使用 python 查看谁没有交作业
话说实验报告每天都要查人数,何不用程序实现
使用 python 查看谁没有交作业
version 1.0
程序嘛,肯定是可以改进的。使用该程序的前提是实验报告文件名中包含学号信息。将以上程序放在实验报告所在目录,双击即可显示谁没交。
程序大致的流程是:
1、将本班学号姓名数据放在字典中
2、使用正则过滤出包含有学号数据的有效文档名放在列表中
3、正则提取有效列表名中的学号与标准字典对比
4、对比出的差值就是没有交作业的
import os
import re
#定义学号姓名标准字典
namedata = {*这里用来放置'学号':'姓名'字典数据*}
#定义当前文件夹下文件数
filenum_original = -1
#定义当前文件夹下文档数
filenum_doc = 0
#定义当前文件夹下有效文档数
filenum_validated = 0
#定义未找到学号人数
filenum_notfound = 0
#定义所有文档列表
filelist_doc = []
#定义有效文档列表
filelist_validated = []
#定义有效文档学号列表
filelist_sno = []
#定义未找到学号列表
filelist_notfound = []
#进行获取当前文件夹下文档列表
print("当前在 %s 目录下\n"%os.getcwd())
filelist_original = os.listdir()
for item in filelist_original:
filenum_original += 1
print("当前文件夹下--文件数--是:",filenum_original)
for item in filelist_original:
if re.match(".+(\.doc|\.docx)",item):
filelist_doc.append(item)
filenum_doc += 1
print("当前文件夹下--文档数--是:",filenum_doc)
#下面这个 for 循环同时获取了学号列表
for item in filelist_doc:
#这里用来查找文件名中10位数字的学号
result = re.search("(18\d{8})",item)
if result:
filelist_validated.append(item)
filelist_sno.append(result.group(1))
filenum_validated += 1
print("文件夹下--有效文档数--是:",filenum_validated,"\n")
#将得到的数据与标准字典进行对比
for item in namedata.keys():
if item in filelist_sno:
pass
else:
filenum_notfound += 1
filelist_notfound.append(namedata[item])
#输出结果
print("本班*这里根据实际情况填写*人,共计 %d 人没有交实验报告"%filenum_notfound,end=",")
print("他们分别是:\n")
num = 0
for item in filelist_notfound:
num +=1
print(item,end="\t")
#每 5 个名字换一行
if num % 5 == 0:
print("")
#实现输出完结果停留在当前页面
key = input("\n\n按回车键继续")
进阶版,支持多个班级和自定义
如果程序只支持一个班级的话,好用是好用,就是有点鸡肋。现在将其扩展一下,程序内置数据支持多个班级。
后来想想,即使支持了多个班级,也都是硬编码到了程序里面,是写死的。依然会有一些不便。那好,咱干脆同时支持手动扩展得了。使用外置文件进行添加数据扩展,程序运行时读取数据进行增删。当然,程序稍做改动还可实现白名单的功能,就是不管其交没交都不在结果中显示他
version 1.2
import os
import re
# 定义当前文件夹下文件数
filenum_original = 0
# 定义当前文件夹下word文档数
filenum_doc = 0
# 定义当前文件夹下有效word文档数
filenum_validated = 0
# 定义未找到学号人数
filenum_notfound = 0
# 定义所有文档列表
filelist_doc = []
# 定义有效文档列表
filelist_validated = []
# 定义有效文档学号列表
filelist_sno = []
# 定义未找到学号列表
filelist_notfound = []
# 定义找到学号列表
filelist_found = []
# 定义学号姓名标准字典
sjkx171 = { **这里放置学号数据** }
sjkx172 = { **这里放置学号数据** }
sjkx181 = { **这里放置学号数据** }
sjkx182 = { **这里放置学号数据** }
sjkx191 = { **这里放置学号数据** }
sjkx192 = { **这里放置学号数据** }
# 将班级字典放在列表中以遍历
class17 = {'数据科学171':sjkx171,'数据科学172':sjkx172}
class18 = {'数据科学181':sjkx181,'数据科学181':sjkx182}
class19 = {'数据科学191':sjkx191,'数据科学192':sjkx192}
# 定义临时班级字典
tempClass = {}
# 定义临时班级已交实验报告学号列表
tempClassSno_found = []
# 定义临时班级未交实验报告学号列表
tempClassSno_notfound = []
# 文档学号-班级全检索模式下使用的班级名列表
fullsearchlist = []
# 全检索模式下用于去重的集合
# fullsearchset = set()
# 函数欢迎信息输出
def printInfo():
i = 0
print("\n\t欢迎使用<点我查看谁没交实验报告>程序v1.2")
print("\t当前程序更新时间:2019年12月06日")
#print("\t作者:我不是高材生")
print("\t当前已支持统计实验报告的班级如下:\n\n")
for item in (class17,class18,class19):
for name in item.keys():
print(name,end = " \t")
i += 1
if i % 4 == 0:
print("")
print("\n\n>>>如程序内置数据缺失某人,")
print(">>>将其'姓名学号'添加至程序同目录下'checklist.txt'文件内即可。")
print(">>>每行一条数据,形如'李大钊1910203317'")
print(">>>如程序内置数据多出某人,")
print(">>>将其'0姓名学号'添加至程序同目录下'checklist.txt'文件内即可。")
print(">>>每行一条数据,形如'0李大钊1910203317'")
#函数进行获取当前文件夹下文档列表
def getFileNum():
global filenum_original
global filenum_doc
global filenum_validated
# 获取所有文件列表及个数
print("\n当前在 %s 目录下\n"%os.getcwd())
filelist_original = os.listdir()
for item in filelist_original:
filenum_original += 1
print("当前文件夹下--文件数--是:",filenum_original)
# 获取word文档列表及个数
for item in filelist_original:
if re.match(".+(\.doc|\.docx)",item):
filelist_doc.append(item)
filenum_doc += 1
print("当前文件夹下--文档数--是:",filenum_doc)
#下面这个 for 循环用于识别有效文档同时获取学号列表
for item in filelist_doc:
result = re.search("((1|2)\d{9})",item)
if result:
filelist_validated.append(item)
filelist_sno.append(result.group(1))
filenum_validated += 1
print("文件夹下--有效文档数--是:",filenum_validated,"\n")
# 函数读取checklist.txt文件
def readCheck():
try:
with open("checklist.txt","r") as file:
checkdata = file.readlines()
checkdata_length = len(checkdata)
print("\n>>>checklist.txt 文件已识别,共%d行,有效数据如下:\n"%(checkdata_length))
# checklist.txt 文件数据识别算法
if checkdata:
for item in checkdata:
# 检查如果是注释,就直接跳过
# comment = 0
if (item.strip()[0] == "#") or (item.strip()[0:2] == "//"):
# comment += 1
continue
# 正则识别1或2开头的10位学号
checkdata_line = re.search("(.+)((1|2)\d{9})",item)
# 如果有某行格式匹配失败则跳过
try:
check_name = checkdata_line.group(1).strip()
check_sno = checkdata_line.group(2)
# 调用识别班级函数获取班级名
confirmedClassName = confirmClass(check_sno)
# 文件导入数据添加删除算法(如果程序内没匹配到数据,则放入新列表)
if confirmedClassName == "没找到班级":
if item.strip()[0] == "0":
print("\t\t%s\t%s 不在程序内,无需删除"%(check_name[1:],check_sno))
else:
if check_name:
tempClass[check_sno] = check_name
print("%s\t%s\t%s 已添加"%("临时班级999",check_name,check_sno))
else:
print("\t\t必须要有名字,%s 添加失败"%check_sno)
else:
for classitem in (class17,class18,class19):
if confirmedClassName in classitem.keys():
if item.strip()[0] == "0":
del classitem[confirmedClassName][check_sno]
print("%s\t%s\t%s 已删除"%(confirmedClassName,check_name[1:],check_sno))
else:
classitem[confirmedClassName][check_sno] = check_name
print("%s\t%s\t%s 已更新"%(confirmedClassName,check_name,check_sno))
except:
#print("本行数据无效")
pass
else:
print("但checklist.txt文件为空,没有数据被添加")
except:
print("\nchecklist.txt文件识别失败或不存在")
print("没有额外数据被添加进程序")
# 进行检查实验报告上交情况
def check_doc():
# global fullsearchset
# 检索所有出现的班级,并去重
for item in filelist_sno:
fullsearchlist.append(confirmClass(item))
try:
fullsearchlist.remove("没找到班级")
except:
pass
fullsearchset = set(fullsearchlist)
for item in fullsearchset:
filelist_found = []
filelist_notfound = []
# 检查已有班级的实验报告上交情况
for classitem in (class17,class18,class19):
if item in classitem.keys():
for checksno in classitem[item].keys():
if checksno in filelist_sno:
filelist_found.append(checksno)
else:
filelist_notfound.append(checksno)
# 输出程序内置班级的交与没交情况统计(此算法有问题)
print("\n\n>>>已检索到:",item)
if len(filelist_found) > len(filelist_notfound):
for item1 in (class17,class18,class19):
if item in item1.keys():
i = 0
print(">>>@还有 %d 人没有交,他们分别是:\n"%len(filelist_notfound))
for item2 in filelist_notfound:
try:
print(item1[item][item2],end = "\t")
i += 1
if i%5 == 0:
print("")
except:
#print("error_2")
pass
else:
for item1 in (class17,class18,class19):
if item in item1.keys():
i = 0
if len(filelist_found) == 0:
print(">>>@还没有人交呢")
continue
print(">>>@已经交了 %d 个人,他们分别是:\n"%len(filelist_found))
for item2 in filelist_found:
try:
print(item1[item][item2],end = "\t")
i += 1
if i%5 == 0:
print("")
except:
#print("error_3")
pass
def check2():
# 检查文件导入列表中的人是否交了实验报告
for tempsno in tempClass.keys():
if tempsno in filelist_sno:
tempClassSno_found.append(tempsno)
else:
tempClassSno_notfound.append(tempsno)
# 输出附加班级的交与没交情况统计
if tempClass:
print("\n\n>>>已检索到:文件附加数据")
if (len(tempClassSno_found) < len(tempClassSno_notfound)):
i = 0
print(">>>@还有 %d 人没有交,他们分别是:\n"%len(tempClassSno_notfound))
for sno in tempClassSno_notfound:
try:
print(tempClass[sno],end = "\t")
i += 1
if i%5 == 0:
print("")
except:
print("error_1")
else:
i = 0
if tempClass:
if len(tempClassSno_found) == 0:
print(">>>@还没有人交呢")
else:
print(">>>@已经交了 %d 人,他们分别是:\n"%len(tempClassSno_found))
for sno in tempClassSno_found:
print(tempClass[sno],end = "\t")
i += 1
if i%5 == 0:
print("")
else:
pass
# 函数识别班级
def confirmClass(sno):
# 根据学号前两位来缩小遍历范围
if sno[0:2] == "17":
for key,value in class17.items():
if sno in value.keys():
return key
elif sno[0:2] == "18":
for key,value in class18.items():
if sno in value.keys():
return key
elif sno[0:2] == "19":
for key,value in class19.items():
if sno in value.keys():
return key
else:
pass
return "没找到班级"
# 主函数
def main():
printInfo()
readCheck()
getFileNum()
check_doc()
check2()
end = input("\n\n按下回车说拜拜")
if __name__ == '__main__':
main()
运行效果如下图:
(运行环境:只在配置文件中加了李大钊的数据,没有放置实验报告)
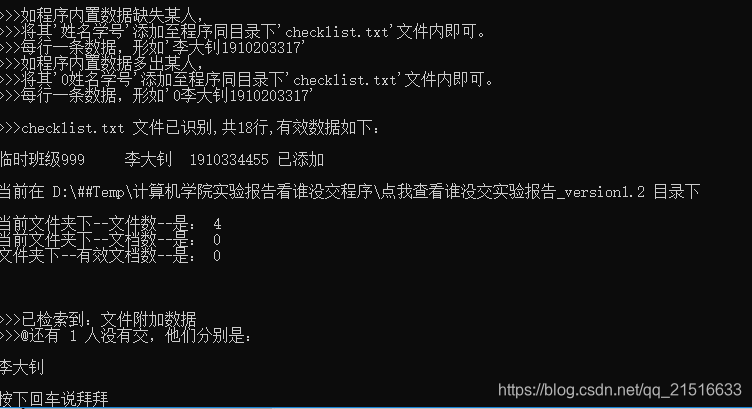
说明
程序实现了以下功能:
1、自动识别当前文件夹下有效文档所属班级,并统计本班报告上交信息。
2、交的多,显示没交的;没交的多,显示交的。
3、支持外部数据扩展,作为一个班进行统计。
4、支持白名单,配置文件checklist.txt加入姓名学号,并在行首加0即可。
程序有以下问题:
1、如果程序执行过程中遇到异常会直接跳过,并且没有提示。
2、程序仅在检测到文件名中1或2开头的10位学号才会认为文档有效。
3、程序不检测异常文件大小。
4、程序没有保存日志文件。
使用 python 查看谁没有交作业的更多相关文章
- python学习笔记(二)python基础知识(交作业)
交作业 #!/usr/bin/env python # coding: utf-8 # # 1. 每个用户购买了多少不同种类的产品 # filename = 'train.txt' import sy ...
- ThinkPHP5作业管理系统中处理学生未交作业与已交作业信息
在作业管理系统中,学生登陆到个人中心后可以通过左侧的菜单查看自己已经提交的作业和未提交作业.那么在系统中如何实现这些数据的查询的呢?首先我们需要弄清楚学生(Student).班级(class).作业提 ...
- “妈妈再也不用担心我忘交作业了!”——记2020BUAA软工团队项目选择
写在前面 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任建) 这个作业的要求在哪里 团队项目选择 项目简介 项目名称:北航学生资源整合和作业提醒平台 项目内容: 设计实现一 ...
- 2003031121——浦娟——Python数据分析第七周作业——MySQL的安装及使用
项目 要求 课程班级博客链接 20级数据班(本) 作业要求链接 Python第七周作业 博客名称 2003031121--浦娟--Python数据分析第七周作业--MySQL的安装及使用 要求 每道题 ...
- 2003031121-浦娟-python数据分析第三周作业-第一次作业
项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/pexy/20sj 作业链接 https://edu.cnblogs.com/campus/pexy/20s ...
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- BZOJ 3379: [Usaco2004 Open]Turning in Homework 交作业
Description 贝茜有C(1≤C≤1000)门科目的作业要上交,之后她要去坐巴士和奶牛同学回家. 每门科目的老师所在的教室排列在一条长为H(1≤H≤1000)的走廊上,他们只在课后接收 ...
- 一支烟的时间导致他错失女神,Python查看撤回消息,力挽狂澜!
2011年1月21日 微信(WeChat) 是腾讯公司于2011年1月21日推出的一个为智能终端提供即时通讯服务的免费应用程序,由张小龙所带领的腾讯广州研发中心产品团队打造 .在互联网飞速发展的下.民 ...
- 【转】Python——plot可视化数据,作业8
Python——plot可视化数据,作业8(python programming) subject1k和subject1v的形状相同 # -*- coding: utf-8 -*- import sc ...
随机推荐
- 5.创建app、创建user表、配置media、数据迁移
目录 user模块User表 创建user模块 创建User表对应的model:user/models.py 注册user模块,配置User表:dev.py 配置media 数据库迁移 user模块U ...
- AspNetCore3.1_Secutiry源码解析_2_Authentication_核心对象
系列文章目录 AspNetCore3.1_Secutiry源码解析_1_目录 AspNetCore3.1_Secutiry源码解析_2_Authentication_核心项目 AspNetCore3. ...
- libfastcommon总结(二)从文件中加载配置信息
头文件为ini_file_reader.h 主要接口 IniContext iniContext;//定义配置文件信息 iniLoadFromFile();//加载文件为结构化配置信息 iniG ...
- 建议11:增强数组排序的sort功能
sort方法不仅按字母顺序进行排序,还可以根据其他顺序执行操作.这时就必须为方法提供一个比较函数的参数,该函数要比较两个值,然后返回一个用于说明这两个值得相对顺序的数字.比较函数应该具有两个参数a和b ...
- Android位置服务开发
1. 使用LocationManager获取地理位置信息 代码如下: private TextView positiontext; private String provider; private L ...
- Comparing Data-Independent Acquisition and Parallel Reaction Monitoring in Their Abilities To Differentiate High-Density Lipoprotein Subclasses 比较DIA和PRM区分高密度脂蛋白亚类的能力 (解读人:陈凌云)
文献名:Comparing Data-Independent Acquisition and Parallel Reaction Monitoring in Their Abilities To Di ...
- vue 组件通讯方式到底有多少种 ?
前置 做大小 vue 项目都离不开组件通讯, 自己也收藏了很多关于 vue 组件通讯的文章. 今天自己全部试了试, 并查了文档, 在这里总结一下并全部列出, 都是简单的例子. 如有错误欢迎指正. 温馨 ...
- Layui-admin-iframe通过页面链接直接在iframe内打开一个新的页面,实现单页面的效果
前言: 使用Layui-admin做后台管理框架有很长的一段时间了,但是一直没有对框架内iframe菜单栏切换跳转做深入的了解.今天有一个这样的需求就是通过获取超链接中传递过来的跳转地址和对应的tab ...
- IDEA2019.3激活使用
IDEA2019.3激活使用 1.下载idea: https://www.jetbrains.com/idea/download/ 下载 .exe或者.Zip都可以 2. 启动:点击下载好的id ...
- 3 report formats of SFDC
Choose one of the following report formats using the Format menu of the report builder. Tabular form ...