EAST 自然场景文本检测
刚好看到国内的旷视今年在CVPR2017的一篇文章:EAST: An Efficient and Accurate Scene Text Detector。而且有开放的代码,学习和测试了下。
题目说的是比较高效,它的高效主要体现在对一些过程的消除,其架构就是下图中对应的E部分,跟上面的比起来的确少了比较多的过程。这与去年经典的CTPN架构类似。不过CTPN只支持水平方向,而EAST在论文中指出是可以支持多方向文本的定位的。
对于长文本效果不好。

优势:
提供了方向信息,可以检测各个方向的文本
缺点:
对较长的文本检测效果不好,感受野不够长
整体网络结构分为3个部分
(1) 特征提取层:
使用的基础网络结构是PVANet,分别从stage1,stage2,stage3,stage4抽出特征,一种FPN(feature pyramid network)的思想。
(2) 特征融合层:
第一步抽出的特征层从后向前做上采样,然后concat
(3) 输出层:
输出一个score map和4个回归的框+1个角度信息,或者输出,一个scoremap和8个坐标信息。
由于程序实现使用的基础网络不是pvanet网络,而是resnet50-v1。
在caffe版本的resnet50实现中,只有第一个卷积后面的pooling和最后一层的gloabl pooling,详细结构见reference,网络通过卷积层的stride=2操作实现类似pooling的效果
而本程序使用的slim中带的resnet50包含了5个pooling。
Resnet50结构,最后一个featuremap本质上将输入图像缩小16倍(4个pooling),最后一个gloabl pooling,类似于vgg中的全连接。gloabl pooling是googlenet和Resnet的专利。
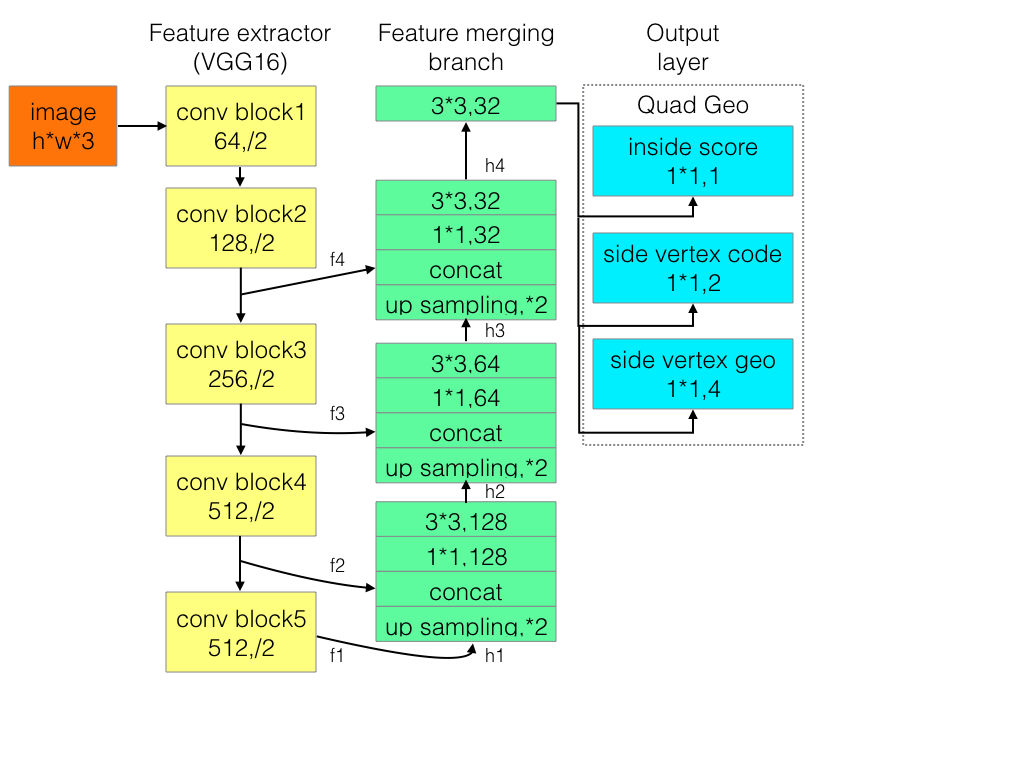
本文网络结构主要取了pool2,pool3,pool4,pool5,的featuremap引出,分别进行uppooling,concat,conv操作,得到最终的featuremap,然后进行卷积,分别输出channel=1的F_score
,channel=4的geo_map,channel=1的angle_map。
标签生成过程:
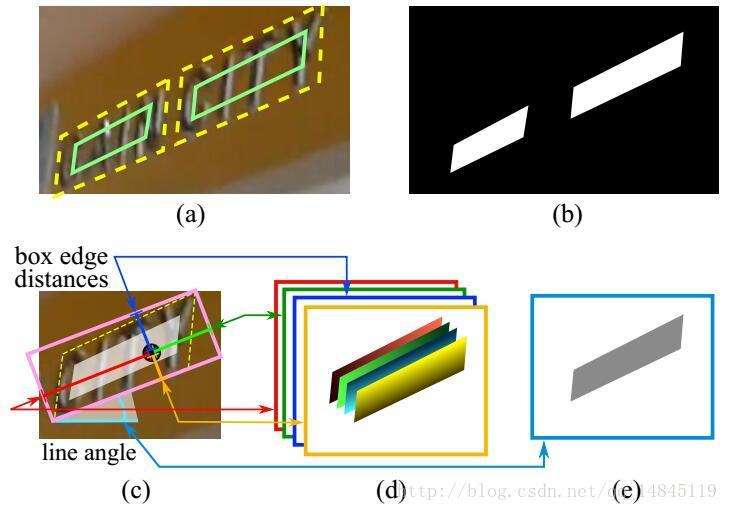
(a) 中黄色的为人工标注的框,绿色为对黄色框进行0.3倍边长的缩放后的框,这样做可以进一步去除人工标注的误差,拿到更准确的label信息。
(b) 为根据(a)中绿色框生成的label信息
(c) 中先生成一个(b)中白色区域的最小外接矩,然后算每一个(b)中白色的点到粉色最小外接矩的上下左右边的距离,即生成(d),然后生成粉色的矩形和水平方向的夹角,即生成角度信息(e),e中所有灰色部分的角度信息一样,都是同样的角度。
论文采用的架构如下:

后来,有大佬改进EAST针对长文本检测效果不好的缺陷,提出advancedEAST,结构如下:
开源源码:https://github.com/huoyijie/AdvancedEAST
仅为学习记录,侵删,感谢作者。
EAST 自然场景文本检测的更多相关文章
- 【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
文字识别分为两个具体步骤:文字的检测和文字的识别,两者缺一不可,尤其是文字检测,是识别的前提条件,若文字都找不到,那何谈文字识别.今天我们首先来谈一下当今流行的文字检测技术有哪些. 文本检测不是一件简 ...
- Scene Text Detection(场景文本检测)论文思路总结
任意角度的场景文本检测论文思路总结共同点:重新添加分支的创新更突出场景文本检测基于分割的检测方法 spcnet(mask_rcnn+tcm+rescore) psenet(渐进扩展) mask tex ...
- 使用Keras基于AdvancedEAST的场景图像文本检测
Blog:https://blog.csdn.net/linchuhai/article/details/84677249 GitHub:https://github.com/huoyijie/Adv ...
- OCR场景文本识别:文字检测+文字识别
一. 应用背景 OCR(Optical Character Recognition)文字识别技术的应用领域主要包括:证件识别.车牌识别.智慧医疗.pdf文档转换为Word.拍照识别.截图识别.网络图片 ...
- Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network(利用像素聚合网络进行高效准确的任意形状文本检测)
PSENet V2昨日刚出,今天翻译学习一下. 场景文本检测是场景文本阅读系统的重要一步,随着卷积神经网络的快速发展,场景文字检测也取得了巨大的进步.尽管如此,仍存在两个主要挑战,它们阻碍文字检测部署 ...
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- OpenCV_contrib里的Text(自然场景图像中的文本检测与识别)
平台:win10 x64 +VS 2015专业版 +opencv-3.x.+CMake 待解决!!!Issue说明:最近做一些字符识别的事情,想试一下opencv_contrib里的Text(自然场景 ...
- 应用笔画宽度变换(SWT)来检测自然场景中的文本
Introduction: 应用背景:是盲人辅助系统,城市环境中的机器导航等计算机视觉系统应用的重要一步.获取文本能够为许多视觉任务提供上下文的线索,并且,图像检索算法的性能很大部分都依赖于对应的文本 ...
- 使用Python基于VGG/CTPN/CRNN的自然场景文字方向检测/区域检测/不定长OCR识别
GitHub:https://github.com/pengcao/chinese_ocr https://github.com/xiaofengShi/CHINESE-OCR |-angle 基于V ...
随机推荐
- sql 锁类型与锁机制 转
SQL Server锁类型(SQL)收藏1. HOLDLOCK: 在该表上保持共享锁,直到整个事务结束,而不是在语句执行完立即释放所添加的锁. 2. NOLOCK:不添加共享锁和排它锁,当这个 ...
- dtrace for mysql
http://dtrace.org/blogs/brendan/2011/06/23/mysql-performance-schema-and-dtrace/
- The maximum number of processes for the user account running is currently , which can cause performance issues. We recommend increasing this to at least 4096.
[root@localhost ~]# vi /etc/security/limits.conf # /etc/security/limits.conf # #Each line describes ...
- [Todo] Java及C++ Exception整理
今天接触到一些Java Exception方面的内容,整理如下: http://developer.51cto.com/art/201111/304649.htm C++中Exception等的整理
- 加解密 3DES AES RSA 简介 示例 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- .net非托管资源的回收
释放未托管的资源有两种方法 1.析构函数 2.实现System.IDisposable接口 一.析构函数 构造函数可以指定必须在创建类的实例时进行的某些操作,在垃圾收集器删除对象时,也可以调用析构函数 ...
- (转)行为树(Behavior Tree)
转自:http://www.cnblogs.com/konlil/archive/2011/04/23/2025954.html 如果要让游戏里的角色或者NPC能执行预设的AI逻辑,最简单的用IF.. ...
- API的文件遍历,未使用CFileFind,因为里面牵扯MFC,编个DLL好麻烦。
// FindFileDebug.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include "FindFileDebug. ...
- Flutter混合工程改造实践
背景 6月下旬,我们首次尝试用Flutter开发AI拍app.开发的调研准备阶段没有参考业界实践,导致我们踩到一些填不上的坑.在这些坑中,最让我感到棘手的是Flutter和原生页面混合栈管理的问题. ...
- 算法笔记_021:广度优先查找(Java)
目录 1 问题描述 2 解决方案 2.1 蛮力法 1 问题描述 广度优先查找(Breadth-first Search,BFS)按照一种同心圆的方式,首先访问所有和初始顶点邻接的顶点,然后是离它两条边 ...