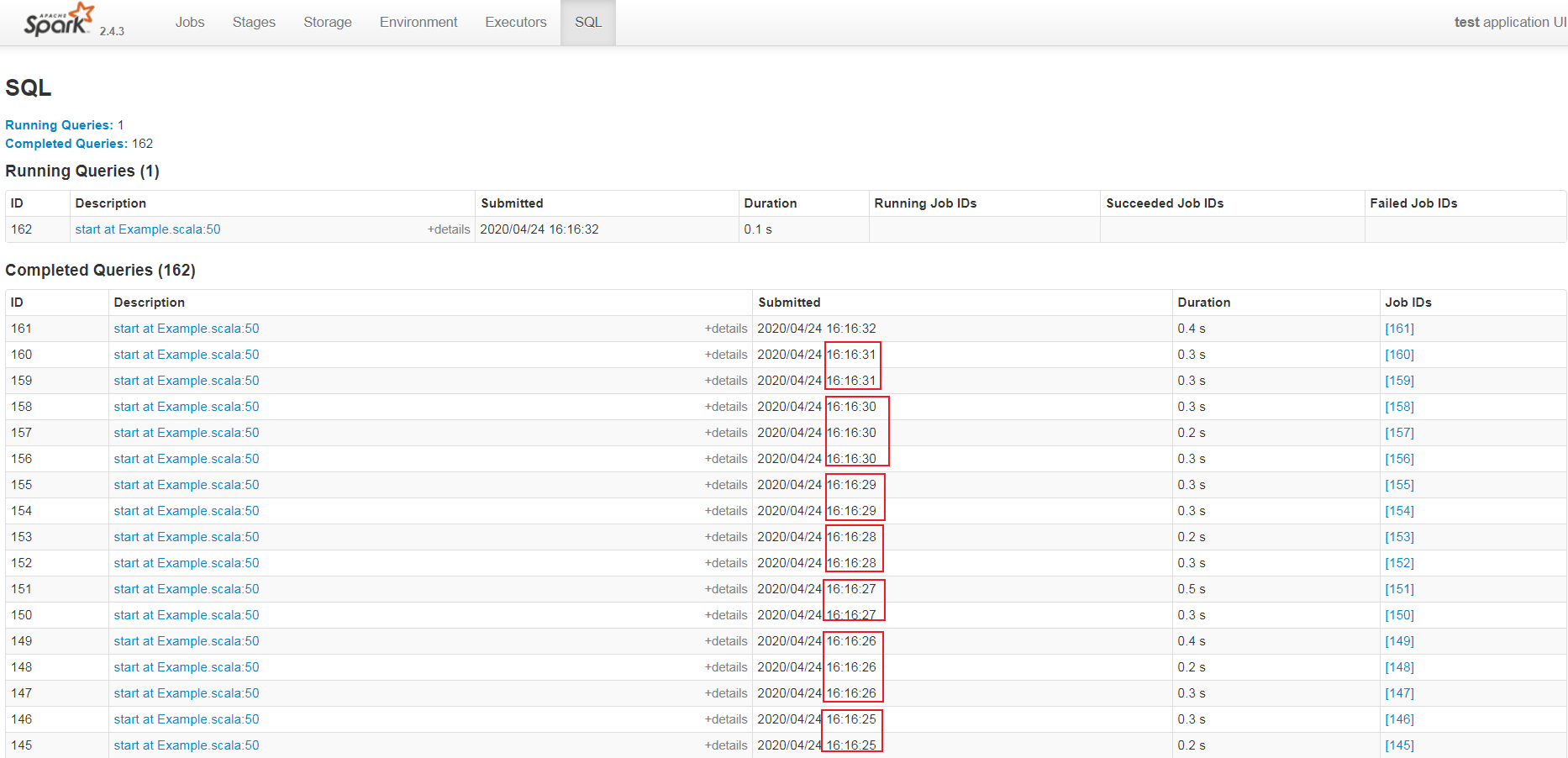
每一个batch的query任务的提交是毫无周期规律可寻。
设置trigger代码
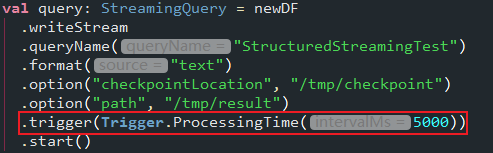
trigger效果
设置trigger代码后效果截图如下:
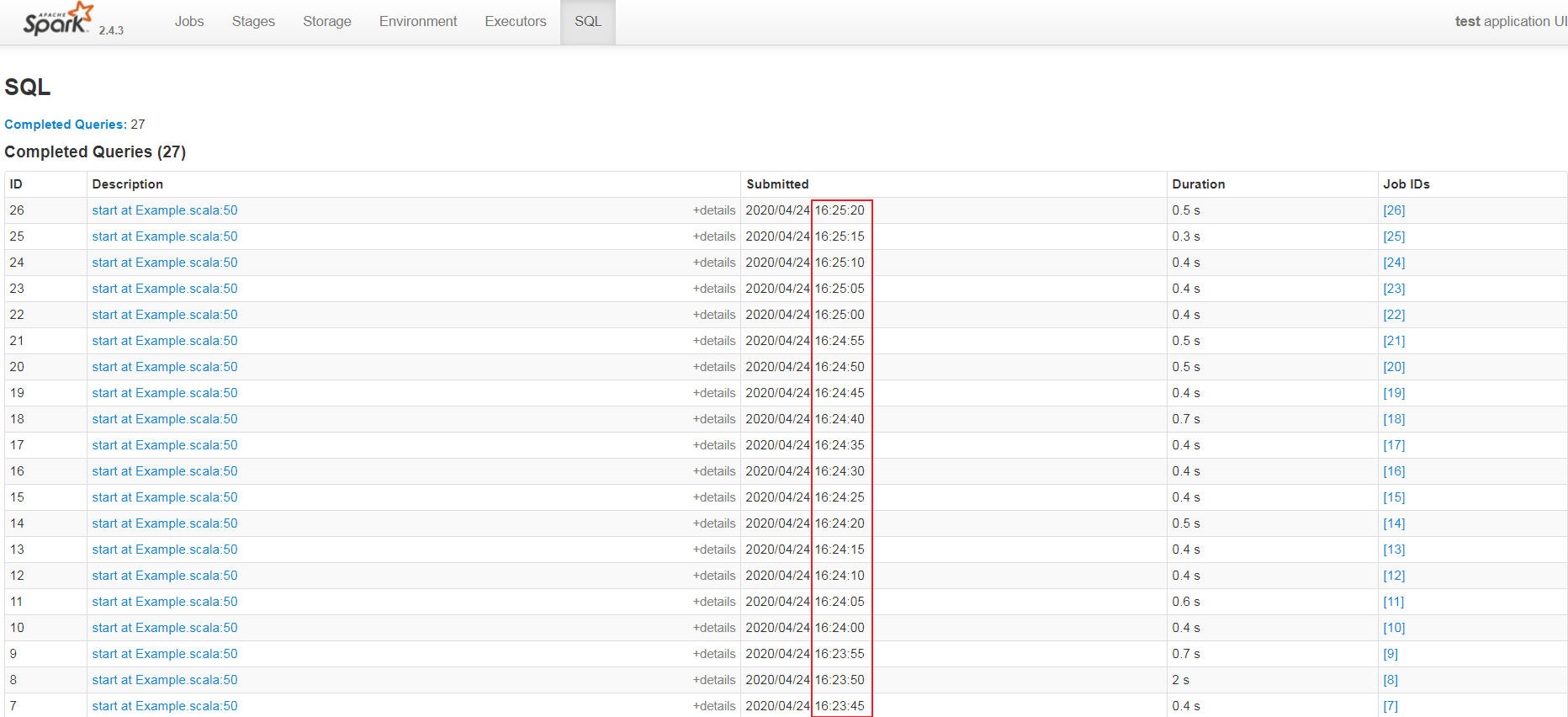
每一个batch的query任务的提交是有规律可寻的,即每隔5s提交一次代码,即trigger设置生效!
注意,如果消息不能马上被消费,消息会有积压,structured streaming 目前并无与spark streaming效果等同的背压机制,为防止单批次query查询的数据源数据量过大,避免程序出现数据倾斜或者无法挽回的OutOfMemory错误,可以通过 maxOffsetsPerTrigger 参数来设置单个批次允许抓取的最大消息条数。
使用案例如下:
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "xxx:9092")
.option("subscribe", "test-name")
.option("startingOffsets", "earliest")
.option("maxOffsetsPerTrigger", 1)
.option("group.id", "2")
.option("auto.offset.reset", "earliest")
.load()
验证保留机制
默认保留机制效果
spark任务提交参数
#!/bin/bash
spark-submit \
--class zd.Example \
--master yarn \
--deploy-mode client \
--packages org.apache.spark:spark-sql-kafka--10_2.:2.4.,org.apache.kafka:kafka-clients:2.0. \
--repositories http://maven.aliyun.com/nexus/content/groups/public/ \
/root/spark-test-1.0-SNAPSHOT.jar
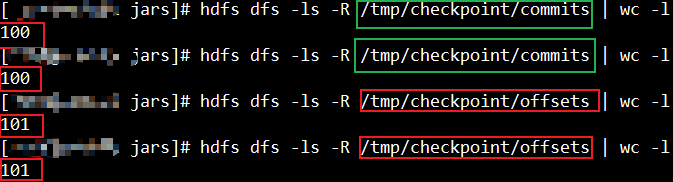
如下图,offsets和commits最终最少各保留100个文件。
修改保留策略
通过修改任务提交参数来进一步修改checkpoint的保留策略。
添加 --conf spark.sql.streaming.minBatchesToRetain=2 ,完整脚本如下:
#!/bin/bash
spark-submit \
--class zd.Example \
--master yarn \
--deploy-mode client \
--packages org.apache.spark:spark-sql-kafka--10_2.:2.4.,org.apache.kafka:kafka-clients:2.0. \
--repositories http://maven.aliyun.com/nexus/content/groups/public/ \
--conf spark.sql.streaming.minBatchesToRetain= \
/root/spark-test-1.0-SNAPSHOT.jar
修改后保留策略效果
修改后保留策略截图如下:
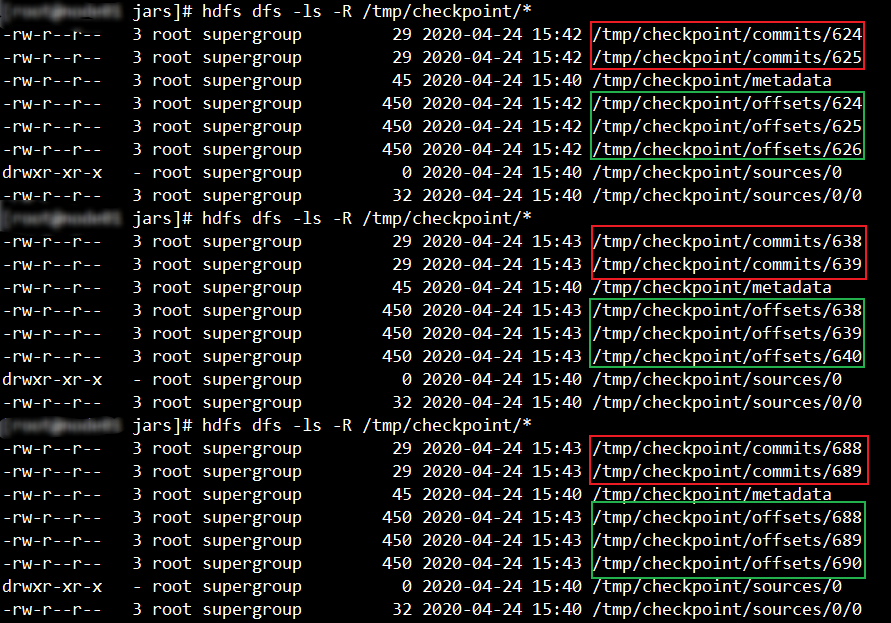
即 checkpoint的保留策略参数设置生效!
总结
综上,可以通过设置 trigger 来控制每一个batch的query提交的时间间隔,可以通过设置checkpoint文件最少保留batch的大小来减少checkpoint小文件的保留个数。
参照
- https://github.com/apache/spark/blob/master/docs/running-on-yarn.md
- https://blog.csdn.net/lm709409753/article/details/85250859
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousExecution.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/streaming/ProcessingTime.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousTrigger.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
spark 集群优化的更多相关文章
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 【Spark-core学习之三】 Spark集群搭建 & spark-shell & Master HA
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库.整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因. 发现: 集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫 ...
- Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等.并且已经安装好了hadoop集群. 如果还没有配置好的,参考我前面两篇博客: Spark集群环境搭建--服务器环境初始化:htt ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- Spark集群部署
Spark是通用的基于内存计算的大数据框架,可以和hadoop生态系统很好的兼容,以下来部署Spark集群 集群环境:3节点 Master:bigdata1 Slaves:bigdata2,bigda ...
- Spark集群 + Akka + Kafka + Scala 开发(3) : 开发一个Akka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
随机推荐
- 如何删除Python中文本文件的文件内容?
在python中: open('file.txt', 'w').close() 或者,如果你已经打开了一个文件: f = open('file.txt', 'r+') f.truncate(0) # ...
- C 实战练习题目1
题目:有1.2.3.4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少? 程序分析:可填在百位.十位.个位的数字都是1.2.3.4.组成所有的排列后再去 掉不满足条件的排列. 实例: #in ...
- 模块 time datetime 时间获取和处理
模块_time 和时间有关系的我们就要用到时间模块.在使用模块之前,应该首先导入这个模块. 1 延时 time.sleep(secs) (线程)推迟指定的时间运行.单位为秒. 2 获取当前时间戳tim ...
- 文件上传 Window & Linux
1. 在application配置文件添加图片存储路径的参数 上传路径前必须加 file:/ 否则网页图片请求可能404window gofy: uploadPath: file:/F:/fileUp ...
- NCEP CFSR数据读取
一. NCEP CFSR再分析数据,时间分辨率是1小时. 1.整体读取数据情况 clear all setup_nctoolbox tic %% 读取数据文件 wind= ncgeodataset(' ...
- 【WPF学习】第六十二章 构建更复杂的模板
在控件模板和为其提供支持的代码之间又一个隐含约定.如果使用自定义控件模板替代控件的标准模板,就需要确保新模板能够满足控件的实现代码的所有需要. 在简单控件中,这个过程比较容易,因为对模板几乎没有(或完 ...
- Blazor入门笔记(5)-数据绑定
1.环境 VS2019 16.5.1 .NET Core SDK 3.1.200 Blazor WebAssembly Templates 3.2.0-preview2.20160.5 2.默认绑定 ...
- 系统警告,Bronya请求支援(两遍最短路)
系统警告,Bronya请求支援 Description 休伯利安号的一行人来到了由逆熵镇守的前文明遗迹[海渊城],他们准备用巨大的传送装置[海渊之眼]进入量子之海,寻找丢失的渴望宝石.然而在行动前夜爱 ...
- 从谷歌 GFS 架构设计聊开去
伟人说:“人多力量大.” 尼古拉斯赵四说:“没有什么事,是一顿饭解决不了的!!!如果有,那就两顿.” 研发说:“需求太多,人手不够.” 专家说:“人手不够,那就协调资源,攒人头.” 释义:一人拾柴火不 ...
- Golang入门(2):一天学完GO的基本语法
摘要 在配置好环境之后,要研究的就是这个语言的语法了.在这篇文章中,作者希望可以简单的介绍一下Golang的各种语法,并与C和Java作一些简单的对比以加深记忆.因为这篇文章只是入门Golang的第二 ...